 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAHAJA: A Robust Multi-accent Benchmark for Evaluating Hindi ASR Systems
Aug 21, 2024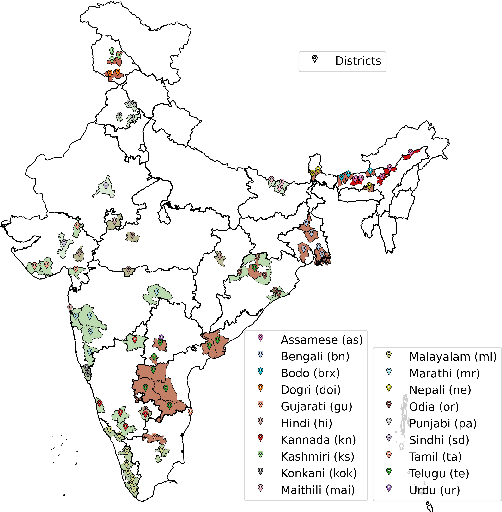


Hindi, one of the most spoken language of India, exhibits a diverse array of accents due to its usage among individuals from diverse linguistic origins. To enable a robust evaluation of Hindi ASR systems on multiple accents, we create a benchmark, LAHAJA, which contains read and extempore speech on a diverse set of topics and use cases, with a total of 12.5 hours of Hindi audio, sourced from 132 speakers spanning 83 districts of India. We evaluate existing open-source and commercial models on LAHAJA and find their performance to be poor. We then train models using different datasets and find that our model trained on multilingual data with good speaker diversity outperforms existing models by a significant margin. We also present a fine-grained analysis which shows that the performance declines for speakers from North-East and South India, especially with content heavy in named entities and specialized terminology.
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages
May 25, 2023India has a rich linguistic landscape with languages from 4 major language families spoken by over a billion people. 22 of these languages are listed in the Constitution of India (referred to as scheduled languages) are the focus of this work. Given the linguistic diversity, high-quality and accessible Machine Translation (MT) systems are essential in a country like India. Prior to this work, there was (i) no parallel training data spanning all the 22 languages, (ii) no robust benchmarks covering all these languages and containing content relevant to India, and (iii) no existing translation models which support all the 22 scheduled languages of India. In this work, we aim to address this gap by focusing on the missing pieces required for enabling wide, easy, and open access to good machine translation systems for all 22 scheduled Indian languages. We identify four key areas of improvement: curating and creating larger training datasets, creating diverse and high-quality benchmarks, training multilingual models, and releasing models with open access. Our first contribution is the release of the Bharat Parallel Corpus Collection (BPCC), the largest publicly available parallel corpora for Indic languages. BPCC contains a total of 230M bitext pairs, of which a total of 126M were newly added, including 644K manually translated sentence pairs created as part of this work. Our second contribution is the release of the first n-way parallel benchmark covering all 22 Indian languages, featuring diverse domains, Indian-origin content, and source-original test sets. Next, we present IndicTrans2, the first model to support all 22 languages, surpassing existing models on multiple existing and new benchmarks created as a part of this work. Lastly, to promote accessibility and collaboration, we release our models and associated data with permissive licenses at https://github.com/ai4bharat/IndicTrans2.
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023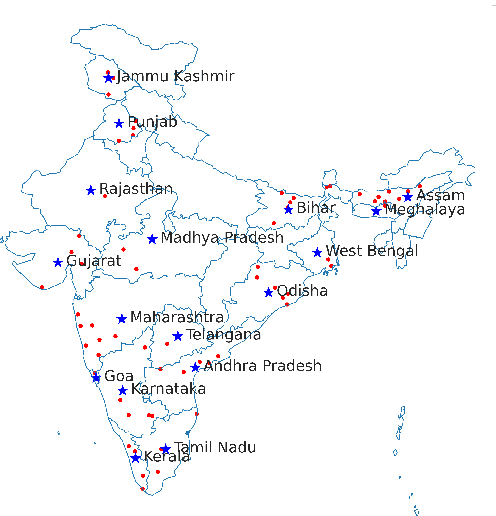
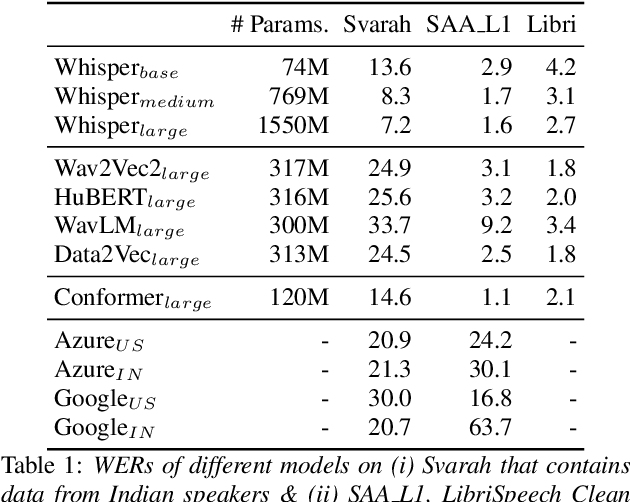
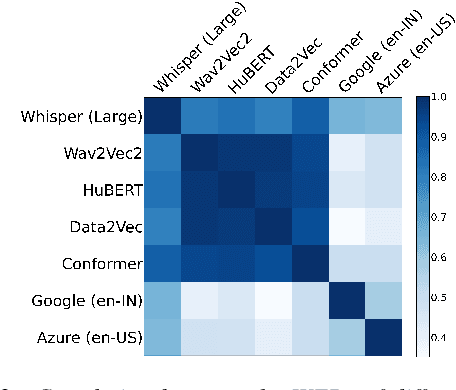
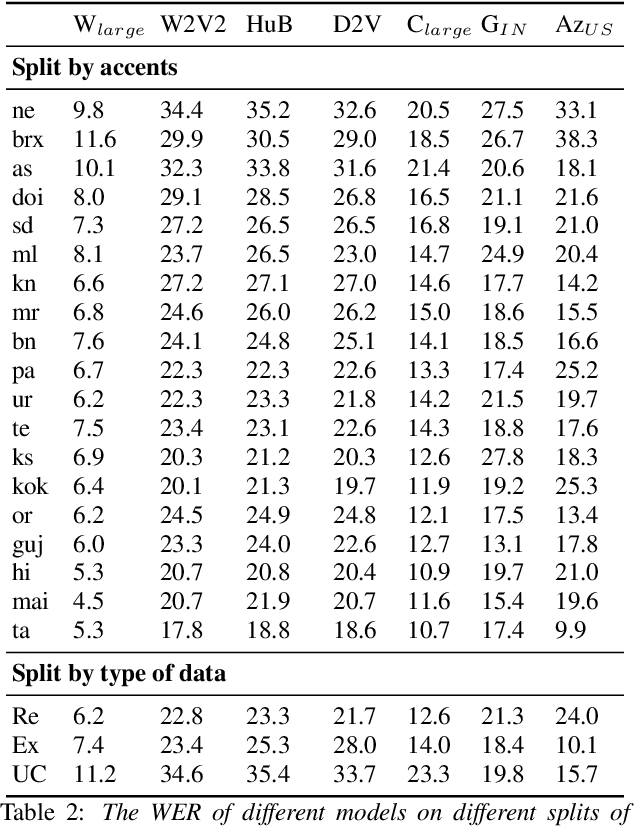
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.