 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicVoices-R: Unlocking a Massive Multilingual Multi-speaker Speech Corpus for Scaling Indian TTS
Sep 09, 2024



Recent advancements in text-to-speech (TTS) synthesis show that large-scale models trained with extensive web data produce highly natural-sounding output. However, such data is scarce for Indian languages due to the lack of high-quality, manually subtitled data on platforms like LibriVox or YouTube. To address this gap, we enhance existing large-scale ASR datasets containing natural conversations collected in low-quality environments to generate high-quality TTS training data. Our pipeline leverages the cross-lingual generalization of denoising and speech enhancement models trained on English and applied to Indian languages. This results in IndicVoices-R (IV-R), the largest multilingual Indian TTS dataset derived from an ASR dataset, with 1,704 hours of high-quality speech from 10,496 speakers across 22 Indian languages. IV-R matches the quality of gold-standard TTS datasets like LJSpeech, LibriTTS, and IndicTTS. We also introduce the IV-R Benchmark, the first to assess zero-shot, few-shot, and many-shot speaker generalization capabilities of TTS models on Indian voices, ensuring diversity in age, gender, and style. We demonstrate that fine-tuning an English pre-trained model on a combined dataset of high-quality IndicTTS and our IV-R dataset results in better zero-shot speaker generalization compared to fine-tuning on the IndicTTS dataset alone. Further, our evaluation reveals limited zero-shot generalization for Indian voices in TTS models trained on prior datasets, which we improve by fine-tuning the model on our data containing diverse set of speakers across language families. We open-source all data and code, releasing the first TTS model for all 22 official Indian languages.
Empowering Low-Resource Language ASR via Large-Scale Pseudo Labeling
Aug 26, 2024



In this study, we tackle the challenge of limited labeled data for low-resource languages in ASR, focusing on Hindi. Specifically, we explore pseudo-labeling, by proposing a generic framework combining multiple ideas from existing works. Our framework integrates multiple base models for transcription and evaluators for assessing audio-transcript pairs, resulting in robust pseudo-labeling for low resource languages. We validate our approach with a new benchmark, IndicYT, comprising diverse YouTube audio files from multiple content categories. Our findings show that augmenting pseudo labeled data from YouTube with existing training data leads to significant performance improvements on IndicYT, without affecting performance on out-of-domain benchmarks, demonstrating the efficacy of pseudo-labeled data in enhancing ASR capabilities for low-resource languages. The benchmark, code and models developed as a part of this work will be made publicly available.
LAHAJA: A Robust Multi-accent Benchmark for Evaluating Hindi ASR Systems
Aug 21, 2024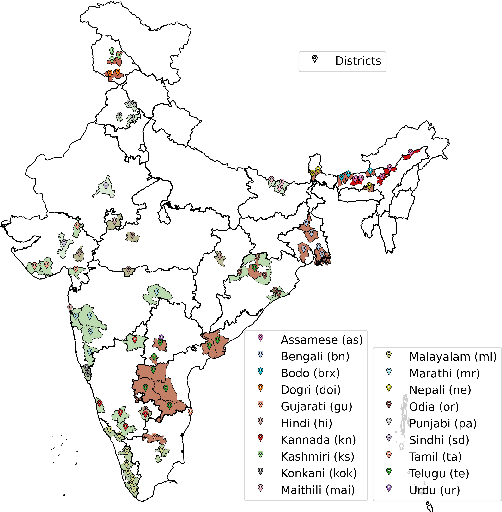

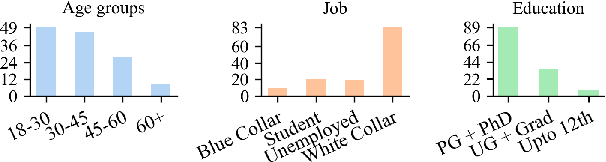

Hindi, one of the most spoken language of India, exhibits a diverse array of accents due to its usage among individuals from diverse linguistic origins. To enable a robust evaluation of Hindi ASR systems on multiple accents, we create a benchmark, LAHAJA, which contains read and extempore speech on a diverse set of topics and use cases, with a total of 12.5 hours of Hindi audio, sourced from 132 speakers spanning 83 districts of India. We evaluate existing open-source and commercial models on LAHAJA and find their performance to be poor. We then train models using different datasets and find that our model trained on multilingual data with good speaker diversity outperforms existing models by a significant margin. We also present a fine-grained analysis which shows that the performance declines for speakers from North-East and South India, especially with content heavy in named entities and specialized terminology.
IndicVoices: Towards building an Inclusive Multilingual Speech Dataset for Indian Languages
Mar 04, 2024We present INDICVOICES, a dataset of natural and spontaneous speech containing a total of 7348 hours of read (9%), extempore (74%) and conversational (17%) audio from 16237 speakers covering 145 Indian districts and 22 languages. Of these 7348 hours, 1639 hours have already been transcribed, with a median of 73 hours per language. Through this paper, we share our journey of capturing the cultural, linguistic and demographic diversity of India to create a one-of-its-kind inclusive and representative dataset. More specifically, we share an open-source blueprint for data collection at scale comprising of standardised protocols, centralised tools, a repository of engaging questions, prompts and conversation scenarios spanning multiple domains and topics of interest, quality control mechanisms, comprehensive transcription guidelines and transcription tools. We hope that this open source blueprint will serve as a comprehensive starter kit for data collection efforts in other multilingual regions of the world. Using INDICVOICES, we build IndicASR, the first ASR model to support all the 22 languages listed in the 8th schedule of the Constitution of India. All the data, tools, guidelines, models and other materials developed as a part of this work will be made publicly available