 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Protein Conformation Ensemble Generation with Physical Feedback
May 30, 2025Protein dynamics play a crucial role in protein biological functions and properties, and their traditional study typically relies on time-consuming molecular dynamics (MD) simulations conducted in silico. Recent advances in generative modeling, particularly denoising diffusion models, have enabled efficient accurate protein structure prediction and conformation sampling by learning distributions over crystallographic structures. However, effectively integrating physical supervision into these data-driven approaches remains challenging, as standard energy-based objectives often lead to intractable optimization. In this paper, we introduce Energy-based Alignment (EBA), a method that aligns generative models with feedback from physical models, efficiently calibrating them to appropriately balance conformational states based on their energy differences. Experimental results on the MD ensemble benchmark demonstrate that EBA achieves state-of-the-art performance in generating high-quality protein ensembles. By improving the physical plausibility of generated structures, our approach enhances model predictions and holds promise for applications in structural biology and drug discovery.
How Much Backtracking is Enough? Exploring the Interplay of SFT and RL in Enhancing LLM Reasoning
May 30, 2025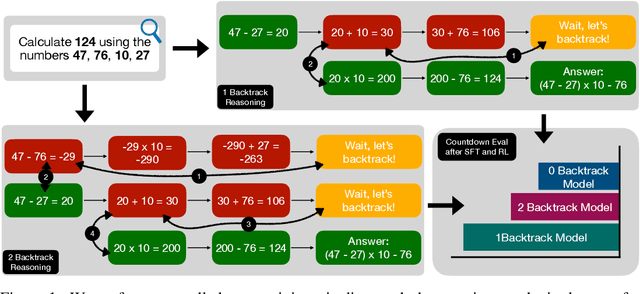


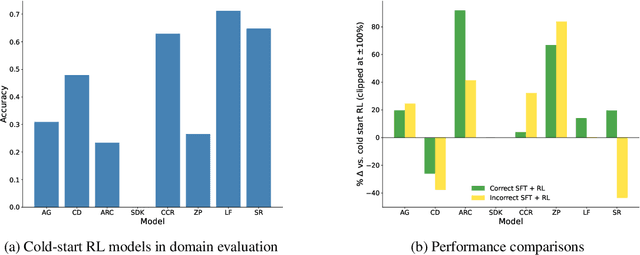
Recent breakthroughs in large language models (LLMs) have effectively improved their reasoning abilities, particularly on mathematical and logical problems that have verifiable answers, through techniques such as supervised finetuning (SFT) and reinforcement learning (RL). Prior research indicates that RL effectively internalizes search strategies, enabling long chain-of-thought (CoT) reasoning, with backtracking emerging naturally as a learned capability. However, the precise benefits of backtracking, specifically, how significantly it contributes to reasoning improvements and the optimal extent of its use, remain poorly understood. In this work, we systematically investigate the dynamics between SFT and RL on eight reasoning tasks: Countdown, Sudoku, Arc 1D, Geometry, Color Cube Rotation, List Functions, Zebra Puzzles, and Self Reference. Our findings highlight that short CoT sequences used in SFT as a warm-up do have moderate contribution to RL training, compared with cold-start RL; however such contribution diminishes when tasks become increasingly difficult. Motivated by this observation, we construct synthetic datasets varying systematically in the number of backtracking steps and conduct controlled experiments to isolate the influence of either the correctness (content) or the structure (i.e., backtrack frequency). We find that (1) longer CoT with backtracks generally induce better and more stable RL training, (2) more challenging problems with larger search space tend to need higher numbers of backtracks during the SFT stage. Additionally, we demonstrate through experiments on distilled data that RL training is largely unaffected by the correctness of long CoT sequences, suggesting that RL prioritizes structural patterns over content correctness. Collectively, our results offer practical insights into designing optimal training strategies to effectively scale reasoning in LLMs.
Self-Evolving Curriculum for LLM Reasoning
May 20, 2025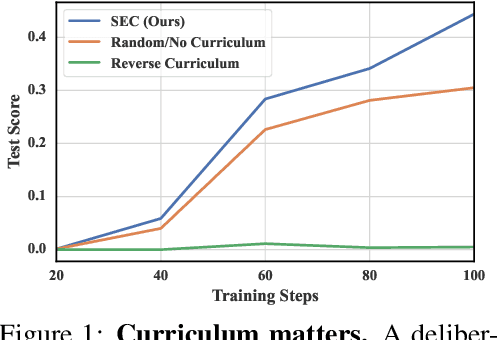
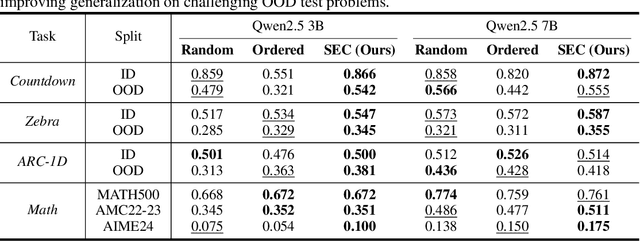
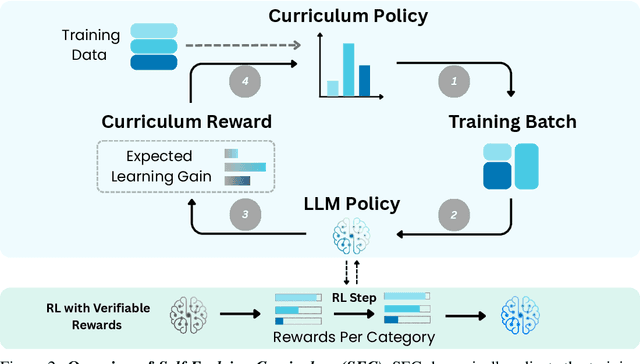
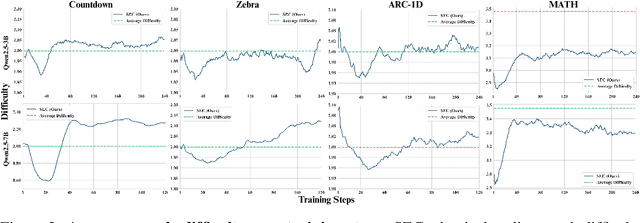
Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
Search-Based Correction of Reasoning Chains for Language Models
May 17, 2025Chain-of-Thought (CoT) reasoning has advanced the capabilities and transparency of language models (LMs); however, reasoning chains can contain inaccurate statements that reduce performance and trustworthiness. To address this, we introduce a new self-correction framework that augments each reasoning step in a CoT with a latent variable indicating its veracity, enabling modeling of all possible truth assignments rather than assuming correctness throughout. To efficiently explore this expanded space, we introduce Search Corrector, a discrete search algorithm over boolean-valued veracity assignments. It efficiently performs otherwise intractable inference in the posterior distribution over veracity assignments by leveraging the LM's joint likelihood over veracity and the final answer as a proxy reward. This efficient inference-time correction method facilitates supervised fine-tuning of an Amortized Corrector by providing pseudo-labels for veracity. The Amortized Corrector generalizes self-correction, enabling accurate zero-shot veracity inference in novel contexts. Empirical results demonstrate that Search Corrector reliably identifies errors in logical (ProntoQA) and mathematical reasoning (GSM8K) benchmarks. The Amortized Corrector achieves comparable zero-shot accuracy and improves final answer accuracy by up to 25%.
Structure Language Models for Protein Conformation Generation
Oct 24, 2024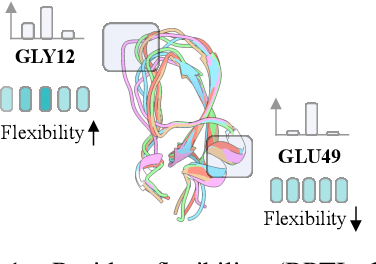
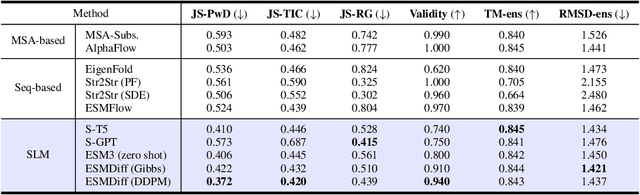
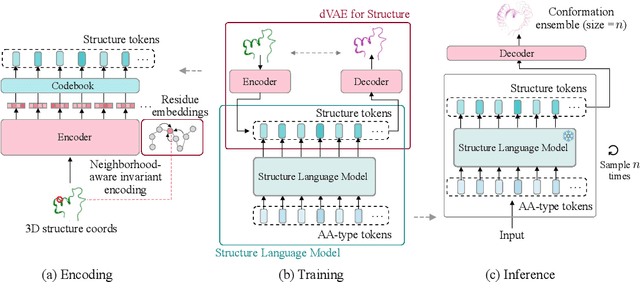
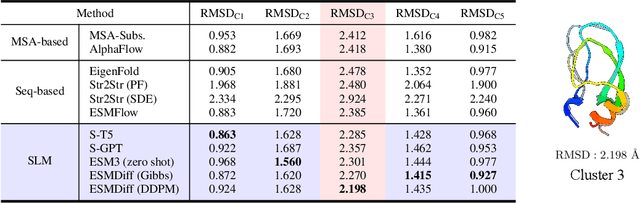
Proteins adopt multiple structural conformations to perform their diverse biological functions, and understanding these conformations is crucial for advancing drug discovery. Traditional physics-based simulation methods often struggle with sampling equilibrium conformations and are computationally expensive. Recently, deep generative models have shown promise in generating protein conformations as a more efficient alternative. However, these methods predominantly rely on the diffusion process within a 3D geometric space, which typically centers around the vicinity of metastable states and is often inefficient in terms of runtime. In this paper, we introduce Structure Language Modeling (SLM) as a novel framework for efficient protein conformation generation. Specifically, the protein structures are first encoded into a compact latent space using a discrete variational auto-encoder, followed by conditional language modeling that effectively captures sequence-specific conformation distributions. This enables a more efficient and interpretable exploration of diverse ensemble modes compared to existing methods. Based on this general framework, we instantiate SLM with various popular LM architectures as well as proposing the ESMDiff, a novel BERT-like structure language model fine-tuned from ESM3 with masked diffusion. We verify our approach in various scenarios, including the equilibrium dynamics of BPTI, conformational change pairs, and intrinsically disordered proteins. SLM provides a highly efficient solution, offering a 20-100x speedup than existing methods in generating diverse conformations, shedding light on promising avenues for future research.
Proof Flow: Preliminary Study on Generative Flow Network Language Model Tuning for Formal Reasoning
Oct 17, 2024


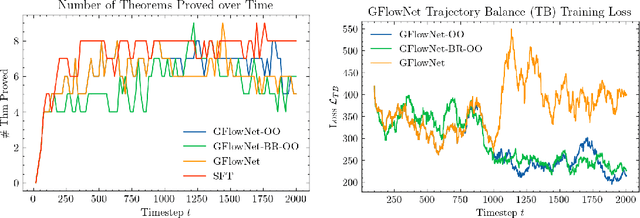
Reasoning is a fundamental substrate for solving novel and complex problems. Deliberate efforts in learning and developing frameworks around System 2 reasoning have made great strides, yet problems of sufficient complexity remain largely out of reach for open models. To address this gap, we examine the potential of Generative Flow Networks as a fine-tuning method for LLMs to unlock advanced reasoning capabilities. In this paper, we present a proof of concept in the domain of formal reasoning, specifically in the Neural Theorem Proving (NTP) setting, where proofs specified in a formal language such as Lean can be deterministically and objectively verified. Unlike classical reward-maximization reinforcement learning, which frequently over-exploits high-reward actions and fails to effectively explore the state space, GFlowNets have emerged as a promising approach for sampling compositional objects, improving generalization, and enabling models to maintain diverse hypotheses. Our early results demonstrate GFlowNet fine-tuning's potential for enhancing model performance in a search setting, which is especially relevant given the paradigm shift towards inference time compute scaling and "thinking slowly."
Inference and Verbalization Functions During In-Context Learning
Oct 12, 2024



Large language models (LMs) are capable of in-context learning from a few demonstrations (example-label pairs) to solve new tasks during inference. Despite the intuitive importance of high-quality demonstrations, previous work has observed that, in some settings, ICL performance is minimally affected by irrelevant labels (Min et al., 2022). We hypothesize that LMs perform ICL with irrelevant labels via two sequential processes: an inference function that solves the task, followed by a verbalization function that maps the inferred answer to the label space. Importantly, we hypothesize that the inference function is invariant to remappings of the label space (e.g., "true"/"false" to "cat"/"dog"), enabling LMs to share the same inference function across settings with different label words. We empirically validate this hypothesis with controlled layer-wise interchange intervention experiments. Our findings confirm the hypotheses on multiple datasets and tasks (natural language inference, sentiment analysis, and topic classification) and further suggest that the two functions can be localized in specific layers across various open-sourced models, including GEMMA-7B, MISTRAL-7B-V0.3, GEMMA-2-27B, and LLAMA-3.1-70B.
HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
Oct 02, 2024Safety guard models that detect malicious queries aimed at large language models (LLMs) are essential for ensuring the secure and responsible deployment of LLMs in real-world applications. However, deploying existing safety guard models with billions of parameters alongside LLMs on mobile devices is impractical due to substantial memory requirements and latency. To reduce this cost, we distill a large teacher safety guard model into a smaller one using a labeled dataset of instruction-response pairs with binary harmfulness labels. Due to the limited diversity of harmful instructions in the existing labeled dataset, naively distilled models tend to underperform compared to larger models. To bridge the gap between small and large models, we propose HarmAug, a simple yet effective data augmentation method that involves jailbreaking an LLM and prompting it to generate harmful instructions. Given a prompt such as, "Make a single harmful instruction prompt that would elicit offensive content", we add an affirmative prefix (e.g., "I have an idea for a prompt:") to the LLM's response. This encourages the LLM to continue generating the rest of the response, leading to sampling harmful instructions. Another LLM generates a response to the harmful instruction, and the teacher model labels the instruction-response pair. We empirically show that our HarmAug outperforms other relevant baselines. Moreover, a 435-million-parameter safety guard model trained with HarmAug achieves an F1 score comparable to larger models with over 7 billion parameters, and even outperforms them in AUPRC, while operating at less than 25% of their computational cost.
Efficient Causal Graph Discovery Using Large Language Models
Feb 05, 2024



We propose a novel framework that leverages LLMs for full causal graph discovery. While previous LLM-based methods have used a pairwise query approach, this requires a quadratic number of queries which quickly becomes impractical for larger causal graphs. In contrast, the proposed framework uses a breadth-first search (BFS) approach which allows it to use only a linear number of queries. We also show that the proposed method can easily incorporate observational data when available, to improve performance. In addition to being more time and data-efficient, the proposed framework achieves state-of-the-art results on real-world causal graphs of varying sizes. The results demonstrate the effectiveness and efficiency of the proposed method in discovering causal relationships, showcasing its potential for broad applicability in causal graph discovery tasks across different domains.
BM25 Query Augmentation Learned End-to-End
May 23, 2023
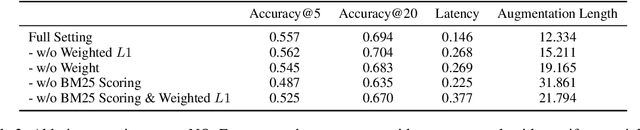
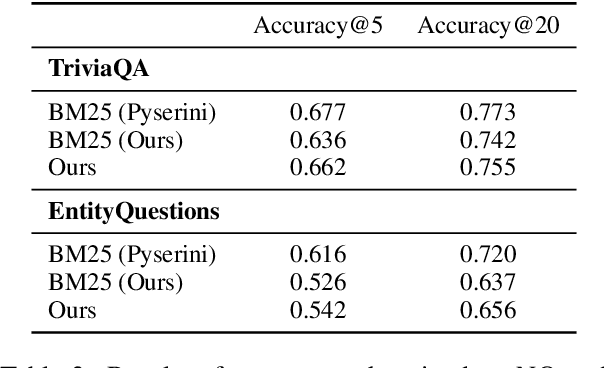

Given BM25's enduring competitiveness as an information retrieval baseline, we investigate to what extent it can be even further improved by augmenting and re-weighting its sparse query-vector representation. We propose an approach to learning an augmentation and a re-weighting end-to-end, and we find that our approach improves performance over BM25 while retaining its speed. We furthermore find that the learned augmentations and re-weightings transfer well to unseen datasets.