 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aligned Protein Language Model
May 22, 2025Protein language models (pLMs) pre-trained on vast protein sequence databases excel at various downstream tasks but lack the structural knowledge essential for many biological applications. To address this, we integrate structural insights from pre-trained protein graph neural networks (pGNNs) into pLMs through a latent-level contrastive learning task. This task aligns residue representations from pLMs with those from pGNNs across multiple proteins, enriching pLMs with inter-protein structural knowledge. Additionally, we incorporate a physical-level task that infuses intra-protein structural knowledge by optimizing pLMs to predict structural tokens. The proposed dual-task framework effectively incorporates both inter-protein and intra-protein structural knowledge into pLMs. Given the variability in the quality of protein structures in PDB, we further introduce a residue loss selection module, which uses a small model trained on high-quality structures to select reliable yet challenging residue losses for the pLM to learn. Applying our structure alignment method to the state-of-the-art ESM2 and AMPLIFY results in notable performance gains across a wide range of tasks, including a 12.7% increase in ESM2 contact prediction. The data, code, and resulting SaESM2 and SaAMPLIFY models will be released on Hugging Face.
Compression via Pre-trained Transformers: A Study on Byte-Level Multimodal Data
Oct 07, 2024

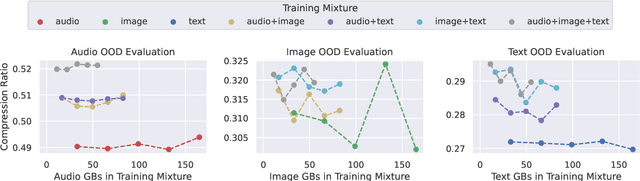
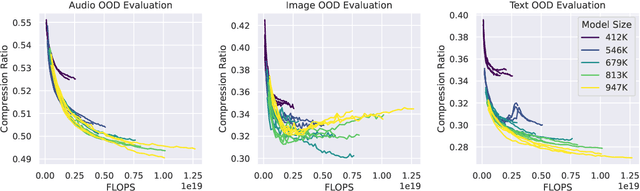
Foundation models have recently been shown to be strong data compressors. However, when accounting for their excessive parameter count, their compression ratios are actually inferior to standard compression algorithms. Moreover, naively reducing the number of parameters may not necessarily help as it leads to worse predictions and thus weaker compression. In this paper, we conduct a large-scale empirical study to investigate whether there is a sweet spot where competitive compression ratios with pre-trained vanilla transformers are possible. To this end, we train families of models on 165GB of raw byte sequences of either text, image, or audio data (and all possible combinations of the three) and then compress 1GB of out-of-distribution (OOD) data from each modality. We find that relatively small models (i.e., millions of parameters) can outperform standard general-purpose compression algorithms (gzip, LZMA2) and even domain-specific compressors (PNG, JPEG 2000, FLAC) - even when factoring in parameter count. We achieve, e.g., the lowest compression ratio of 0.49 on OOD audio data (vs. 0.54 for FLAC). To study the impact of model- and dataset scale, we conduct extensive ablations and hyperparameter sweeps, and we investigate the effect of unimodal versus multimodal training. We find that even small models can be trained to perform well on multiple modalities, but, in contrast to previously reported results with large-scale foundation models, transfer to unseen modalities is generally weak.
Listening to the Noise: Blind Denoising with Gibbs Diffusion
Feb 29, 2024



In recent years, denoising problems have become intertwined with the development of deep generative models. In particular, diffusion models are trained like denoisers, and the distribution they model coincide with denoising priors in the Bayesian picture. However, denoising through diffusion-based posterior sampling requires the noise level and covariance to be known, preventing blind denoising. We overcome this limitation by introducing Gibbs Diffusion (GDiff), a general methodology addressing posterior sampling of both the signal and the noise parameters. Assuming arbitrary parametric Gaussian noise, we develop a Gibbs algorithm that alternates sampling steps from a conditional diffusion model trained to map the signal prior to the family of noise distributions, and a Monte Carlo sampler to infer the noise parameters. Our theoretical analysis highlights potential pitfalls, guides diagnostic usage, and quantifies errors in the Gibbs stationary distribution caused by the diffusion model. We showcase our method for 1) blind denoising of natural images involving colored noises with unknown amplitude and spectral index, and 2) a cosmology problem, namely the analysis of cosmic microwave background data, where Bayesian inference of "noise" parameters means constraining models of the evolution of the Universe.
Removing Dust from CMB Observations with Diffusion Models
Oct 25, 2023In cosmology, the quest for primordial $B$-modes in cosmic microwave background (CMB) observations has highlighted the critical need for a refined model of the Galactic dust foreground. We investigate diffusion-based modeling of the dust foreground and its interest for component separation. Under the assumption of a Gaussian CMB with known cosmology (or covariance matrix), we show that diffusion models can be trained on examples of dust emission maps such that their sampling process directly coincides with posterior sampling in the context of component separation. We illustrate this on simulated mixtures of dust emission and CMB. We show that common summary statistics (power spectrum, Minkowski functionals) of the components are well recovered by this process. We also introduce a model conditioned by the CMB cosmology that outperforms models trained using a single cosmology on component separation. Such a model will be used in future work for diffusion-based cosmological inference.