 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Semantic Flow of ML-based Systems
Mar 13, 2025ML-based systems are software systems that incorporates machine learning components such as Deep Neural Networks (DNNs) or Large Language Models (LLMs). While such systems enable advanced features such as high performance computer vision, natural language processing, and code generation, their internal behaviour remain largely opaque to traditional dynamic analysis such as testing: existing analysis typically concern only what is observable from the outside, such as input similarity or class label changes. We propose semantic flow, a concept designed to capture the internal behaviour of ML-based system and to provide a platform for traditional dynamic analysis techniques to be adapted to. Semantic flow combines the idea of control flow with internal states taken from executions of ML-based systems, such as activation values of a specific layer in a DNN, or embeddings of LLM responses at a specific inference step of LLM agents. The resulting representation, summarised as semantic flow graphs, can capture internal decisions that are not explicitly represented in the traditional control flow of ML-based systems. We propose the idea of semantic flow, introduce two examples using a DNN and an LLM agent, and finally sketch its properties and how it can be used to adapt existing dynamic analysis techniques for use in ML-based software systems.
DANDI: Diffusion as Normative Distribution for Deep Neural Network Input
Feb 05, 2025Surprise Adequacy (SA) has been widely studied as a test adequacy metric that can effectively guide software engineers towards inputs that are more likely to reveal unexpected behaviour of Deep Neural Networks (DNNs). Intuitively, SA is an out-of-distribution metric that quantifies the dissimilarity between the given input and the training data: if a new input is very different from those seen during training, the DNN is more likely to behave unexpectedly against the input. While SA has been widely adopted as a test prioritization method, its major weakness is the fact that the computation of the metric requires access to the training dataset, which is often not allowed in real-world use cases. We present DANDI, a technique that generates a surrogate input distribution using Stable Diffusion to compute SA values without requiring the original training data. An empirical evaluation of DANDI applied to image classifiers for CIFAR10 and ImageNet-1K shows that SA values computed against synthetic data are highly correlated with the values computed against the training data, with Spearman Rank correlation value of 0.852 for ImageNet-1K and 0.881 for CIFAR-10. Further, we show that SA value computed by DANDI achieves can prioritize inputs as effectively as those computed using the training data, when testing DNN models mutated by DeepMutation. We believe that DANDI can significantly improve the usability of SA for practical DNN testing.
COSMosFL: Ensemble of Small Language Models for Fault Localisation
Feb 05, 2025



LLMs are rapidly being adopted to build powerful tools and agents for software engineering, but most of them rely heavily on extremely large closed-source models. This, in turn, can hinder wider adoption due to security issues as well as financial cost and environmental impact. Recently, a number of open source Small Language Models (SLMs) are being released and gaining traction. While SLMs are smaller, more energy-efficient, and therefore easier to locally deploy, they tend to show worse performance when compared to larger closed LLMs. We present COSMos, a task-level LLM ensemble technique that uses voting mechanism, to provide a broader range of choice between SLMs and LLMs. We instantiate COSMos with an LLM-based Fault Localisation technique, AutoFL, and report the cost-benefit trade-off between LLM accuracy and various costs such as energy consumption, inference time, and the number of tokens used. An empirical evaluation using Defects4J shows that COSMos can build effective ensembles that can achieve Pareto-optimality in terms of FL accuracy and inference cost, when compared to individual models.
Can We Predict the Effect of Prompts?
Jan 31, 2025



Large Language Models (LLMs) are machine learning models that have seen widespread adoption due to their capability of handling previously difficult tasks. LLMs, due to their training, are sensitive to how exactly a question is presented, also known as prompting. However, prompting well is challenging, as it has been difficult to uncover principles behind prompting -- generally, trial-and-error is the most common way of improving prompts, despite its significant computational cost. In this context, we argue it would be useful to perform `predictive prompt analysis', in which an automated technique would perform a quick analysis of a prompt and predict how the LLM would react to it, relative to a goal provided by the user. As a demonstration of the concept, we present Syntactic Prevalence Analyzer (SPA), a predictive prompt analysis approach based on sparse autoencoders (SAEs). SPA accurately predicted how often an LLM would generate target syntactic structures during code synthesis, with up to 0.994 Pearson correlation between the predicted and actual prevalence of the target structure. At the same time, SPA requires only 0.4\% of the time it takes to run the LLM on a benchmark. As LLMs are increasingly used during and integrated into modern software development, our proposed predictive prompt analysis concept has the potential to significantly ease the use of LLMs for both practitioners and researchers.
Real Faults in Deep Learning Fault Benchmarks: How Real Are They?
Dec 20, 2024



As the adoption of Deep Learning (DL) systems continues to rise, an increasing number of approaches are being proposed to test these systems, localise faults within them, and repair those faults. The best attestation of effectiveness for such techniques is an evaluation that showcases their capability to detect, localise and fix real faults. To facilitate these evaluations, the research community has collected multiple benchmarks of real faults in DL systems. In this work, we perform a manual analysis of 490 faults from five different benchmarks and identify that 314 of them are eligible for our study. Our investigation focuses specifically on how well the bugs correspond to the sources they were extracted from, which fault types are represented, and whether the bugs are reproducible. Our findings indicate that only 18.5% of the faults satisfy our realism conditions. Our attempts to reproduce these faults were successful only in 52% of cases.
An Empirical Study of Fault Localisation Techniques for Deep Learning
Dec 17, 2024With the increased popularity of Deep Neural Networks (DNNs), increases also the need for tools to assist developers in the DNN implementation, testing and debugging process. Several approaches have been proposed that automatically analyse and localise potential faults in DNNs under test. In this work, we evaluate and compare existing state-of-the-art fault localisation techniques, which operate based on both dynamic and static analysis of the DNN. The evaluation is performed on a benchmark consisting of both real faults obtained from bug reporting platforms and faulty models produced by a mutation tool. Our findings indicate that the usage of a single, specific ground truth (e.g., the human defined one) for the evaluation of DNN fault localisation tools results in pretty low performance (maximum average recall of 0.31 and precision of 0.23). However, such figures increase when considering alternative, equivalent patches that exist for a given faulty DNN. Results indicate that \dfd is the most effective tool, achieving an average recall of 0.61 and precision of 0.41 on our benchmark.
CSA-Trans: Code Structure Aware Transformer for AST
Apr 07, 2024When applying the Transformer architecture to source code, designing a good self-attention mechanism is critical as it affects how node relationship is extracted from the Abstract Syntax Trees (ASTs) of the source code. We present Code Structure Aware Transformer (CSA-Trans), which uses Code Structure Embedder (CSE) to generate specific PE for each node in AST. CSE generates node Positional Encoding (PE) using disentangled attention. To further extend the self-attention capability, we adopt Stochastic Block Model (SBM) attention. Our evaluation shows that our PE captures the relationships between AST nodes better than other graph-related PE techniques. We also show through quantitative and qualitative analysis that SBM attention is able to generate more node specific attention coefficients. We demonstrate that CSA-Trans outperforms 14 baselines in code summarization tasks for both Python and Java, while being 41.92% faster and 25.31% memory efficient in Java dataset compared to AST-Trans and SG-Trans respectively.
Autonomous Large Language Model Agents Enabling Intent-Driven Mobile GUI Testing
Nov 15, 2023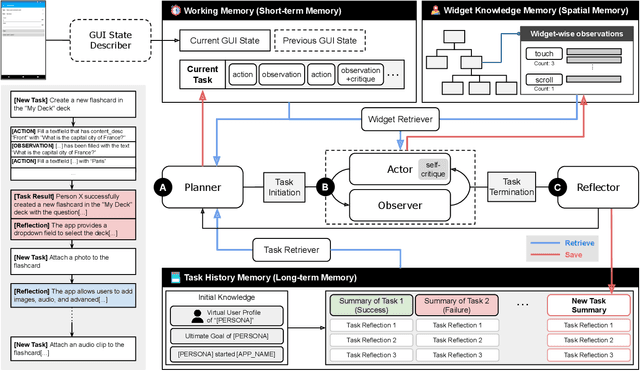



GUI testing checks if a software system behaves as expected when users interact with its graphical interface, e.g., testing specific functionality or validating relevant use case scenarios. Currently, deciding what to test at this high level is a manual task since automated GUI testing tools target lower level adequacy metrics such as structural code coverage or activity coverage. We propose DroidAgent, an autonomous GUI testing agent for Android, for semantic, intent-driven automation of GUI testing. It is based on Large Language Models and support mechanisms such as long- and short-term memory. Given an Android app, DroidAgent sets relevant task goals and subsequently tries to achieve them by interacting with the app. Our empirical evaluation of DroidAgent using 15 apps from the Themis benchmark shows that it can set up and perform realistic tasks, with a higher level of autonomy. For example, when testing a messaging app, DroidAgent created a second account and added a first account as a friend, testing a realistic use case, without human intervention. On average, DroidAgent achieved 61% activity coverage, compared to 51% for current state-of-the-art GUI testing techniques. Further, manual analysis shows that 317 out of the 374 autonomously created tasks are realistic and relevant to app functionalities, and also that DroidAgent interacts deeply with the apps and covers more features.
Genetic Improvement @ ICSE 2020
Jul 31, 2020

Following Prof. Mark Harman of Facebook's keynote and formal presentations (which are recorded in the proceedings) there was a wide ranging discussion at the eighth international Genetic Improvement workshop, GI-2020 @ ICSE (held as part of the 42nd ACM/IEEE International Conference on Software Engineering on Friday 3rd July 2020). Topics included industry take up, human factors, explainabiloity (explainability, justifyability, exploitability) and GI benchmarks. We also contrast various recent online approaches (e.g. SBST 2020) to holding virtual computer science conferences and workshops via the WWW on the Internet without face-2-face interaction. Finally we speculate on how the Coronavirus Covid-19 Pandemic will affect research next year and into the future.
Reducing DNN Labelling Cost using Surprise Adequacy: An Industrial Case Study for Autonomous Driving
May 29, 2020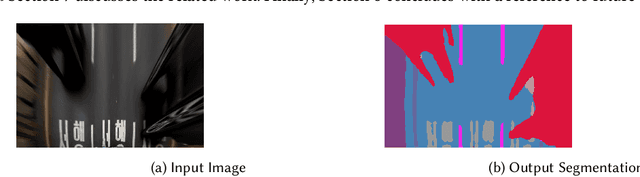
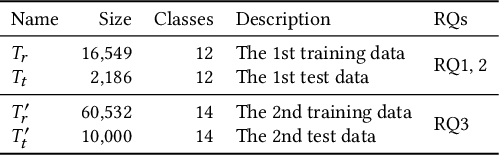
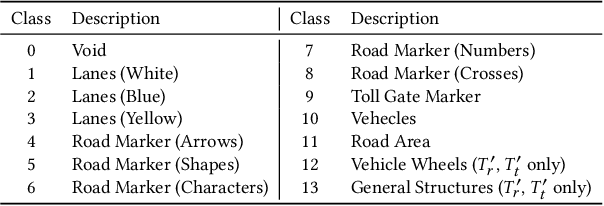
Deep Neural Networks (DNNs) are rapidly being adopted by the automotive industry, due to their impressive performance in tasks that are essential for autonomous driving. Object segmentation is one such task: its aim is to precisely locate boundaries of objects and classify the identified objects, helping autonomous cars to recognise the road environment and the traffic situation. Not only is this task safety critical, but developing a DNN based object segmentation module presents a set of challenges that are significantly different from traditional development of safety critical software. The development process in use consists of multiple iterations of data collection, labelling, training, and evaluation. Among these stages, training and evaluation are computation intensive while data collection and labelling are manual labour intensive. This paper shows how development of DNN based object segmentation can be improved by exploiting the correlation between Surprise Adequacy (SA) and model performance. The correlation allows us to predict model performance for inputs without manually labelling them. This, in turn, enables understanding of model performance, more guided data collection, and informed decisions about further training. In our industrial case study the technique allows cost savings of up to 50% with negligible evaluation inaccuracy. Furthermore, engineers can trade off cost savings versus the tolerable level of inaccuracy depending on different development phases and scenarios.