 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression via Pre-trained Transformers: A Study on Byte-Level Multimodal Data
Paper and Code
Oct 07, 2024

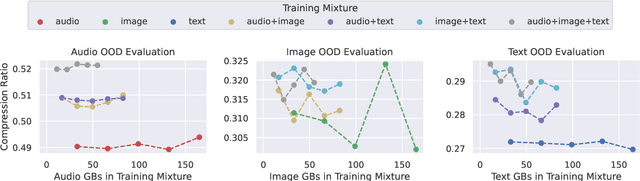
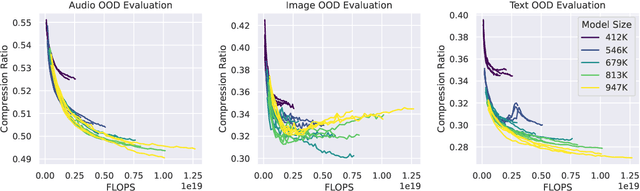
Foundation models have recently been shown to be strong data compressors. However, when accounting for their excessive parameter count, their compression ratios are actually inferior to standard compression algorithms. Moreover, naively reducing the number of parameters may not necessarily help as it leads to worse predictions and thus weaker compression. In this paper, we conduct a large-scale empirical study to investigate whether there is a sweet spot where competitive compression ratios with pre-trained vanilla transformers are possible. To this end, we train families of models on 165GB of raw byte sequences of either text, image, or audio data (and all possible combinations of the three) and then compress 1GB of out-of-distribution (OOD) data from each modality. We find that relatively small models (i.e., millions of parameters) can outperform standard general-purpose compression algorithms (gzip, LZMA2) and even domain-specific compressors (PNG, JPEG 2000, FLAC) - even when factoring in parameter count. We achieve, e.g., the lowest compression ratio of 0.49 on OOD audio data (vs. 0.54 for FLAC). To study the impact of model- and dataset scale, we conduct extensive ablations and hyperparameter sweeps, and we investigate the effect of unimodal versus multimodal training. We find that even small models can be trained to perform well on multiple modalities, but, in contrast to previously reported results with large-scale foundation models, transfer to unseen modalities is generally weak.