 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice of India: A Large-Scale Benchmark for Real-World Speech Recognition in India
Apr 21, 2026Existing Indic ASR benchmarks often use scripted, clean speech and leaderboard driven evaluation that encourages dataset specific overfitting. In addition, strict single reference WER penalizes natural spelling variation in Indian languages, including non standardized spellings of code-mixed English origin words. To address these limitations, we introduce Voice of India, a closed source benchmark built from unscripted telephonic conversations covering 15 major Indian languages across 139 regional clusters. The dataset contains 306230 utterances, totaling 536 hours of speech from 36691 speakers with transcripts accounting for spelling variations. We also analyze performance geographically at the district level, revealing disparities. Finally, we provide detailed analysis across factors such as audio quality, speaking rate, gender, and device type, highlighting where current ASR systems struggle and offering insights for improving real world Indic ASR systems.
Recognizing Every Voice: Towards Inclusive ASR for Rural Bhojpuri Women
Jun 11, 2025Digital inclusion remains a challenge for marginalized communities, especially rural women in low-resource language regions like Bhojpuri. Voice-based access to agricultural services, financial transactions, government schemes, and healthcare is vital for their empowerment, yet existing ASR systems for this group remain largely untested. To address this gap, we create SRUTI ,a benchmark consisting of rural Bhojpuri women speakers. Evaluation of current ASR models on SRUTI shows poor performance due to data scarcity, which is difficult to overcome due to social and cultural barriers that hinder large-scale data collection. To overcome this, we propose generating synthetic speech using just 25-30 seconds of audio per speaker from approximately 100 rural women. Augmenting existing datasets with this synthetic data achieves an improvement of 4.7 WER, providing a scalable, minimally intrusive solution to enhance ASR and promote digital inclusion in low-resource language.
LAHAJA: A Robust Multi-accent Benchmark for Evaluating Hindi ASR Systems
Aug 21, 2024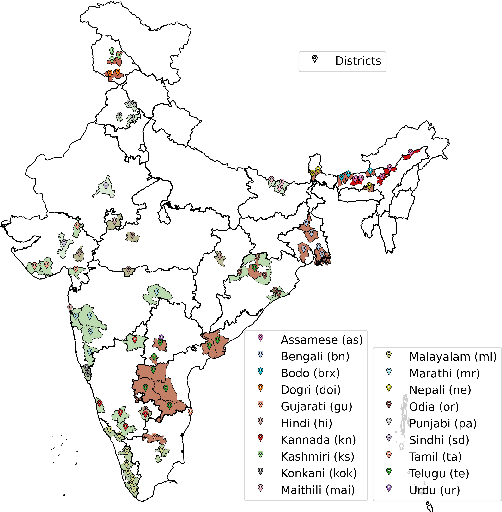

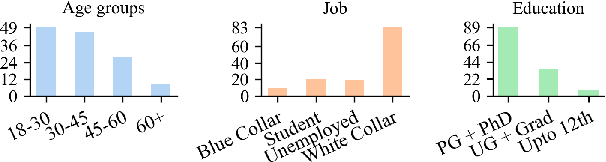

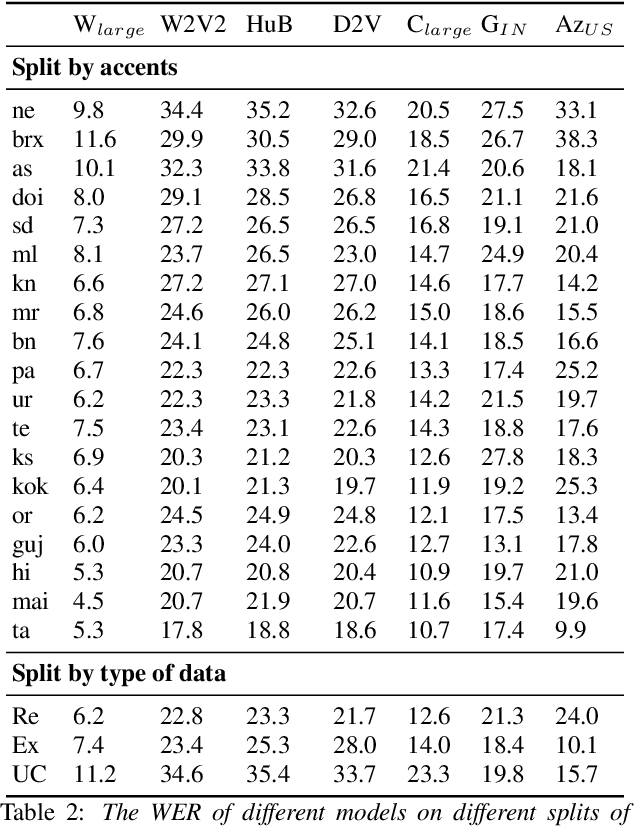
Hindi, one of the most spoken language of India, exhibits a diverse array of accents due to its usage among individuals from diverse linguistic origins. To enable a robust evaluation of Hindi ASR systems on multiple accents, we create a benchmark, LAHAJA, which contains read and extempore speech on a diverse set of topics and use cases, with a total of 12.5 hours of Hindi audio, sourced from 132 speakers spanning 83 districts of India. We evaluate existing open-source and commercial models on LAHAJA and find their performance to be poor. We then train models using different datasets and find that our model trained on multilingual data with good speaker diversity outperforms existing models by a significant margin. We also present a fine-grained analysis which shows that the performance declines for speakers from North-East and South India, especially with content heavy in named entities and specialized terminology.
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023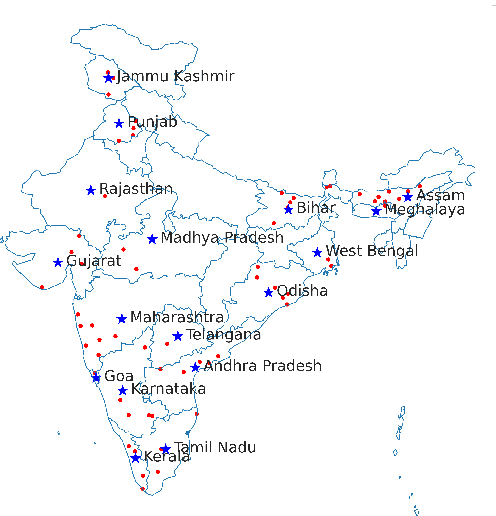
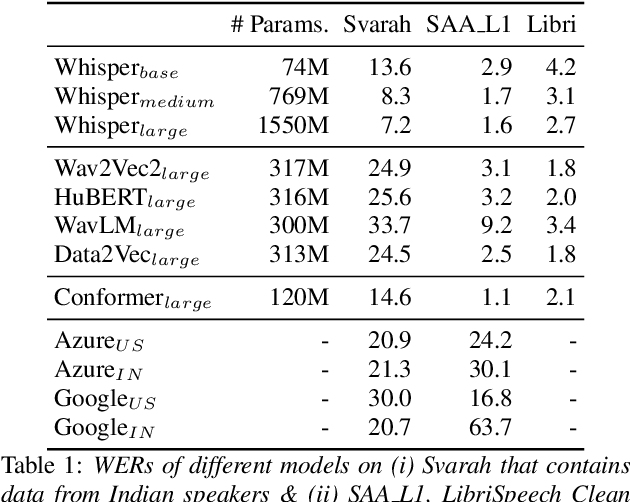
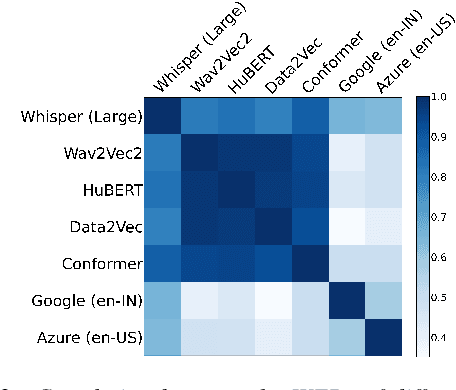
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
Towards Efficient and Effective Self-Supervised Learning of Visual Representations
Oct 18, 2022

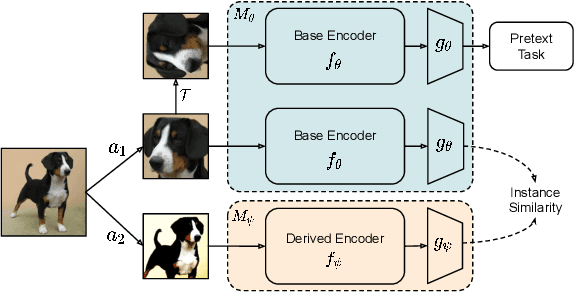
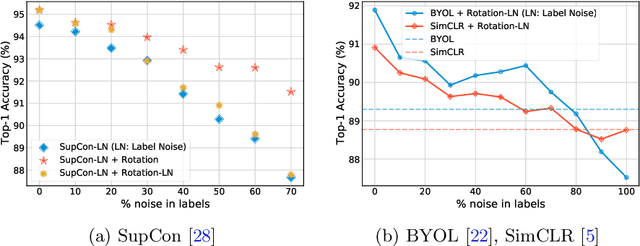
Self-supervision has emerged as a propitious method for visual representation learning after the recent paradigm shift from handcrafted pretext tasks to instance-similarity based approaches. Most state-of-the-art methods enforce similarity between various augmentations of a given image, while some methods additionally use contrastive approaches to explicitly ensure diverse representations. While these approaches have indeed shown promising direction, they require a significantly larger number of training iterations when compared to the supervised counterparts. In this work, we explore reasons for the slow convergence of these methods, and further propose to strengthen them using well-posed auxiliary tasks that converge significantly faster, and are also useful for representation learning. The proposed method utilizes the task of rotation prediction to improve the efficiency of existing state-of-the-art methods. We demonstrate significant gains in performance using the proposed method on multiple datasets, specifically for lower training epochs.
Data-free Knowledge Distillation for Segmentation using Data-Enriching GAN
Nov 02, 2020


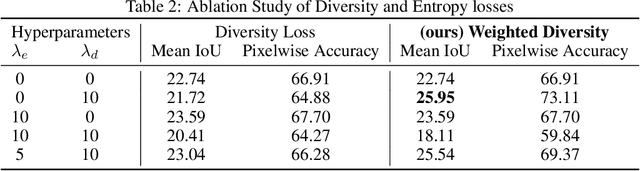
Distilling knowledge from huge pre-trained networks to improve the performance of tiny networks has favored deep learning models to be used in many real-time and mobile applications. Several approaches that demonstrate success in this field have made use of the true training dataset to extract relevant knowledge. In absence of the True dataset, however, extracting knowledge from deep networks is still a challenge. Recent works on data-free knowledge distillation demonstrate such techniques on classification tasks. To this end, we explore the task of data-free knowledge distillation for segmentation tasks. First, we identify several challenges specific to segmentation. We make use of the DeGAN training framework to propose a novel loss function for enforcing diversity in a setting where a few classes are underrepresented. Further, we explore a new training framework for performing knowledge distillation in a data-free setting. We get an improvement of 6.93% in Mean IoU over previous approaches.
Face Verification and Forgery Detection for Ophthalmic Surgery Images
Nov 15, 2018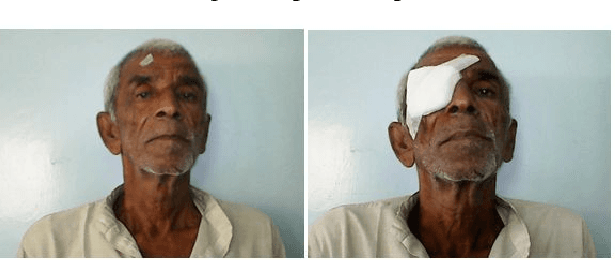
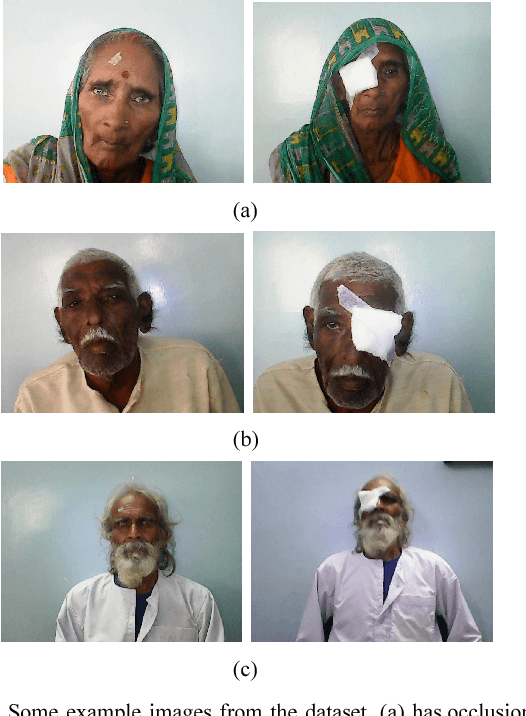
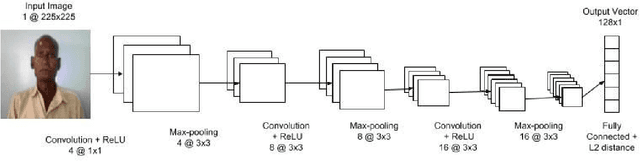
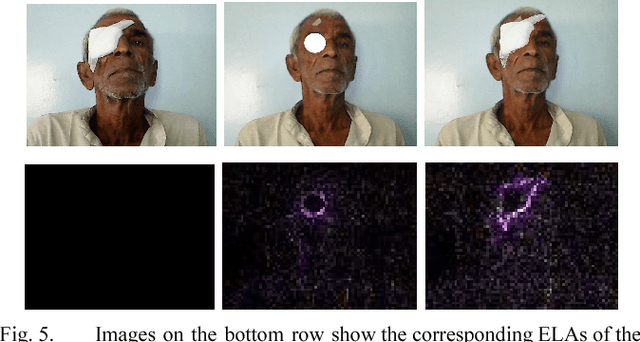
Although modern face verification systems are accessible and accurate, they are not always robust to pose variance and occlusions. Moreover, accurate models require a large amount of data to train. We structure our experiments to operate on small amounts of data obtained from an NGO that funds ophthalmic surgeries. We set up our face verification task as that of verifying pre-operation and post-operation images of a patient that undergoes ophthalmic surgery, and as such the post-operation images have occlusions like an eye patch. In this paper, we present a system that performs the face verification task using one-shot learning. To this end, our paper uses deep convolutional networks and compares different model architectures and loss functions. Our best model achieves 85% test accuracy. During inference time, we also attempt to detect image forgeries in addition to performing face verification. To achieve this, we use Error Level Analysis. Finally, we propose an inference pipeline that demonstrates how these techniques can be used to implement an automated face verification and forgery detection system.