 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of In-context Learning Abilities of LLMs for MT
Paper and Code
Jan 22, 2024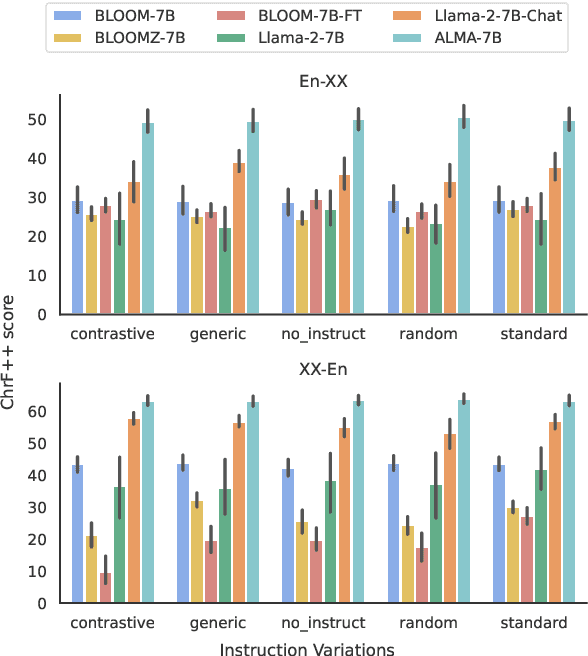
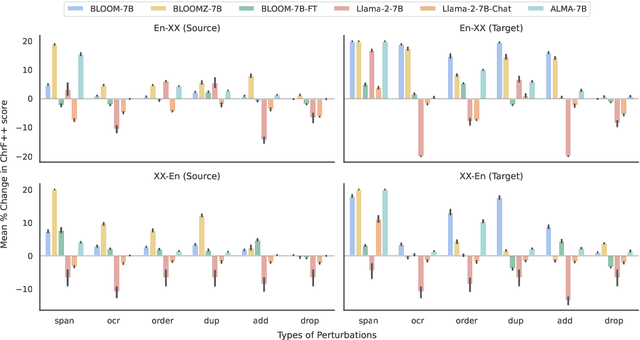
In-context learning (ICL) has consistently demonstrated superior performance over zero-shot performance in large language models (LLMs). However, the understanding of the dynamics of ICL and the aspects that influence downstream performance remains limited, especially for natural language generation (NLG) tasks. This work aims to address this gap by investigating the ICL capabilities of LLMs and studying the impact of different aspects of the in-context demonstrations for the task of machine translation (MT). Our preliminary investigations aim to discern whether in-context learning (ICL) is predominantly influenced by demonstrations or instructions by applying diverse perturbations to in-context demonstrations while preserving the task instruction. We observe varying behavior to perturbed examples across different model families, notably with BLOOM-7B derivatives being severely influenced by noise, whereas Llama 2 derivatives not only exhibit robustness but also tend to show enhancements over the clean baseline when subject to perturbed demonstrations. This suggests that the robustness of ICL may be governed by several factors, including the type of noise, perturbation direction (source or target), the extent of pretraining of the specific model, and fine-tuning for downstream tasks if applicable. Further investigation is warranted to develop a comprehensive understanding of these factors in future research.