 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory
Sep 04, 2025


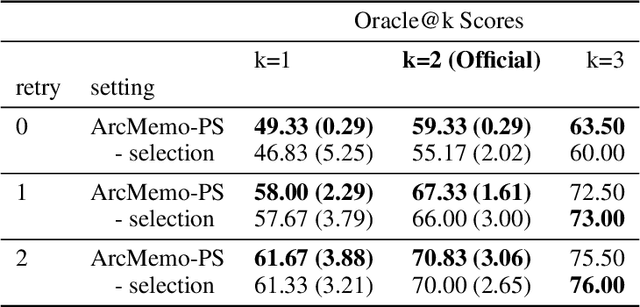
While inference-time scaling enables LLMs to carry out increasingly long and capable reasoning traces, the patterns and insights uncovered during these traces are immediately discarded once the context window is reset for a new query. External memory is a natural way to persist these discoveries, and recent work has shown clear benefits for reasoning-intensive tasks. We see an opportunity to make such memories more broadly reusable and scalable by moving beyond instance-based memory entries (e.g. exact query/response pairs, or summaries tightly coupled with the original problem context) toward concept-level memory: reusable, modular abstractions distilled from solution traces and stored in natural language. For future queries, relevant concepts are selectively retrieved and integrated into the prompt, enabling test-time continual learning without weight updates. Our design introduces new strategies for abstracting takeaways from rollouts and retrieving entries for new queries, promoting reuse and allowing memory to expand with additional experiences. On the challenging ARC-AGI benchmark, our method yields a 7.5% relative gain over a strong no-memory baseline with performance continuing to scale with inference compute. We find abstract concepts to be the most consistent memory design, outscoring the baseline at all tested inference compute scales. Moreover, we confirm that dynamically updating memory during test-time outperforms an otherwise identical fixed memory setting with additional attempts, supporting the hypothesis that solving more problems and abstracting more patterns to memory enables further solutions in a form of self-improvement. Code available at https://github.com/matt-seb-ho/arc_memo.
Proof Flow: Preliminary Study on Generative Flow Network Language Model Tuning for Formal Reasoning
Oct 17, 2024


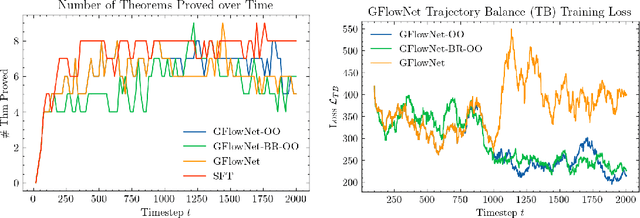
Reasoning is a fundamental substrate for solving novel and complex problems. Deliberate efforts in learning and developing frameworks around System 2 reasoning have made great strides, yet problems of sufficient complexity remain largely out of reach for open models. To address this gap, we examine the potential of Generative Flow Networks as a fine-tuning method for LLMs to unlock advanced reasoning capabilities. In this paper, we present a proof of concept in the domain of formal reasoning, specifically in the Neural Theorem Proving (NTP) setting, where proofs specified in a formal language such as Lean can be deterministically and objectively verified. Unlike classical reward-maximization reinforcement learning, which frequently over-exploits high-reward actions and fails to effectively explore the state space, GFlowNets have emerged as a promising approach for sampling compositional objects, improving generalization, and enabling models to maintain diverse hypotheses. Our early results demonstrate GFlowNet fine-tuning's potential for enhancing model performance in a search setting, which is especially relevant given the paradigm shift towards inference time compute scaling and "thinking slowly."
Reconstructing Galaxy Cluster Mass Maps using Score-based Generative Modeling
Oct 03, 2024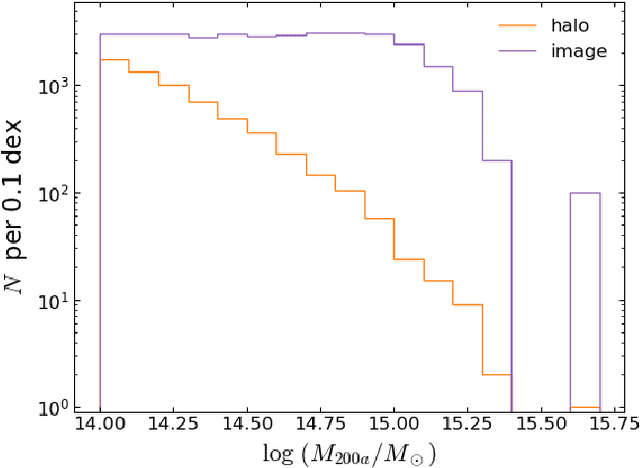


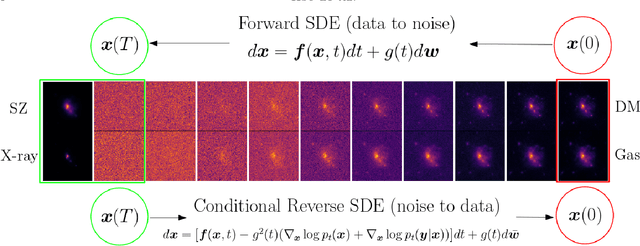
We present a novel approach to reconstruct gas and dark matter projected density maps of galaxy clusters using score-based generative modeling. Our diffusion model takes in mock SZ and X-ray images as conditional observations, and generates realizations of corresponding gas and dark matter maps by sampling from a learned data posterior. We train and validate the performance of our model by using mock data from a hydrodynamical cosmological simulation. The model accurately reconstructs both the mean and spread of the radial density profiles in the spatial domain to within 5\%, indicating that the model is able to distinguish between clusters of different sizes. In the spectral domain, the model achieves close-to-unity values for the bias and cross-correlation coefficients, indicating that the model can accurately probe cluster structures on both large and small scales. Our experiments demonstrate the ability of score models to learn a strong, nonlinear, and unbiased mapping between input observables and fundamental density distributions of galaxy clusters. These diffusion models can be further fine-tuned and generalized to not only take in additional observables as inputs, but also real observations and predict unknown density distributions of galaxy clusters.
CHARM: Creating Halos with Auto-Regressive Multi-stage networks
Sep 13, 2024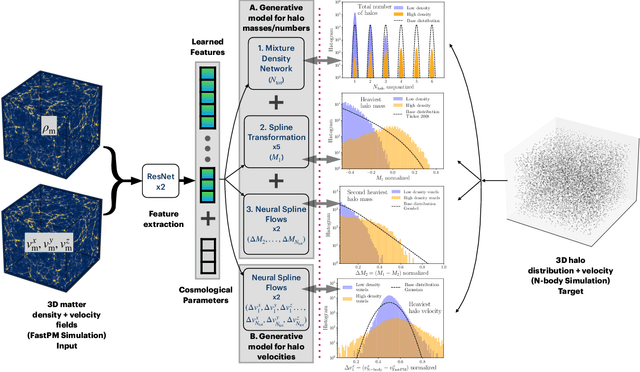
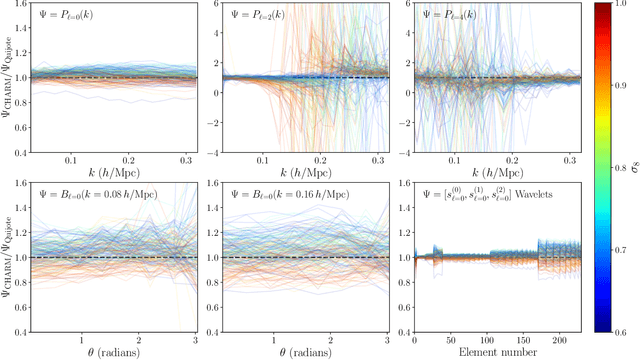
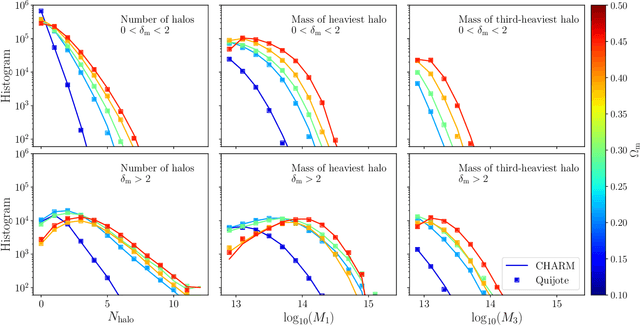
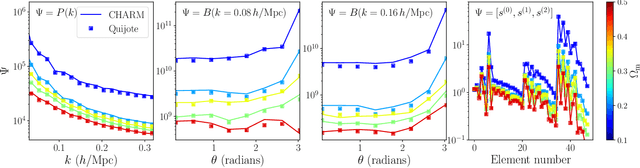
To maximize the amount of information extracted from cosmological datasets, simulations that accurately represent these observations are necessary. However, traditional simulations that evolve particles under gravity by estimating particle-particle interactions (N-body simulations) are computationally expensive and prohibitive to scale to the large volumes and resolutions necessary for the upcoming datasets. Moreover, modeling the distribution of galaxies typically involves identifying virialized dark matter halos, which is also a time- and memory-consuming process for large N-body simulations, further exacerbating the computational cost. In this study, we introduce CHARM, a novel method for creating mock halo catalogs by matching the spatial, mass, and velocity statistics of halos directly from the large-scale distribution of the dark matter density field. We develop multi-stage neural spline flow-based networks to learn this mapping at redshift z=0.5 directly with computationally cheaper low-resolution particle mesh simulations instead of relying on the high-resolution N-body simulations. We show that the mock halo catalogs and painted galaxy catalogs have the same statistical properties as obtained from $N$-body simulations in both real space and redshift space. Finally, we use these mock catalogs for cosmological inference using redshift-space galaxy power spectrum, bispectrum, and wavelet-based statistics using simulation-based inference, performing the first inference with accelerated forward model simulations and finding unbiased cosmological constraints with well-calibrated posteriors. The code was developed as part of the Simons Collaboration on Learning the Universe and is publicly available at \url{https://github.com/shivampcosmo/CHARM}.
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
Feb 06, 2024



This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schema, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable, designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterising progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
Information-Ordered Bottlenecks for Adaptive Semantic Compression
May 18, 2023We present the information-ordered bottleneck (IOB), a neural layer designed to adaptively compress data into latent variables ordered by likelihood maximization. Without retraining, IOB nodes can be truncated at any bottleneck width, capturing the most crucial information in the first latent variables. Unifying several previous approaches, we show that IOBs achieve near-optimal compression for a given encoding architecture and can assign ordering to latent signals in a manner that is semantically meaningful. IOBs demonstrate a remarkable ability to compress embeddings of image and text data, leveraging the performance of SOTA architectures such as CNNs, transformers, and diffusion models. Moreover, we introduce a novel theory for estimating global intrinsic dimensionality with IOBs and show that they recover SOTA dimensionality estimates for complex synthetic data. Furthermore, we showcase the utility of these models for exploratory analysis through applications on heterogeneous datasets, enabling computer-aided discovery of dataset complexity.