 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyraTok: Language-Aligned Pyramidal Tokenizer for Video Understanding and Generation
Jan 22, 2026Discrete video VAEs underpin modern text-to-video generation and video understanding systems, yet existing tokenizers typically learn visual codebooks at a single scale with limited vocabularies and shallow language supervision, leading to poor cross-modal alignment and zero-shot transfer. We introduce PyraTok, a language-aligned pyramidal tokenizer that learns semantically structured discrete latents across multiple spatiotemporal resolutions. PyraTok builds on a pretrained video VAE and a novel Language aligned Pyramidal Quantization (LaPQ) module that discretizes encoder features at several depths using a shared large binary codebook, yielding compact yet expressive video token sequences. To tightly couple visual tokens with language, PyraTok jointly optimizes multi-scale text-guided quantization and a global autoregressive objective over the token hierarchy. Across ten benchmarks, PyraTok delivers state-of-the-art (SOTA) video reconstruction, consistently improves text-to-video quality, and sets new SOTA zero-shot performance on video segmentation, temporal action localization, and video understanding, scaling robustly to up to 4K/8K resolutions.
HalluSegBench: Counterfactual Visual Reasoning for Segmentation Hallucination Evaluation
Jun 26, 2025Recent progress in vision-language segmentation has significantly advanced grounded visual understanding. However, these models often exhibit hallucinations by producing segmentation masks for objects not grounded in the image content or by incorrectly labeling irrelevant regions. Existing evaluation protocols for segmentation hallucination primarily focus on label or textual hallucinations without manipulating the visual context, limiting their capacity to diagnose critical failures. In response, we introduce HalluSegBench, the first benchmark specifically designed to evaluate hallucinations in visual grounding through the lens of counterfactual visual reasoning. Our benchmark consists of a novel dataset of 1340 counterfactual instance pairs spanning 281 unique object classes, and a set of newly introduced metrics that quantify hallucination sensitivity under visually coherent scene edits. Experiments on HalluSegBench with state-of-the-art vision-language segmentation models reveal that vision-driven hallucinations are significantly more prevalent than label-driven ones, with models often persisting in false segmentation, highlighting the need for counterfactual reasoning to diagnose grounding fidelity.
Uncertainty in Action: Confidence Elicitation in Embodied Agents
Mar 13, 2025Expressing confidence is challenging for embodied agents navigating dynamic multimodal environments, where uncertainty arises from both perception and decision-making processes. We present the first work investigating embodied confidence elicitation in open-ended multimodal environments. We introduce Elicitation Policies, which structure confidence assessment across inductive, deductive, and abductive reasoning, along with Execution Policies, which enhance confidence calibration through scenario reinterpretation, action sampling, and hypothetical reasoning. Evaluating agents in calibration and failure prediction tasks within the Minecraft environment, we show that structured reasoning approaches, such as Chain-of-Thoughts, improve confidence calibration. However, our findings also reveal persistent challenges in distinguishing uncertainty, particularly under abductive settings, underscoring the need for more sophisticated embodied confidence elicitation methods.
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Dec 26, 2024Recent advances in Large Vision-Language Models (LVLMs) have sparked significant progress in general-purpose vision tasks through visual instruction tuning. While some works have demonstrated the capability of LVLMs to generate segmentation masks that align phrases with natural language descriptions in a single image, they struggle with segmentation-grounded comparisons across multiple images, particularly at finer granularities such as object parts. In this paper, we introduce the new task of part-focused semantic co-segmentation, which seeks to identify and segment common and unique objects and parts across images. To address this task, we present CALICO, the first LVLM that can segment and reason over multiple masks across images, enabling object comparison based on their constituent parts. CALICO features two proposed components, a novel Correspondence Extraction Module, which captures semantic-rich information to identify part-level correspondences between objects, and a Correspondence Adaptation Module, which embeds this information into the LVLM to facilitate multi-image understanding in a parameter-efficient manner. To support training and evaluation, we curate MixedParts, a comprehensive multi-image segmentation dataset containing $\sim$2.4M samples across $\sim$44K images with diverse object and part categories. Experimental results show CALICO, finetuned on only 0.3% of its architecture, achieves robust performance in part-focused semantic co-segmentation.
Face Verification and Forgery Detection for Ophthalmic Surgery Images
Nov 15, 2018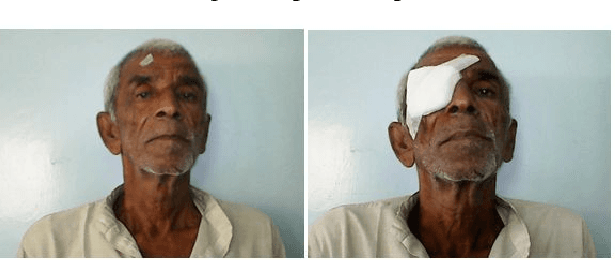
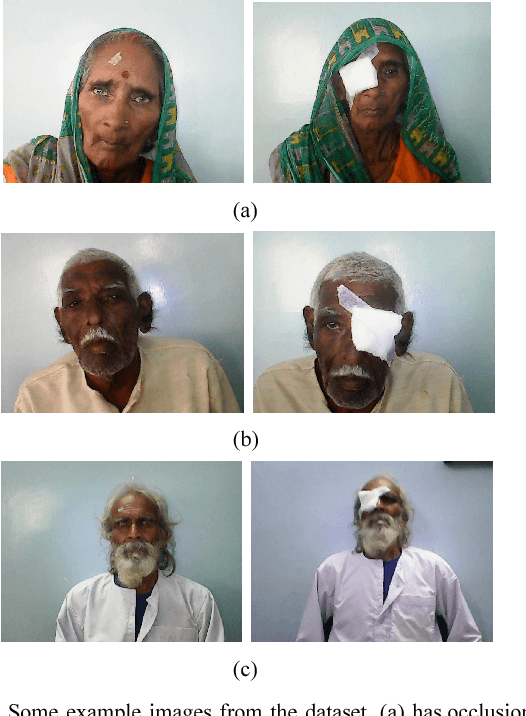
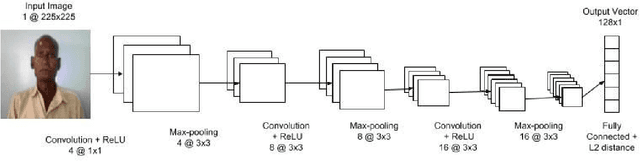
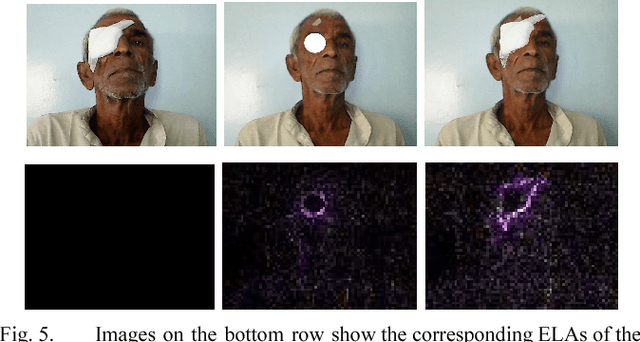
Although modern face verification systems are accessible and accurate, they are not always robust to pose variance and occlusions. Moreover, accurate models require a large amount of data to train. We structure our experiments to operate on small amounts of data obtained from an NGO that funds ophthalmic surgeries. We set up our face verification task as that of verifying pre-operation and post-operation images of a patient that undergoes ophthalmic surgery, and as such the post-operation images have occlusions like an eye patch. In this paper, we present a system that performs the face verification task using one-shot learning. To this end, our paper uses deep convolutional networks and compares different model architectures and loss functions. Our best model achieves 85% test accuracy. During inference time, we also attempt to detect image forgeries in addition to performing face verification. To achieve this, we use Error Level Analysis. Finally, we propose an inference pipeline that demonstrates how these techniques can be used to implement an automated face verification and forgery detection system.