 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGalaxy Phase-Space and Field-Level Cosmology: The Strength of Semi-Analytic Models
Dec 11, 2025Semi-analytic models are a widely used approach to simulate galaxy properties within a cosmological framework, relying on simplified yet physically motivated prescriptions. They have also proven to be an efficient alternative for generating accurate galaxy catalogs, offering a faster and less computationally expensive option compared to full hydrodynamical simulations. In this paper, we demonstrate that using only galaxy $3$D positions and radial velocities, we can train a graph neural network coupled to a moment neural network to obtain a robust machine learning based model capable of estimating the matter density parameters, $Ω_{\rm m}$, with a precision of approximately 10%. The network is trained on ($25 h^{-1}$Mpc)$^3$ volumes of galaxy catalogs from L-Galaxies and can successfully extrapolate its predictions to other semi-analytic models (GAEA, SC-SAM, and Shark) and, more remarkably, to hydrodynamical simulations (Astrid, SIMBA, IllustrisTNG, and SWIFT-EAGLE). Our results show that the network is robust to variations in astrophysical and subgrid physics, cosmological and astrophysical parameters, and the different halo-profile treatments used across simulations. This suggests that the physical relationships encoded in the phase-space of semi-analytic models are largely independent of their specific physical prescriptions, reinforcing their potential as tools for the generation of realistic mock catalogs for cosmological parameter inference.
Field-level simulation-based inference with galaxy catalogs: the impact of systematic effects
Oct 23, 2023It has been recently shown that a powerful way to constrain cosmological parameters from galaxy redshift surveys is to train graph neural networks to perform field-level likelihood-free inference without imposing cuts on scale. In particular, de Santi et al. (2023) developed models that could accurately infer the value of $\Omega_{\rm m}$ from catalogs that only contain the positions and radial velocities of galaxies that are robust to uncertainties in astrophysics and subgrid models. However, observations are affected by many effects, including 1) masking, 2) uncertainties in peculiar velocities and radial distances, and 3) different galaxy selections. Moreover, observations only allow us to measure redshift, intertwining galaxies' radial positions and velocities. In this paper we train and test our models on galaxy catalogs, created from thousands of state-of-the-art hydrodynamic simulations run with different codes from the CAMELS project, that incorporate these observational effects. We find that, although the presence of these effects degrades the precision and accuracy of the models, and increases the fraction of catalogs where the model breaks down, the fraction of galaxy catalogs where the model performs well is over 90 %, demonstrating the potential of these models to constrain cosmological parameters even when applied to real data.
Robust field-level likelihood-free inference with galaxies
Feb 27, 2023We train graph neural networks to perform field-level likelihood-free inference using galaxy catalogs from state-of-the-art hydrodynamic simulations of the CAMELS project. Our models are rotationally, translationally, and permutation invariant and have no scale cutoff. By training on galaxy catalogs that only contain the 3D positions and radial velocities of approximately $1,000$ galaxies in tiny volumes of $(25~h^{-1}{\rm Mpc})^3$, our models achieve a precision of approximately $12$% when inferring the value of $\Omega_{\rm m}$. To test the robustness of our models, we evaluated their performance on galaxy catalogs from thousands of hydrodynamic simulations, each with different efficiencies of supernova and AGN feedback, run with five different codes and subgrid models, including IllustrisTNG, SIMBA, Astrid, Magneticum, and SWIFT-EAGLE. Our results demonstrate that our models are robust to astrophysics, subgrid physics, and subhalo/galaxy finder changes. Furthermore, we test our models on 1,024 simulations that cover a vast region in parameter space - variations in 5 cosmological and 23 astrophysical parameters - finding that the model extrapolates really well. Including both positions and velocities are key to building robust models, and our results indicate that our networks have likely learned an underlying physical relation that does not depend on galaxy formation and is valid on scales larger than, at least, $~\sim10~h^{-1}{\rm kpc}$.
Robust field-level inference with dark matter halos
Sep 14, 2022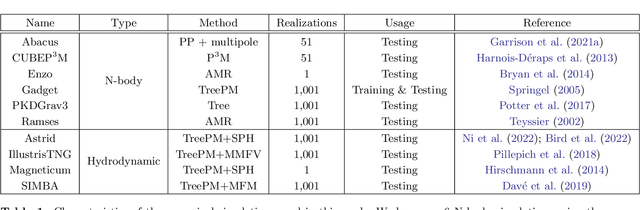
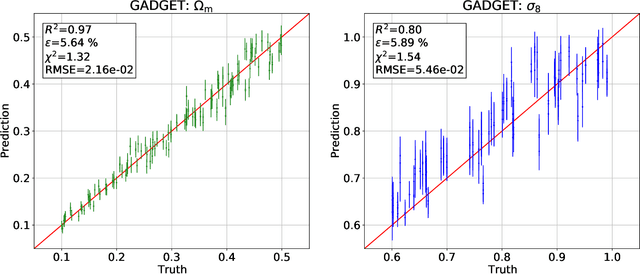
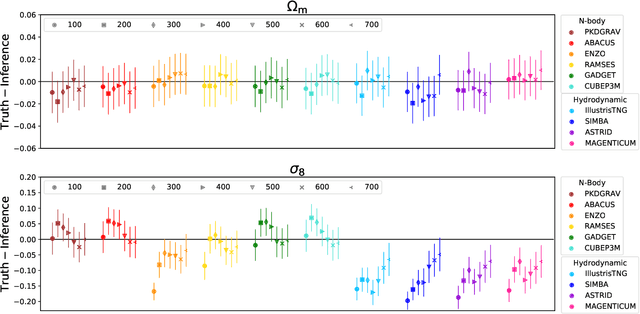

We train graph neural networks on halo catalogues from Gadget N-body simulations to perform field-level likelihood-free inference of cosmological parameters. The catalogues contain $\lesssim$5,000 halos with masses $\gtrsim 10^{10}~h^{-1}M_\odot$ in a periodic volume of $(25~h^{-1}{\rm Mpc})^3$; every halo in the catalogue is characterized by several properties such as position, mass, velocity, concentration, and maximum circular velocity. Our models, built to be permutationally, translationally, and rotationally invariant, do not impose a minimum scale on which to extract information and are able to infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a mean relative error of $\sim6\%$, when using positions plus velocities and positions plus masses, respectively. More importantly, we find that our models are very robust: they can infer the value of $\Omega_{\rm m}$ and $\sigma_8$ when tested using halo catalogues from thousands of N-body simulations run with five different N-body codes: Abacus, CUBEP$^3$M, Enzo, PKDGrav3, and Ramses. Surprisingly, the model trained to infer $\Omega_{\rm m}$ also works when tested on thousands of state-of-the-art CAMELS hydrodynamic simulations run with four different codes and subgrid physics implementations. Using halo properties such as concentration and maximum circular velocity allow our models to extract more information, at the expense of breaking the robustness of the models. This may happen because the different N-body codes are not converged on the relevant scales corresponding to these parameters.
Satellite galaxy abundance dependency on cosmology in Magneticum simulations
Oct 11, 2021
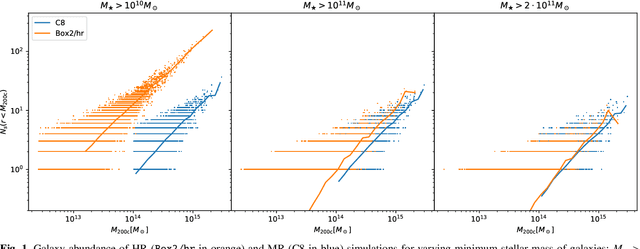
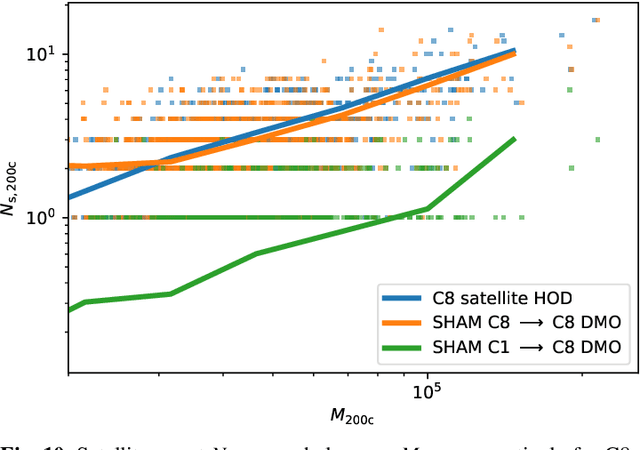
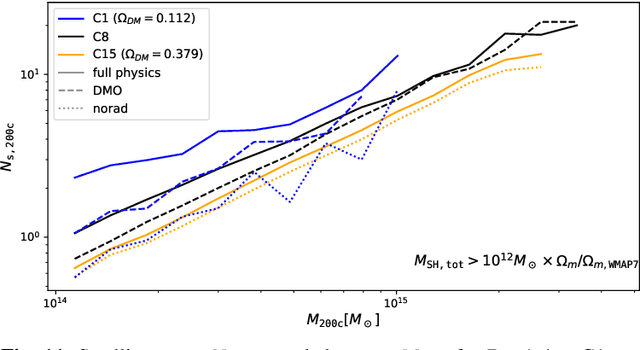
Context: Modelling satellite galaxy abundance $N_s$ in Galaxy Clusters (GCs) is a key element in modelling the Halo Occupation Distribution (HOD), which itself is a powerful tool to connect observational studies with numerical simulations. Aims: To study the impact of cosmological parameters on satellite abundance both in cosmological simulations and in mock observations. Methods: We build an emulator (HODEmu, \url{https://github.com/aragagnin/HODEmu/}) of satellite abundance based on cosmological parameters $\Omega_m, \Omega_b, \sigma_8, h_0$ and redshift $z.$ We train our emulator using \magneticum hydrodynamic simulations that span 15 different cosmologies, each over $4$ redshift slices between $0<z<0.5,$ and for each setup we fit normalisation $A$, log-slope $\beta$ and Gaussian fractional-scatter $\sigma$ of the $N_s-M$ relation. The emulator is based on multi-variate output Gaussian Process Regression (GPR). Results: We find that $A$ and $\beta$ depend on cosmological parameters, even if weakly, especially on $\Omega_m,$ $\Omega_b.$ This dependency can explain some discrepancies found in literature between satellite HOD of different cosmological simulations (Magneticum, Illustris, BAHAMAS). We also show that satellite abundance cosmology dependency differs between full-physics (FP) simulations, dark-matter only (DMO), and non-radiative simulations. Conclusions: This work provides a preliminary calibration of the cosmological dependency of the satellite abundance of high mass halos, and we showed that modelling HOD with cosmological parameters is necessary to interpret satellite abundance, and we showed the importance of using FP simulations in modelling this dependency.