 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interchangeability of Positional Embeddings in Multilingual Neural Machine Translation Models
Aug 21, 2024Standard Neural Machine Translation (NMT) models have traditionally been trained with Sinusoidal Positional Embeddings (PEs), which are inadequate for capturing long-range dependencies and are inefficient for long-context or document-level translation. In contrast, state-of-the-art large language models (LLMs) employ relative PEs, demonstrating superior length generalization. This work explores the potential for efficiently switching the Positional Embeddings of pre-trained NMT models from absolute sinusoidal PEs to relative approaches such as RoPE and ALiBi. Our findings reveal that sinusoidal PEs can be effectively replaced with RoPE and ALiBi with negligible or no performance loss, achieved by fine-tuning on a small fraction of high-quality data. Additionally, models trained without Positional Embeddings (NoPE) are not a viable solution for Encoder-Decoder architectures, as they consistently under-perform compared to models utilizing any form of Positional Embedding. Furthermore, even a model trained from scratch with these relative PEs slightly under-performs a fine-tuned model, underscoring the efficiency and validity of our hypothesis.
An Empirical Analysis of In-context Learning Abilities of LLMs for MT
Jan 22, 2024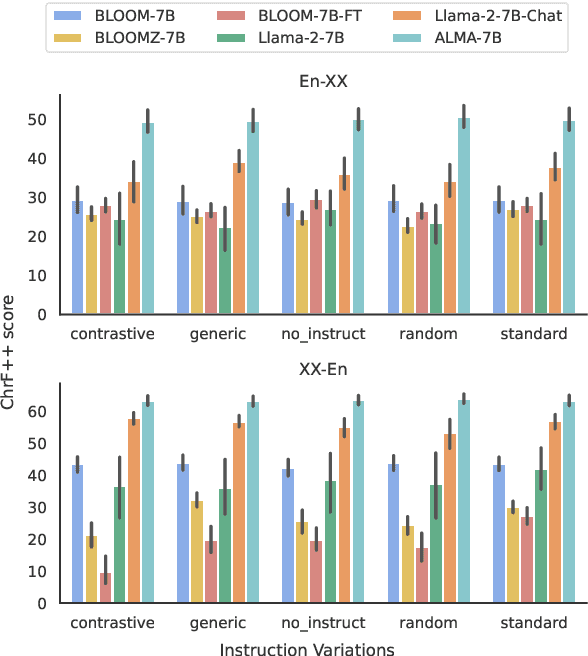
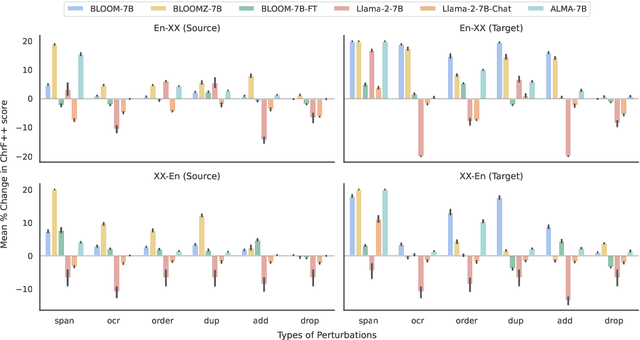
In-context learning (ICL) has consistently demonstrated superior performance over zero-shot performance in large language models (LLMs). However, the understanding of the dynamics of ICL and the aspects that influence downstream performance remains limited, especially for natural language generation (NLG) tasks. This work aims to address this gap by investigating the ICL capabilities of LLMs and studying the impact of different aspects of the in-context demonstrations for the task of machine translation (MT). Our preliminary investigations aim to discern whether in-context learning (ICL) is predominantly influenced by demonstrations or instructions by applying diverse perturbations to in-context demonstrations while preserving the task instruction. We observe varying behavior to perturbed examples across different model families, notably with BLOOM-7B derivatives being severely influenced by noise, whereas Llama 2 derivatives not only exhibit robustness but also tend to show enhancements over the clean baseline when subject to perturbed demonstrations. This suggests that the robustness of ICL may be governed by several factors, including the type of noise, perturbation direction (source or target), the extent of pretraining of the specific model, and fine-tuning for downstream tasks if applicable. Further investigation is warranted to develop a comprehensive understanding of these factors in future research.
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages
May 25, 2023India has a rich linguistic landscape with languages from 4 major language families spoken by over a billion people. 22 of these languages are listed in the Constitution of India (referred to as scheduled languages) are the focus of this work. Given the linguistic diversity, high-quality and accessible Machine Translation (MT) systems are essential in a country like India. Prior to this work, there was (i) no parallel training data spanning all the 22 languages, (ii) no robust benchmarks covering all these languages and containing content relevant to India, and (iii) no existing translation models which support all the 22 scheduled languages of India. In this work, we aim to address this gap by focusing on the missing pieces required for enabling wide, easy, and open access to good machine translation systems for all 22 scheduled Indian languages. We identify four key areas of improvement: curating and creating larger training datasets, creating diverse and high-quality benchmarks, training multilingual models, and releasing models with open access. Our first contribution is the release of the Bharat Parallel Corpus Collection (BPCC), the largest publicly available parallel corpora for Indic languages. BPCC contains a total of 230M bitext pairs, of which a total of 126M were newly added, including 644K manually translated sentence pairs created as part of this work. Our second contribution is the release of the first n-way parallel benchmark covering all 22 Indian languages, featuring diverse domains, Indian-origin content, and source-original test sets. Next, we present IndicTrans2, the first model to support all 22 languages, surpassing existing models on multiple existing and new benchmarks created as a part of this work. Lastly, to promote accessibility and collaboration, we release our models and associated data with permissive licenses at https://github.com/ai4bharat/IndicTrans2.