 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Genetic Improvement Mutations Using Large Language Models
Oct 18, 2023Large language models (LLMs) have been successfully applied to software engineering tasks, including program repair. However, their application in search-based techniques such as Genetic Improvement (GI) is still largely unexplored. In this paper, we evaluate the use of LLMs as mutation operators for GI to improve the search process. We expand the Gin Java GI toolkit to call OpenAI's API to generate edits for the JCodec tool. We randomly sample the space of edits using 5 different edit types. We find that the number of patches passing unit tests is up to 75% higher with LLM-based edits than with standard Insert edits. Further, we observe that the patches found with LLMs are generally less diverse compared to standard edits. We ran GI with local search to find runtime improvements. Although many improving patches are found by LLM-enhanced GI, the best improving patch was found by standard GI.
GI Software with fewer Data Cache Misses
Apr 06, 2023By their very name caches are often overlooked and yet play a vital role in the performance of modern and indeed future hardware. Using MAGPIE (Machine Automated General Performance Improvement via Evolution of software) we show genetic improvement GI can reduce the cache load of existing computer programs. Operating on lines of C and C++ source code using local search, Magpie can generate new functionally equivalent variants which generate fewer L1 data cache misses. Cache miss reduction is tested on two industrial open source programs (Google's Open Location Code OLC and Uber's Hexagonal Hierarchical Spatial Index H3) and two 2D photograph image processing tasks, counting pixels and OpenCV's SEEDS segmentation algorithm. Magpie's patches functionally generalise. In one case they reduce data misses on the highest performance L1 cache dramatically by 47 percent.
MAGPIE: Machine Automated General Performance Improvement via Evolution of Software
Aug 04, 2022
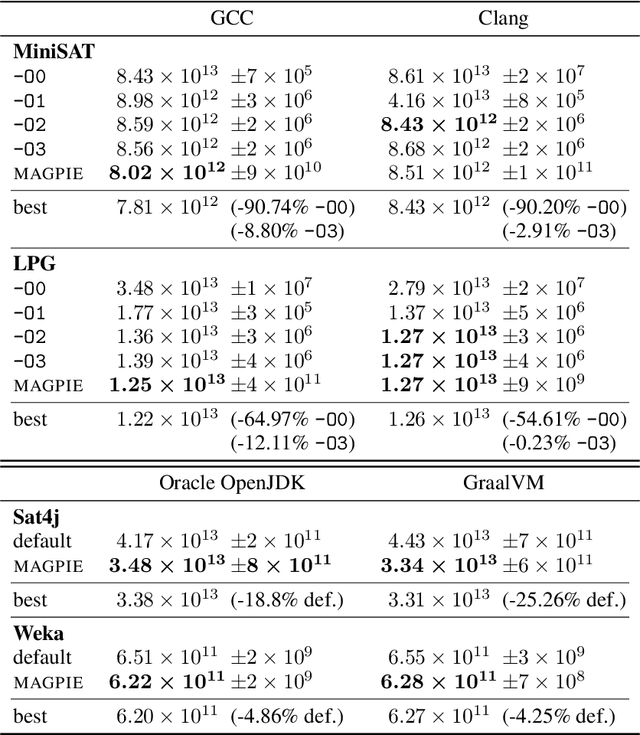
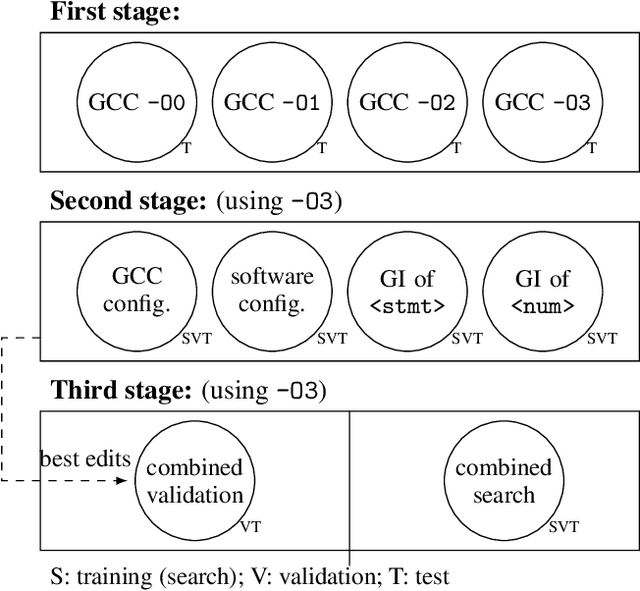

Performance is one of the most important qualities of software. Several techniques have thus been proposed to improve it, such as program transformations, optimisation of software parameters, or compiler flags. Many automated software improvement approaches use similar search strategies to explore the space of possible improvements, yet available tooling only focuses on one approach at a time. This makes comparisons and exploration of interactions of the various types of improvement impractical. We propose MAGPIE, a unified software improvement framework. It provides a common edit sequence based representation that isolates the search process from the specific improvement technique, enabling a much simplified synergistic workflow. We provide a case study using a basic local search to compare compiler optimisation, algorithm configuration, and genetic improvement. We chose running time as our efficiency measure and evaluated our approach on four real-world software, written in C, C++, and Java. Our results show that, used independently, all techniques find significant running time improvements: up to 25% for compiler optimisation, 97% for algorithm configuration, and 61% for evolving source code using genetic improvement. We also show that up to 10% further increase in performance can be obtained with partial combinations of the variants found by the different techniques. Furthermore, the common representation also enables simultaneous exploration of all techniques, providing a competitive alternative to using each technique individually.
Genetic Improvement @ ICSE 2020
Jul 31, 2020

Following Prof. Mark Harman of Facebook's keynote and formal presentations (which are recorded in the proceedings) there was a wide ranging discussion at the eighth international Genetic Improvement workshop, GI-2020 @ ICSE (held as part of the 42nd ACM/IEEE International Conference on Software Engineering on Friday 3rd July 2020). Topics included industry take up, human factors, explainabiloity (explainability, justifyability, exploitability) and GI benchmarks. We also contrast various recent online approaches (e.g. SBST 2020) to holding virtual computer science conferences and workshops via the WWW on the Internet without face-2-face interaction. Finally we speculate on how the Coronavirus Covid-19 Pandemic will affect research next year and into the future.
Local Consistency and SAT-Solvers
Jan 18, 2014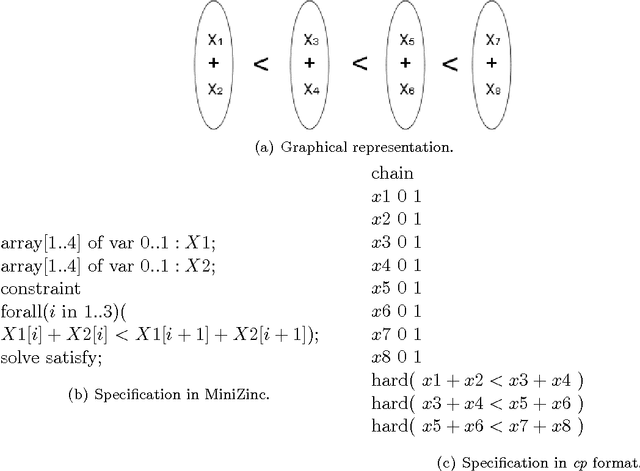



Local consistency techniques such as k-consistency are a key component of specialised solvers for constraint satisfaction problems. In this paper we show that the power of using k-consistency techniques on a constraint satisfaction problem is precisely captured by using a particular inference rule, which we call negative-hyper-resolution, on the standard direct encoding of the problem into Boolean clauses. We also show that current clause-learning SAT-solvers will discover in expected polynomial time any inconsistency that can be deduced from a given set of clauses using negative-hyper-resolvents of a fixed size. We combine these two results to show that, without being explicitly designed to do so, current clause-learning SAT-solvers efficiently simulate k-consistency techniques, for all fixed values of k. We then give some experimental results to show that this feature allows clause-learning SAT-solvers to efficiently solve certain families of constraint problems which are challenging for conventional constraint-programming solvers.