 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comedy of Estimators: On KL Regularization in RL Training of LLMs
Dec 26, 2025The reasoning performance of large language models (LLMs) can be substantially improved by training them with reinforcement learning (RL). The RL objective for LLM training involves a regularization term, which is the reverse Kullback-Leibler (KL) divergence between the trained policy and the reference policy. Since computing the KL divergence exactly is intractable, various estimators are used in practice to estimate it from on-policy samples. Despite its wide adoption, including in several open-source libraries, there is no systematic study analyzing the numerous ways of incorporating KL estimators in the objective and their effect on the downstream performance of RL-trained models. Recent works show that prevailing practices for incorporating KL regularization do not provide correct gradients for stated objectives, creating a discrepancy between the objective and its implementation. In this paper, we further analyze these practices and study the gradients of several estimators configurations, revealing how design choices shape gradient bias. We substantiate these findings with empirical observations by RL fine-tuning \texttt{Qwen2.5-7B}, \texttt{Llama-3.1-8B-Instruct} and \texttt{Qwen3-4B-Instruct-2507} with different configurations and evaluating their performance on both in- and out-of-distribution tasks. Through our analysis, we observe that, in on-policy settings: (1) estimator configurations with biased gradients can result in training instabilities; and (2) using estimator configurations resulting in unbiased gradients leads to better performance on in-domain as well as out-of-domain tasks. We also investigate the performance resulting from different KL configurations in off-policy settings and observe that KL regularization can help stabilize off-policy RL training resulting from asynchronous setups.
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Uncertainty in Action: Confidence Elicitation in Embodied Agents
Mar 13, 2025Expressing confidence is challenging for embodied agents navigating dynamic multimodal environments, where uncertainty arises from both perception and decision-making processes. We present the first work investigating embodied confidence elicitation in open-ended multimodal environments. We introduce Elicitation Policies, which structure confidence assessment across inductive, deductive, and abductive reasoning, along with Execution Policies, which enhance confidence calibration through scenario reinterpretation, action sampling, and hypothetical reasoning. Evaluating agents in calibration and failure prediction tasks within the Minecraft environment, we show that structured reasoning approaches, such as Chain-of-Thoughts, improve confidence calibration. However, our findings also reveal persistent challenges in distinguishing uncertainty, particularly under abductive settings, underscoring the need for more sophisticated embodied confidence elicitation methods.
Auto-Bench: An Automated Benchmark for Scientific Discovery in LLMs
Feb 21, 2025Given the remarkable performance of Large Language Models (LLMs), an important question arises: Can LLMs conduct human-like scientific research and discover new knowledge, and act as an AI scientist? Scientific discovery is an iterative process that demands efficient knowledge updating and encoding. It involves understanding the environment, identifying new hypotheses, and reasoning about actions; however, no standardized benchmark specifically designed for scientific discovery exists for LLM agents. In response to these limitations, we introduce a novel benchmark, \textit{Auto-Bench}, that encompasses necessary aspects to evaluate LLMs for scientific discovery in both natural and social sciences. Our benchmark is based on the principles of causal graph discovery. It challenges models to uncover hidden structures and make optimal decisions, which includes generating valid justifications. By engaging interactively with an oracle, the models iteratively refine their understanding of underlying interactions, the chemistry and social interactions, through strategic interventions. We evaluate state-of-the-art LLMs, including GPT-4, Gemini, Qwen, Claude, and Llama, and observe a significant performance drop as the problem complexity increases, which suggests an important gap between machine and human intelligence that future development of LLMs need to take into consideration.
PRIMA: Multi-Image Vision-Language Models for Reasoning Segmentation
Dec 19, 2024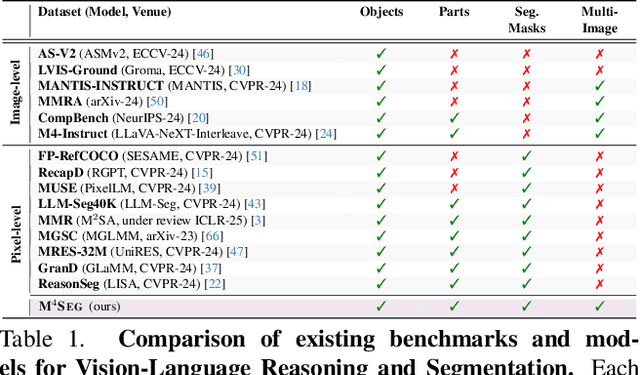
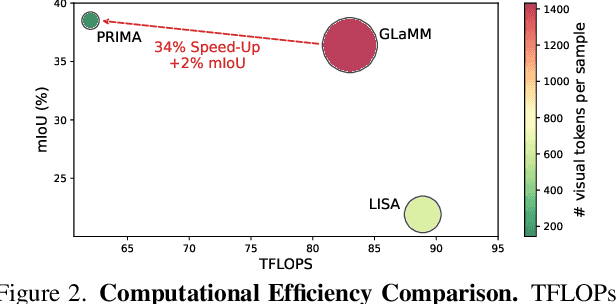
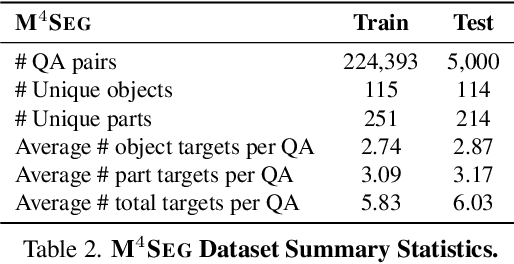
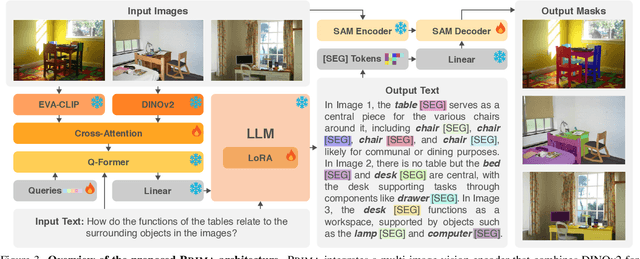
Despite significant advancements in Large Vision-Language Models (LVLMs), existing pixel-grounding models operate on single-image settings, limiting their ability to perform detailed, fine-grained comparisons across multiple images. Conversely, current multi-image understanding models lack pixel-level grounding. Our work addresses this gap by introducing the task of multi-image pixel-grounded reasoning segmentation, and PRIMA, a novel LVLM that integrates pixel-level grounding with robust multi-image reasoning capabilities to produce contextually rich, pixel-grounded explanations. Central to PRIMA is an efficient vision module that queries fine-grained visual representations across multiple images, reducing TFLOPs by $25.3\%$. To support training and evaluation, we curate $M^4Seg$, a new reasoning segmentation benchmark consisting of $\sim$224K question-answer pairs that require fine-grained visual understanding across multiple images. Experimental results demonstrate PRIMA outperforms state-of-the-art baselines.
General Causal Imputation via Synthetic Interventions
Oct 28, 2024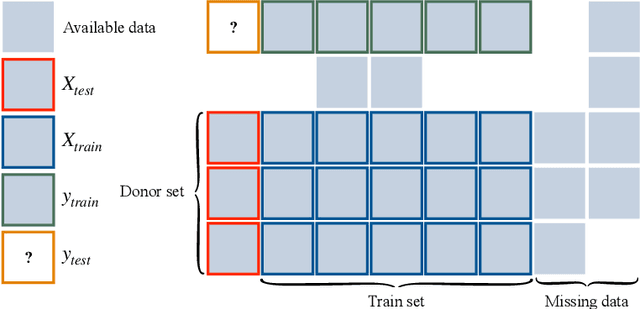
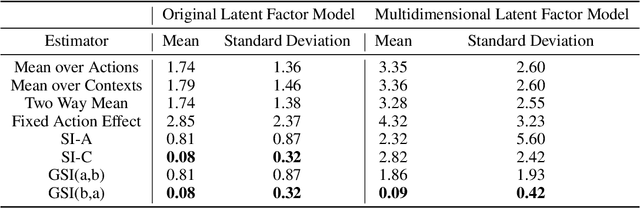
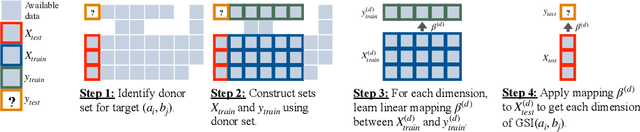
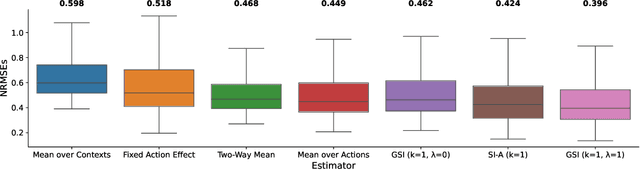
Given two sets of elements (such as cell types and drug compounds), researchers typically only have access to a limited subset of their interactions. The task of causal imputation involves using this subset to predict unobserved interactions. Squires et al. (2022) have proposed two estimators for this task based on the synthetic interventions (SI) estimator: SI-A (for actions) and SI-C (for contexts). We extend their work and introduce a novel causal imputation estimator, generalized synthetic interventions (GSI). We prove the identifiability of this estimator for data generated from a more complex latent factor model. On synthetic and real data we show empirically that it recovers or outperforms their estimators.
Masked Generative Priors Improve World Models Sequence Modelling Capabilities
Oct 10, 2024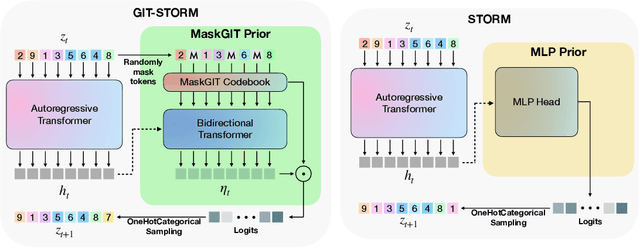


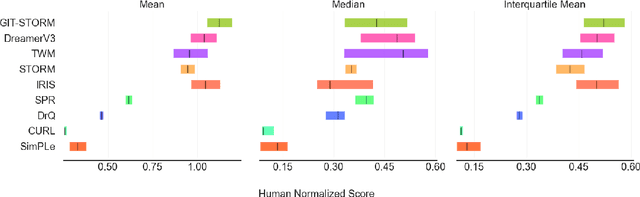
Deep Reinforcement Learning (RL) has become the leading approach for creating artificial agents in complex environments. Model-based approaches, which are RL methods with world models that predict environment dynamics, are among the most promising directions for improving data efficiency, forming a critical step toward bridging the gap between research and real-world deployment. In particular, world models enhance sample efficiency by learning in imagination, which involves training a generative sequence model of the environment in a self-supervised manner. Recently, Masked Generative Modelling has emerged as a more efficient and superior inductive bias for modelling and generating token sequences. Building on the Efficient Stochastic Transformer-based World Models (STORM) architecture, we replace the traditional MLP prior with a Masked Generative Prior (e.g., MaskGIT Prior) and introduce GIT-STORM. We evaluate our model on two downstream tasks: reinforcement learning and video prediction. GIT-STORM demonstrates substantial performance gains in RL tasks on the Atari 100k benchmark. Moreover, we apply Transformer-based World Models to continuous action environments for the first time, addressing a significant gap in prior research. To achieve this, we employ a state mixer function that integrates latent state representations with actions, enabling our model to handle continuous control tasks. We validate this approach through qualitative and quantitative analyses on the DeepMind Control Suite, showcasing the effectiveness of Transformer-based World Models in this new domain. Our results highlight the versatility and efficacy of the MaskGIT dynamics prior, paving the way for more accurate world models and effective RL policies.
AI-Assisted Generation of Difficult Math Questions
Jul 30, 2024



Current LLM training positions mathematical reasoning as a core capability. With publicly available sources fully tapped, there is unmet demand for diverse and challenging math questions. Relying solely on human experts is both time-consuming and costly, while LLM-generated questions often lack the requisite diversity and difficulty. We present a design framework that combines the strengths of LLMs with a human-in-the-loop approach to generate a diverse array of challenging math questions. We leverage LLM metacognition skills [Didolkar et al., 2024] of a strong LLM to extract core "skills" from existing math datasets. These skills serve as the basis for generating novel and difficult questions by prompting the LLM with random pairs of core skills. The use of two different skills within each question makes finding such questions an "out of distribution" task for both LLMs and humans. Our pipeline employs LLMs to iteratively generate and refine questions and solutions through multiturn prompting. Human annotators then verify and further refine the questions, with their efficiency enhanced via further LLM interactions. Applying this pipeline on skills extracted from the MATH dataset [Hendrycks et al., 2021] resulted in MATH$^2$ - a dataset of higher-quality math questions, as evidenced by: (a) Lower performance of all models on MATH$^2$ than on MATH (b) Higher performance on MATH when using MATH$^2$ questions as in-context examples. Although focused on mathematics, our methodology seems applicable to other domains requiring structured reasoning, and potentially as a component of scalable oversight. Also of interest is a striking relationship observed between models' performance on the new dataset: the success rate on MATH$^2$ is the square on MATH, suggesting that successfully solving the question in MATH$^2$ requires a nontrivial combination of two distinct math skills.
Towards DNA-Encoded Library Generation with GFlowNets
Apr 15, 2024DNA-encoded libraries (DELs) are a powerful approach for rapidly screening large numbers of diverse compounds. One of the key challenges in using DELs is library design, which involves choosing the building blocks that will be combinatorially combined to produce the final library. In this paper we consider the task of protein-protein interaction (PPI) biased DEL design. To this end, we evaluate several machine learning algorithms on the PPI modulation task and use them as a reward for the proposed GFlowNet-based generative approach. We additionally investigate the possibility of using structural information about building blocks to design a hierarchical action space for the GFlowNet. The observed results indicate that GFlowNets are a promising approach for generating diverse combinatorial library candidates.
Efficient Causal Graph Discovery Using Large Language Models
Feb 05, 2024



We propose a novel framework that leverages LLMs for full causal graph discovery. While previous LLM-based methods have used a pairwise query approach, this requires a quadratic number of queries which quickly becomes impractical for larger causal graphs. In contrast, the proposed framework uses a breadth-first search (BFS) approach which allows it to use only a linear number of queries. We also show that the proposed method can easily incorporate observational data when available, to improve performance. In addition to being more time and data-efficient, the proposed framework achieves state-of-the-art results on real-world causal graphs of varying sizes. The results demonstrate the effectiveness and efficiency of the proposed method in discovering causal relationships, showcasing its potential for broad applicability in causal graph discovery tasks across different domains.