 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Proof Flow: Preliminary Study on Generative Flow Network Language Model Tuning for Formal Reasoning
Oct 17, 2024


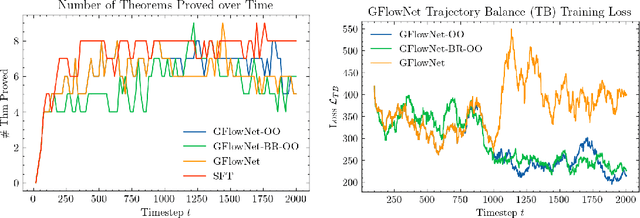
Reasoning is a fundamental substrate for solving novel and complex problems. Deliberate efforts in learning and developing frameworks around System 2 reasoning have made great strides, yet problems of sufficient complexity remain largely out of reach for open models. To address this gap, we examine the potential of Generative Flow Networks as a fine-tuning method for LLMs to unlock advanced reasoning capabilities. In this paper, we present a proof of concept in the domain of formal reasoning, specifically in the Neural Theorem Proving (NTP) setting, where proofs specified in a formal language such as Lean can be deterministically and objectively verified. Unlike classical reward-maximization reinforcement learning, which frequently over-exploits high-reward actions and fails to effectively explore the state space, GFlowNets have emerged as a promising approach for sampling compositional objects, improving generalization, and enabling models to maintain diverse hypotheses. Our early results demonstrate GFlowNet fine-tuning's potential for enhancing model performance in a search setting, which is especially relevant given the paradigm shift towards inference time compute scaling and "thinking slowly."
Large Legislative Models: Towards Efficient AI Policymaking in Economic Simulations
Oct 10, 2024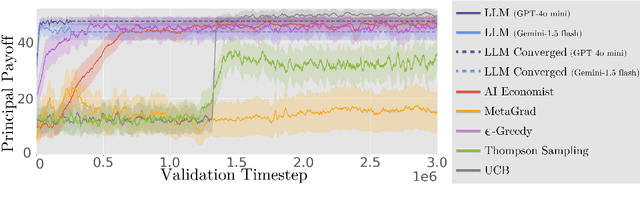
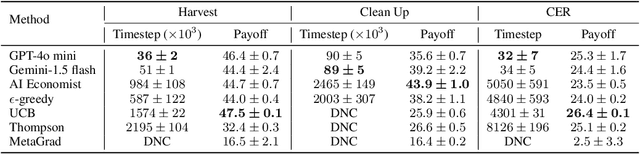
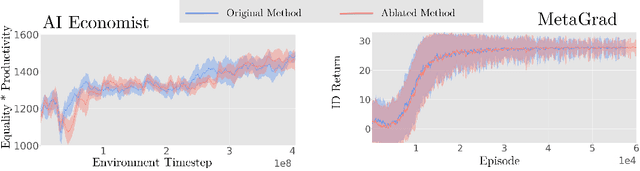
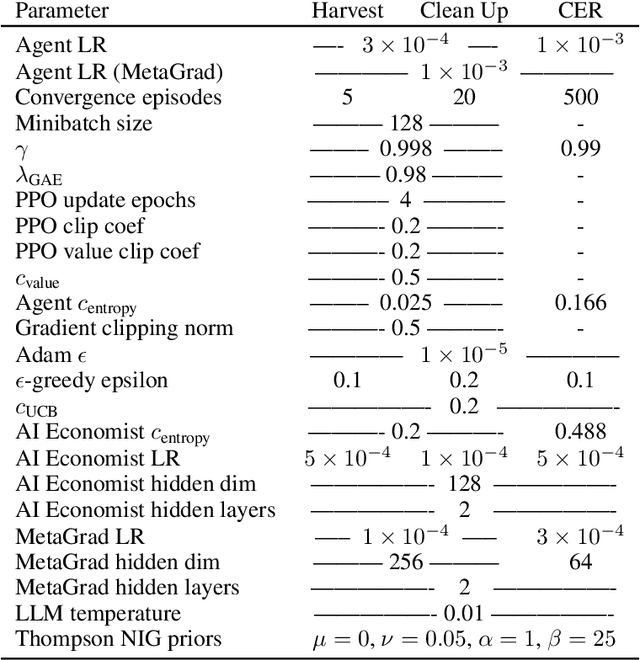
The improvement of economic policymaking presents an opportunity for broad societal benefit, a notion that has inspired research towards AI-driven policymaking tools. AI policymaking holds the potential to surpass human performance through the ability to process data quickly at scale. However, existing RL-based methods exhibit sample inefficiency, and are further limited by an inability to flexibly incorporate nuanced information into their decision-making processes. Thus, we propose a novel method in which we instead utilize pre-trained Large Language Models (LLMs), as sample-efficient policymakers in socially complex multi-agent reinforcement learning (MARL) scenarios. We demonstrate significant efficiency gains, outperforming existing methods across three environments. Our code is available at https://github.com/hegasz/large-legislative-models.
Transcendence: Generative Models Can Outperform The Experts That Train Them
Jun 17, 2024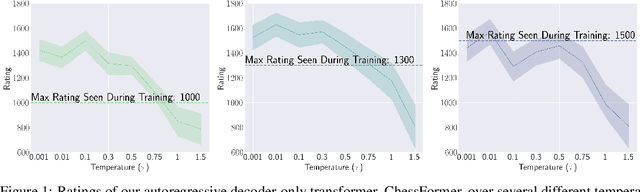

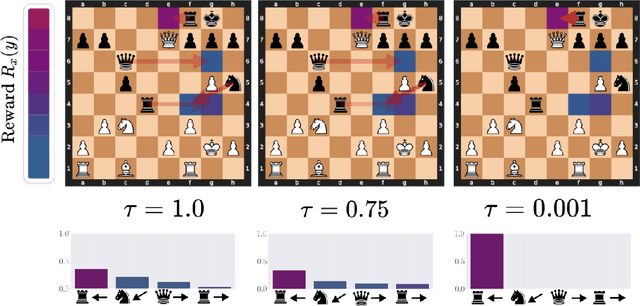
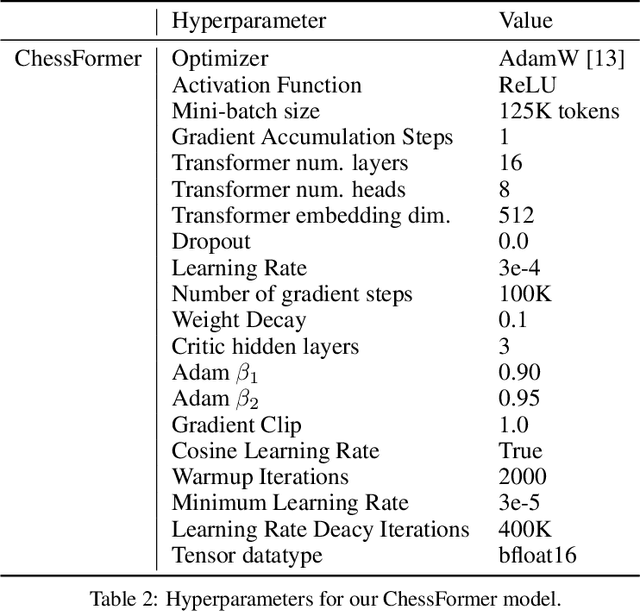
Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of transcendence: when a generative model achieves capabilities that surpass the abilities of the experts generating its data. We demonstrate transcendence by training an autoregressive transformer to play chess from game transcripts, and show that the trained model can sometimes achieve better performance than all players in the dataset. We theoretically prove that transcendence is enabled by low-temperature sampling, and rigorously assess this experimentally. Finally, we discuss other sources of transcendence, laying the groundwork for future investigation of this phenomenon in a broader setting.