 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring LLM-Driven Explanations for Quantum Algorithms
Sep 26, 2024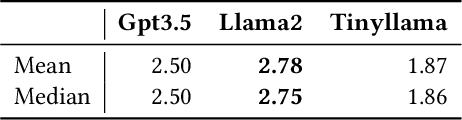
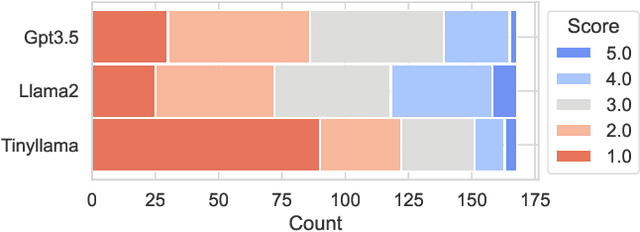
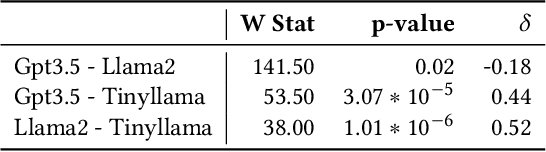
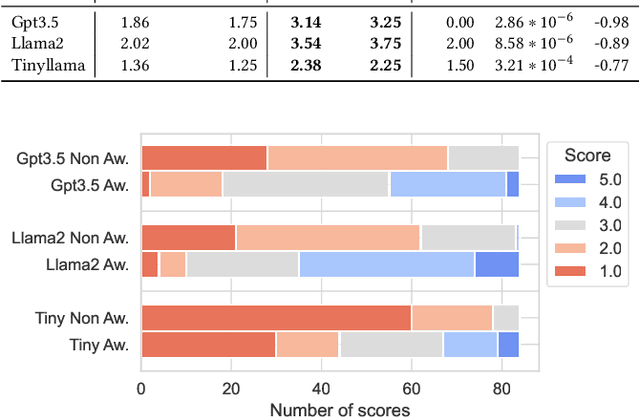
Background: Quantum computing is a rapidly growing new programming paradigm that brings significant changes to the design and implementation of algorithms. Understanding quantum algorithms requires knowledge of physics and mathematics, which can be challenging for software developers. Aims: In this work, we provide a first analysis of how LLMs can support developers' understanding of quantum code. Method: We empirically analyse and compare the quality of explanations provided by three widely adopted LLMs (Gpt3.5, Llama2, and Tinyllama) using two different human-written prompt styles for seven state-of-the-art quantum algorithms. We also analyse how consistent LLM explanations are over multiple rounds and how LLMs can improve existing descriptions of quantum algorithms. Results: Llama2 provides the highest quality explanations from scratch, while Gpt3.5 emerged as the LLM best suited to improve existing explanations. In addition, we show that adding a small amount of context to the prompt significantly improves the quality of explanations. Finally, we observe how explanations are qualitatively and syntactically consistent over multiple rounds. Conclusions: This work highlights promising results, and opens challenges for future research in the field of LLMs for quantum code explanation. Future work includes refining the methods through prompt optimisation and parsing of quantum code explanations, as well as carrying out a systematic assessment of the quality of explanations.
Enhancing Genetic Improvement Mutations Using Large Language Models
Oct 18, 2023Large language models (LLMs) have been successfully applied to software engineering tasks, including program repair. However, their application in search-based techniques such as Genetic Improvement (GI) is still largely unexplored. In this paper, we evaluate the use of LLMs as mutation operators for GI to improve the search process. We expand the Gin Java GI toolkit to call OpenAI's API to generate edits for the JCodec tool. We randomly sample the space of edits using 5 different edit types. We find that the number of patches passing unit tests is up to 75% higher with LLM-based edits than with standard Insert edits. Further, we observe that the patches found with LLMs are generally less diverse compared to standard edits. We ran GI with local search to find runtime improvements. Although many improving patches are found by LLM-enhanced GI, the best improving patch was found by standard GI.