 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Update Aggregation with Recycling for Communication-Efficient Federated Learning
Mar 14, 2025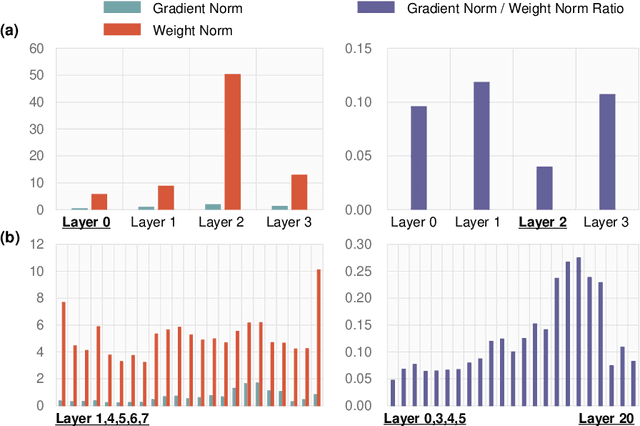

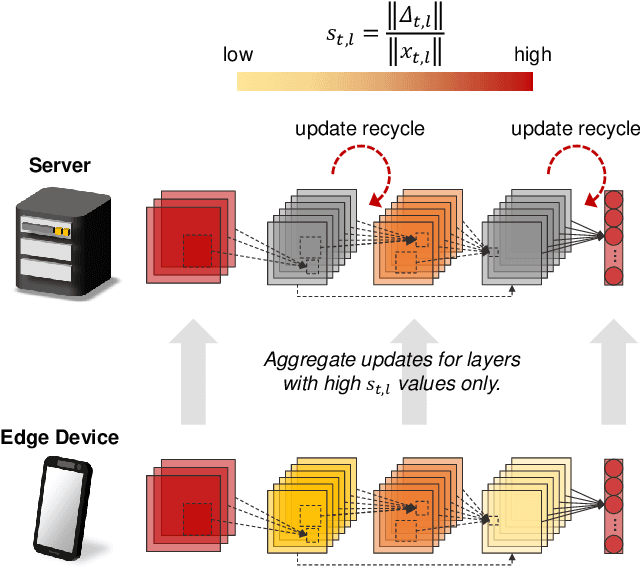
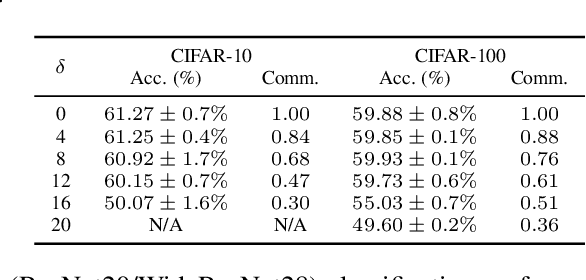
Expensive communication cost is a common performance bottleneck in Federated Learning (FL), which makes it less appealing in real-world applications. Many communication-efficient FL methods focus on discarding a part of model updates mostly based on gradient magnitude. In this study, we find that recycling previous updates, rather than simply dropping them, more effectively reduces the communication cost while maintaining FL performance. We propose FedLUAR, a Layer-wise Update Aggregation with Recycling scheme for communication-efficient FL. We first define a useful metric that quantifies the extent to which the aggregated gradients influences the model parameter values in each layer. FedLUAR selects a few layers based on the metric and recycles their previous updates on the server side. Our extensive empirical study demonstrates that the update recycling scheme significantly reduces the communication cost while maintaining model accuracy. For example, our method achieves nearly the same AG News accuracy as FedAvg, while reducing the communication cost to just 17%.
COSMosFL: Ensemble of Small Language Models for Fault Localisation
Feb 05, 2025



LLMs are rapidly being adopted to build powerful tools and agents for software engineering, but most of them rely heavily on extremely large closed-source models. This, in turn, can hinder wider adoption due to security issues as well as financial cost and environmental impact. Recently, a number of open source Small Language Models (SLMs) are being released and gaining traction. While SLMs are smaller, more energy-efficient, and therefore easier to locally deploy, they tend to show worse performance when compared to larger closed LLMs. We present COSMos, a task-level LLM ensemble technique that uses voting mechanism, to provide a broader range of choice between SLMs and LLMs. We instantiate COSMos with an LLM-based Fault Localisation technique, AutoFL, and report the cost-benefit trade-off between LLM accuracy and various costs such as energy consumption, inference time, and the number of tokens used. An empirical evaluation using Defects4J shows that COSMos can build effective ensembles that can achieve Pareto-optimality in terms of FL accuracy and inference cost, when compared to individual models.
Can We Predict the Effect of Prompts?
Jan 31, 2025



Large Language Models (LLMs) are machine learning models that have seen widespread adoption due to their capability of handling previously difficult tasks. LLMs, due to their training, are sensitive to how exactly a question is presented, also known as prompting. However, prompting well is challenging, as it has been difficult to uncover principles behind prompting -- generally, trial-and-error is the most common way of improving prompts, despite its significant computational cost. In this context, we argue it would be useful to perform `predictive prompt analysis', in which an automated technique would perform a quick analysis of a prompt and predict how the LLM would react to it, relative to a goal provided by the user. As a demonstration of the concept, we present Syntactic Prevalence Analyzer (SPA), a predictive prompt analysis approach based on sparse autoencoders (SAEs). SPA accurately predicted how often an LLM would generate target syntactic structures during code synthesis, with up to 0.994 Pearson correlation between the predicted and actual prevalence of the target structure. At the same time, SPA requires only 0.4\% of the time it takes to run the LLM on a benchmark. As LLMs are increasingly used during and integrated into modern software development, our proposed predictive prompt analysis concept has the potential to significantly ease the use of LLMs for both practitioners and researchers.
Advancing Medical Image Segmentation: Morphology-Driven Learning with Diffusion Transformer
Aug 01, 2024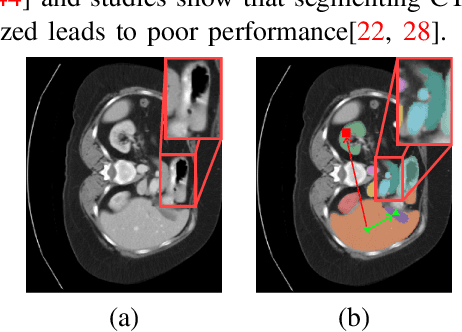

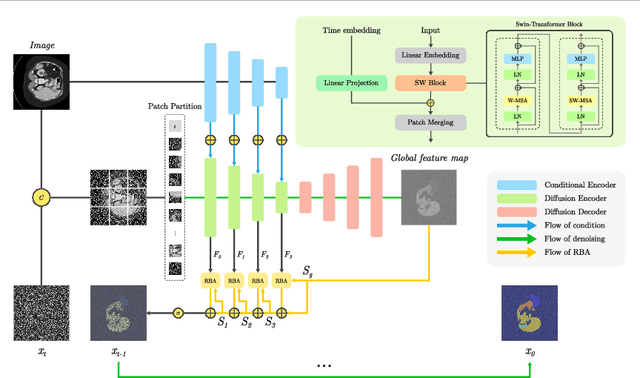
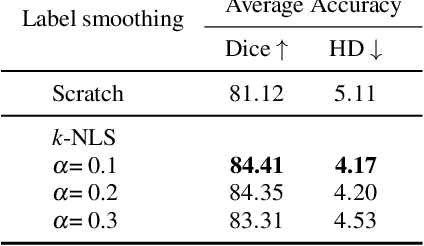
Understanding the morphological structure of medical images and precisely segmenting the region of interest or abnormality is an important task that can assist in diagnosis. However, the unique properties of medical imaging make clear segmentation difficult, and the high cost and time-consuming task of labeling leads to a coarse-grained representation of ground truth. Facing with these problems, we propose a novel Diffusion Transformer Segmentation (DTS) model for robust segmentation in the presence of noise. We propose an alternative to the dominant Denoising U-Net encoder through experiments applying a transformer architecture, which captures global dependency through self-attention. Additionally, we propose k-neighbor label smoothing, reverse boundary attention, and self-supervised learning with morphology-driven learning to improve the ability to identify complex structures. Our model, which analyzes the morphological representation of images, shows better results than the previous models in various medical imaging modalities, including CT, MRI, and lesion images.
SINVAD: Search-based Image Space Navigation for DNN Image Classifier Test Input Generation
May 19, 2020

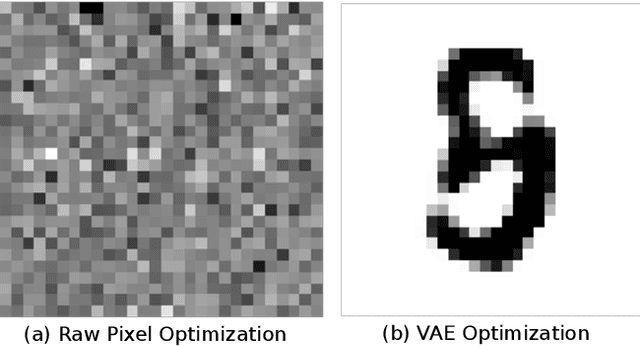

The testing of Deep Neural Networks (DNNs) has become increasingly important as DNNs are widely adopted by safety critical systems. While many test adequacy criteria have been suggested, automated test input generation for many types of DNNs remains a challenge because the raw input space is too large to randomly sample or to navigate and search for plausible inputs. Consequently, current testing techniques for DNNs depend on small local perturbations to existing inputs, based on the metamorphic testing principle. We propose new ways to search not over the entire image space, but rather over a plausible input space that resembles the true training distribution. This space is constructed using Variational Autoencoders (VAEs), and navigated through their latent vector space. We show that this space helps efficiently produce test inputs that can reveal information about the robustness of DNNs when dealing with realistic tests, opening the field to meaningful exploration through the space of highly structured images.
Search Based Repair of Deep Neural Networks
Dec 28, 2019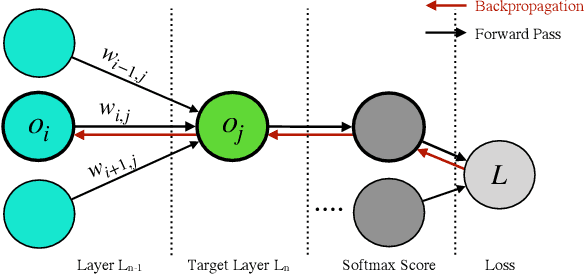
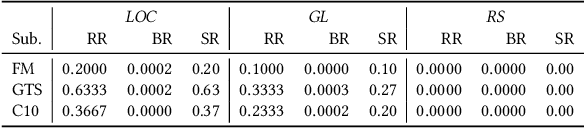
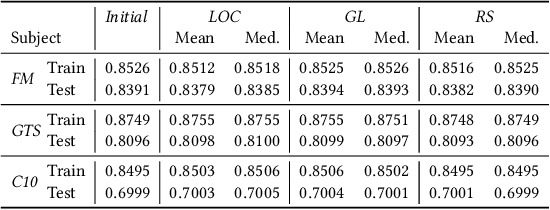

Deep Neural Networks (DNNs) are being adopted in various domains, including safety critical ones. The wide-spread adoption also calls for ways to guide the testing of their accuracy and robustness, for which various test adequacy criteria and input generation methods have been recently introduced. In this paper, we explore the natural subsequent step: given an input that reveals unexpected behaviour in a trained DNN, we propose to repair the DNN using input-output pairs as a specification. This paper introduces Arachne, a novel program repair technique for DNNs. Arachne first performs sensitivity based fault localisation to limit the number of neural weights it has to modify. Subsequently, Arachne uses Particle Swarm Optimisation (PSO) to directly optimise the localised neural weights until the behaviour is corrected. An empirical study using three different benchmark datasets shows that Arachne can reduce the instances of the most frequent misclassification type committed by a pre-trained CIFAR-10 classifier by 27.5%, without any need for additional training data. Patches generated by Arachne tend to be more focused on the targeted misbehaviour than DNN retraining, which is more disruptive to non-targeted behaviour. The overall results suggest the feasibility of patching DNNs using Arachne until they can be retrained properly.
Interpreting Models by Allowing to Ask
Nov 13, 2018


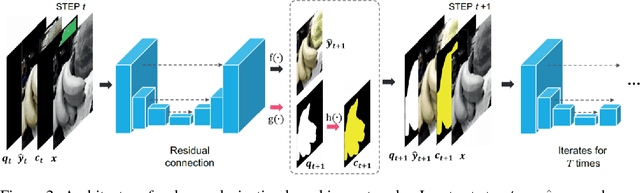
Questions convey information about the questioner, namely what one does not know. In this paper, we propose a novel approach to allow a learning agent to ask what it considers as tricky to predict, in the course of producing a final output. By analyzing when and what it asks, we can make our model more transparent and interpretable. We first develop this idea to propose a general framework of deep neural networks that can ask questions, which we call asking networks. A specific architecture and training process for an asking network is proposed for the task of colorization, which is an exemplar one-to-many task and thus a task where asking questions is helpful in performing the task accurately. Our results show that the model learns to generate meaningful questions, asks difficult questions first, and utilizes the provided hint more efficiently than baseline models. We conclude that the proposed asking framework makes the learning agent reveal its weaknesses, which poses a promising new direction in developing interpretable and interactive models.