 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
CoRe3D: Collaborative Reasoning as a Foundation for 3D Intelligence
Dec 14, 2025Recent advances in large multimodal models suggest that explicit reasoning mechanisms play a critical role in improving model reliability, interpretability, and cross-modal alignment. While such reasoning-centric approaches have been proven effective in language and vision tasks, their extension to 3D remains underdeveloped. CoRe3D introduces a unified 3D understanding and generation reasoning framework that jointly operates over semantic and spatial abstractions, enabling high-level intent inferred from language to directly guide low-level 3D content formation. Central to this design is a spatially grounded reasoning representation that decomposes 3D latent space into localized regions, allowing the model to reason over geometry in a compositional and procedural manner. By tightly coupling semantic chain-of-thought inference with structured spatial reasoning, CoRe3D produces 3D outputs that exhibit strong local consistency and faithful alignment with linguistic descriptions.
HalluSegBench: Counterfactual Visual Reasoning for Segmentation Hallucination Evaluation
Jun 26, 2025Recent progress in vision-language segmentation has significantly advanced grounded visual understanding. However, these models often exhibit hallucinations by producing segmentation masks for objects not grounded in the image content or by incorrectly labeling irrelevant regions. Existing evaluation protocols for segmentation hallucination primarily focus on label or textual hallucinations without manipulating the visual context, limiting their capacity to diagnose critical failures. In response, we introduce HalluSegBench, the first benchmark specifically designed to evaluate hallucinations in visual grounding through the lens of counterfactual visual reasoning. Our benchmark consists of a novel dataset of 1340 counterfactual instance pairs spanning 281 unique object classes, and a set of newly introduced metrics that quantify hallucination sensitivity under visually coherent scene edits. Experiments on HalluSegBench with state-of-the-art vision-language segmentation models reveal that vision-driven hallucinations are significantly more prevalent than label-driven ones, with models often persisting in false segmentation, highlighting the need for counterfactual reasoning to diagnose grounding fidelity.
PRIMA: Multi-Image Vision-Language Models for Reasoning Segmentation
Dec 19, 2024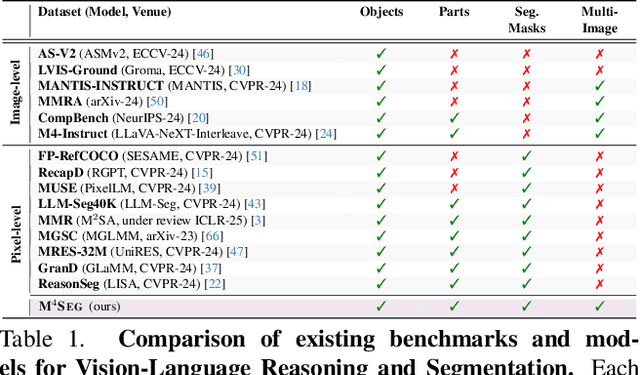
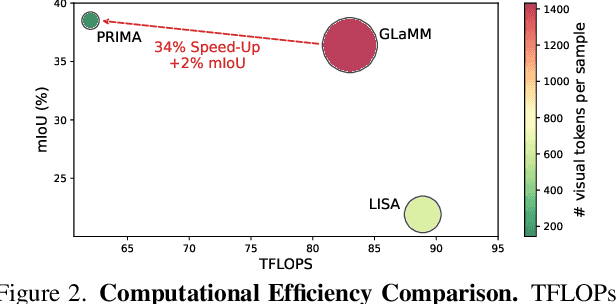
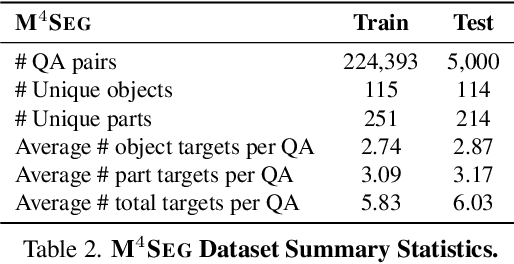
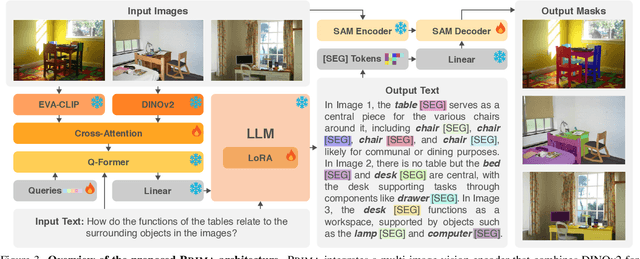
Despite significant advancements in Large Vision-Language Models (LVLMs), existing pixel-grounding models operate on single-image settings, limiting their ability to perform detailed, fine-grained comparisons across multiple images. Conversely, current multi-image understanding models lack pixel-level grounding. Our work addresses this gap by introducing the task of multi-image pixel-grounded reasoning segmentation, and PRIMA, a novel LVLM that integrates pixel-level grounding with robust multi-image reasoning capabilities to produce contextually rich, pixel-grounded explanations. Central to PRIMA is an efficient vision module that queries fine-grained visual representations across multiple images, reducing TFLOPs by $25.3\%$. To support training and evaluation, we curate $M^4Seg$, a new reasoning segmentation benchmark consisting of $\sim$224K question-answer pairs that require fine-grained visual understanding across multiple images. Experimental results demonstrate PRIMA outperforms state-of-the-art baselines.