 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning
Nov 30, 2024



Machine learning based surrogate models offer researchers powerful tools for accelerating simulation-based workflows. However, as standard datasets in this space often cover small classes of physical behavior, it can be difficult to evaluate the efficacy of new approaches. To address this gap, we introduce the Well: a large-scale collection of datasets containing numerical simulations of a wide variety of spatiotemporal physical systems. The Well draws from domain experts and numerical software developers to provide 15TB of data across 16 datasets covering diverse domains such as biological systems, fluid dynamics, acoustic scattering, as well as magneto-hydrodynamic simulations of extra-galactic fluids or supernova explosions. These datasets can be used individually or as part of a broader benchmark suite. To facilitate usage of the Well, we provide a unified PyTorch interface for training and evaluating models. We demonstrate the function of this library by introducing example baselines that highlight the new challenges posed by the complex dynamics of the Well. The code and data is available at https://github.com/PolymathicAI/the_well.
Exploring LLM-Driven Explanations for Quantum Algorithms
Sep 26, 2024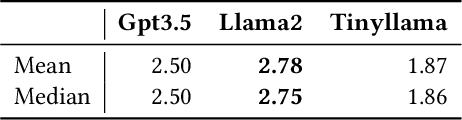
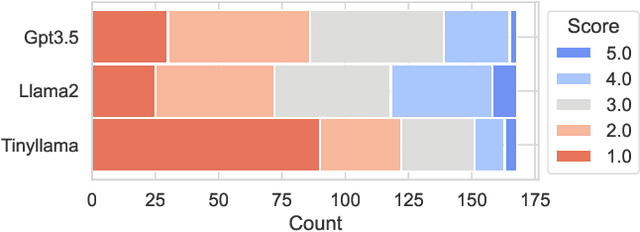
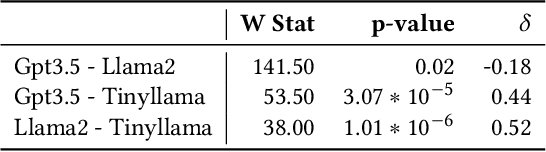
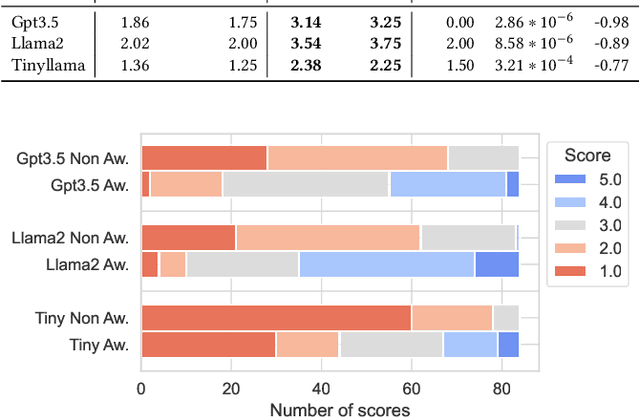
Background: Quantum computing is a rapidly growing new programming paradigm that brings significant changes to the design and implementation of algorithms. Understanding quantum algorithms requires knowledge of physics and mathematics, which can be challenging for software developers. Aims: In this work, we provide a first analysis of how LLMs can support developers' understanding of quantum code. Method: We empirically analyse and compare the quality of explanations provided by three widely adopted LLMs (Gpt3.5, Llama2, and Tinyllama) using two different human-written prompt styles for seven state-of-the-art quantum algorithms. We also analyse how consistent LLM explanations are over multiple rounds and how LLMs can improve existing descriptions of quantum algorithms. Results: Llama2 provides the highest quality explanations from scratch, while Gpt3.5 emerged as the LLM best suited to improve existing explanations. In addition, we show that adding a small amount of context to the prompt significantly improves the quality of explanations. Finally, we observe how explanations are qualitatively and syntactically consistent over multiple rounds. Conclusions: This work highlights promising results, and opens challenges for future research in the field of LLMs for quantum code explanation. Future work includes refining the methods through prompt optimisation and parsing of quantum code explanations, as well as carrying out a systematic assessment of the quality of explanations.