 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRomanSetu: Efficiently unlocking multilingual capabilities of Large Language Models models via Romanization
Jan 25, 2024This study addresses the challenge of extending Large Language Models (LLMs) to non-English languages, specifically those using non-Latin scripts. We propose an innovative approach that utilizes the romanized form of text as an interface for LLMs, hypothesizing that its frequent informal use and shared tokens with English enhance cross-lingual alignment. Focusing on Hindi, we demonstrate through Hindi-to-English translation and sentiment analysis tasks that romanized text not only significantly improves inference efficiency due to its lower fertility compared to native text but also achieves competitive performance with limited pre-training. Additionally, our novel multi-script prompting approach, which combines romanized and native texts, shows promise in further enhancing task performance. These findings suggest the potential of romanization in bridging the language gap for LLM applications, with future work aimed at expanding this approach to more languages and tasks.
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages
May 25, 2023India has a rich linguistic landscape with languages from 4 major language families spoken by over a billion people. 22 of these languages are listed in the Constitution of India (referred to as scheduled languages) are the focus of this work. Given the linguistic diversity, high-quality and accessible Machine Translation (MT) systems are essential in a country like India. Prior to this work, there was (i) no parallel training data spanning all the 22 languages, (ii) no robust benchmarks covering all these languages and containing content relevant to India, and (iii) no existing translation models which support all the 22 scheduled languages of India. In this work, we aim to address this gap by focusing on the missing pieces required for enabling wide, easy, and open access to good machine translation systems for all 22 scheduled Indian languages. We identify four key areas of improvement: curating and creating larger training datasets, creating diverse and high-quality benchmarks, training multilingual models, and releasing models with open access. Our first contribution is the release of the Bharat Parallel Corpus Collection (BPCC), the largest publicly available parallel corpora for Indic languages. BPCC contains a total of 230M bitext pairs, of which a total of 126M were newly added, including 644K manually translated sentence pairs created as part of this work. Our second contribution is the release of the first n-way parallel benchmark covering all 22 Indian languages, featuring diverse domains, Indian-origin content, and source-original test sets. Next, we present IndicTrans2, the first model to support all 22 languages, surpassing existing models on multiple existing and new benchmarks created as a part of this work. Lastly, to promote accessibility and collaboration, we release our models and associated data with permissive licenses at https://github.com/ai4bharat/IndicTrans2.
In-context Example Selection for Machine Translation Using Multiple Features
May 23, 2023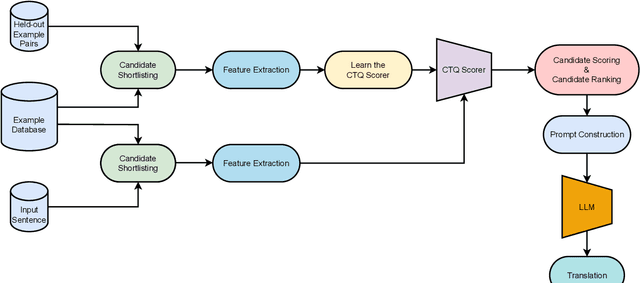
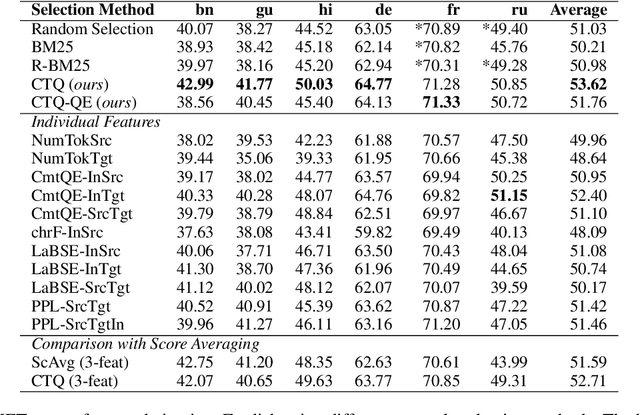
Large language models have demonstrated the capability to perform well on many NLP tasks when the input is prompted with a few examples (in-context learning) including machine translation, which is the focus of this work. The quality of translation depends on various features of the selected examples, such as their quality and relevance. However, previous work has predominantly focused on individual features for example selection. We propose a general framework for combining different features influencing example selection. We learn a regression function that selects examples based on multiple features in order to maximize the translation quality. On multiple language pairs and language models, we show that our example selection method significantly outperforms random selection as well as strong single-factor baselines reported in the literature. Using our example selection method, we see an improvement of over 2.5 COMET points on average with respect to a strong BM25 retrieval-based baseline.