Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBM25 Query Augmentation Learned End-to-End
Paper and Code

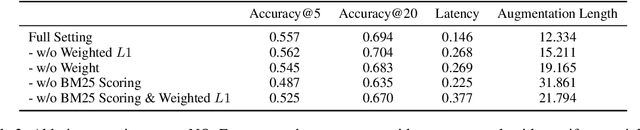
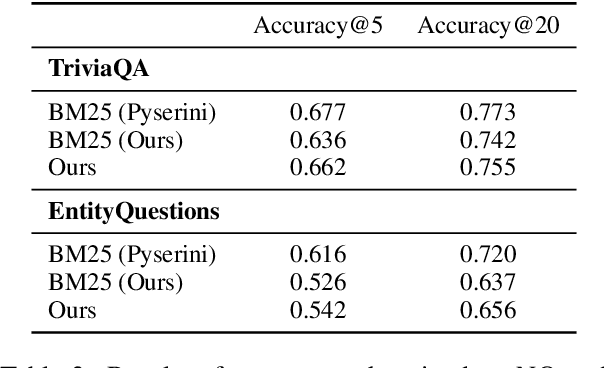

Given BM25's enduring competitiveness as an information retrieval baseline, we investigate to what extent it can be even further improved by augmenting and re-weighting its sparse query-vector representation. We propose an approach to learning an augmentation and a re-weighting end-to-end, and we find that our approach improves performance over BM25 while retaining its speed. We furthermore find that the learned augmentations and re-weightings transfer well to unseen datasets.
View paper on