 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning
Nov 30, 2024



Machine learning based surrogate models offer researchers powerful tools for accelerating simulation-based workflows. However, as standard datasets in this space often cover small classes of physical behavior, it can be difficult to evaluate the efficacy of new approaches. To address this gap, we introduce the Well: a large-scale collection of datasets containing numerical simulations of a wide variety of spatiotemporal physical systems. The Well draws from domain experts and numerical software developers to provide 15TB of data across 16 datasets covering diverse domains such as biological systems, fluid dynamics, acoustic scattering, as well as magneto-hydrodynamic simulations of extra-galactic fluids or supernova explosions. These datasets can be used individually or as part of a broader benchmark suite. To facilitate usage of the Well, we provide a unified PyTorch interface for training and evaluating models. We demonstrate the function of this library by introducing example baselines that highlight the new challenges posed by the complex dynamics of the Well. The code and data is available at https://github.com/PolymathicAI/the_well.
Removing Dust from CMB Observations with Diffusion Models
Oct 25, 2023In cosmology, the quest for primordial $B$-modes in cosmic microwave background (CMB) observations has highlighted the critical need for a refined model of the Galactic dust foreground. We investigate diffusion-based modeling of the dust foreground and its interest for component separation. Under the assumption of a Gaussian CMB with known cosmology (or covariance matrix), we show that diffusion models can be trained on examples of dust emission maps such that their sampling process directly coincides with posterior sampling in the context of component separation. We illustrate this on simulated mixtures of dust emission and CMB. We show that common summary statistics (power spectrum, Minkowski functionals) of the components are well recovered by this process. We also introduce a model conditioned by the CMB cosmology that outperforms models trained using a single cosmology on component separation. Such a model will be used in future work for diffusion-based cosmological inference.
The CAMELS project: public data release
Jan 04, 2022
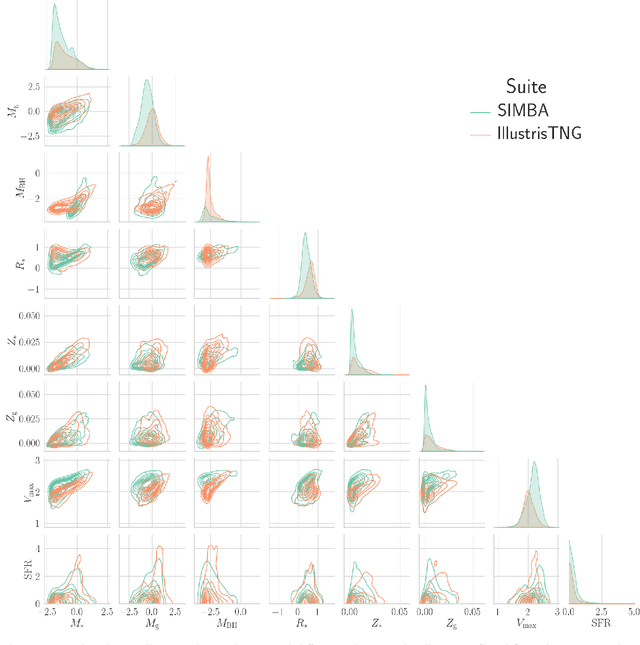
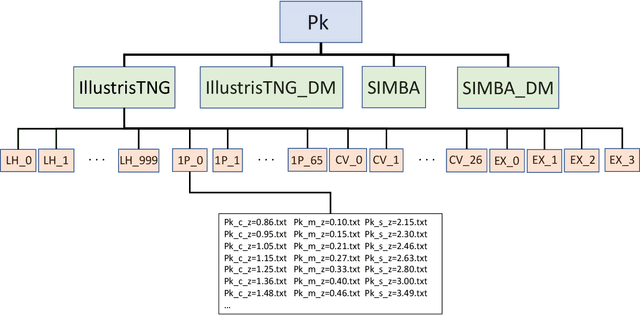
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.