 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGalaxy Phase-Space and Field-Level Cosmology: The Strength of Semi-Analytic Models
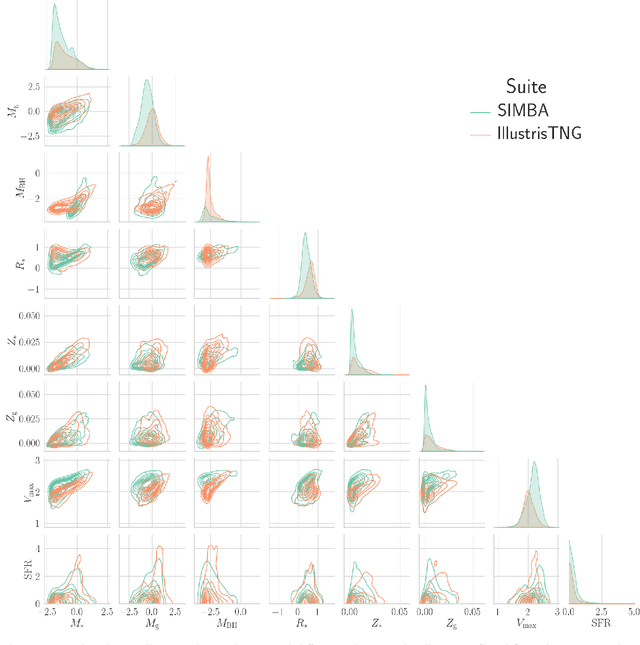
Dec 11, 2025Semi-analytic models are a widely used approach to simulate galaxy properties within a cosmological framework, relying on simplified yet physically motivated prescriptions. They have also proven to be an efficient alternative for generating accurate galaxy catalogs, offering a faster and less computationally expensive option compared to full hydrodynamical simulations. In this paper, we demonstrate that using only galaxy $3$D positions and radial velocities, we can train a graph neural network coupled to a moment neural network to obtain a robust machine learning based model capable of estimating the matter density parameters, $Ω_{\rm m}$, with a precision of approximately 10%. The network is trained on ($25 h^{-1}$Mpc)$^3$ volumes of galaxy catalogs from L-Galaxies and can successfully extrapolate its predictions to other semi-analytic models (GAEA, SC-SAM, and Shark) and, more remarkably, to hydrodynamical simulations (Astrid, SIMBA, IllustrisTNG, and SWIFT-EAGLE). Our results show that the network is robust to variations in astrophysical and subgrid physics, cosmological and astrophysical parameters, and the different halo-profile treatments used across simulations. This suggests that the physical relationships encoded in the phase-space of semi-analytic models are largely independent of their specific physical prescriptions, reinforcing their potential as tools for the generation of realistic mock catalogs for cosmological parameter inference.
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
Feb 06, 2024



This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schema, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable, designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterising progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
Field-level simulation-based inference with galaxy catalogs: the impact of systematic effects
Oct 23, 2023It has been recently shown that a powerful way to constrain cosmological parameters from galaxy redshift surveys is to train graph neural networks to perform field-level likelihood-free inference without imposing cuts on scale. In particular, de Santi et al. (2023) developed models that could accurately infer the value of $\Omega_{\rm m}$ from catalogs that only contain the positions and radial velocities of galaxies that are robust to uncertainties in astrophysics and subgrid models. However, observations are affected by many effects, including 1) masking, 2) uncertainties in peculiar velocities and radial distances, and 3) different galaxy selections. Moreover, observations only allow us to measure redshift, intertwining galaxies' radial positions and velocities. In this paper we train and test our models on galaxy catalogs, created from thousands of state-of-the-art hydrodynamic simulations run with different codes from the CAMELS project, that incorporate these observational effects. We find that, although the presence of these effects degrades the precision and accuracy of the models, and increases the fraction of catalogs where the model breaks down, the fraction of galaxy catalogs where the model performs well is over 90 %, demonstrating the potential of these models to constrain cosmological parameters even when applied to real data.
The CAMELS project: public data release
Jan 04, 2022
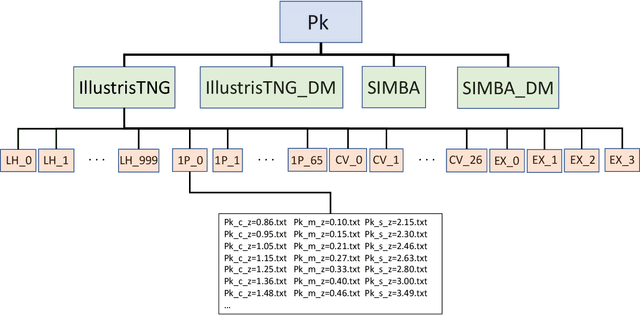
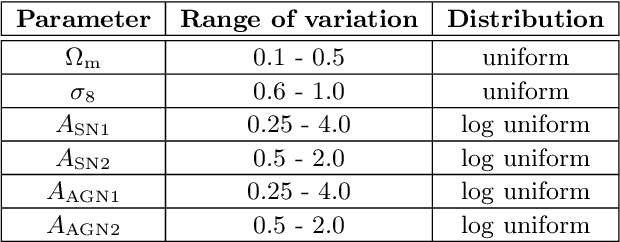
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
The CAMELS Multifield Dataset: Learning the Universe's Fundamental Parameters with Artificial Intelligence
Sep 22, 2021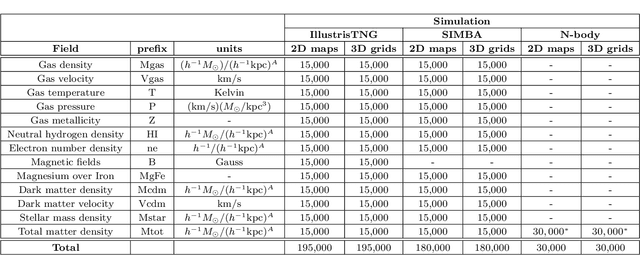

We present the Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) Multifield Dataset, CMD, a collection of hundreds of thousands of 2D maps and 3D grids containing many different properties of cosmic gas, dark matter, and stars from 2,000 distinct simulated universes at several cosmic times. The 2D maps and 3D grids represent cosmic regions that span $\sim$100 million light years and have been generated from thousands of state-of-the-art hydrodynamic and gravity-only N-body simulations from the CAMELS project. Designed to train machine learning models, CMD is the largest dataset of its kind containing more than 70 Terabytes of data. In this paper we describe CMD in detail and outline a few of its applications. We focus our attention on one such task, parameter inference, formulating the problems we face as a challenge to the community. We release all data and provide further technical details at https://camels-multifield-dataset.readthedocs.io.