 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-context Example Selection for Machine Translation Using Multiple Features
Paper and Code
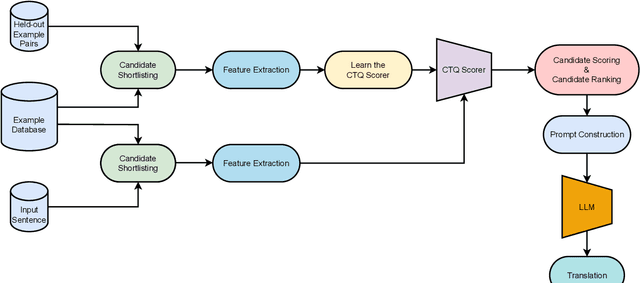
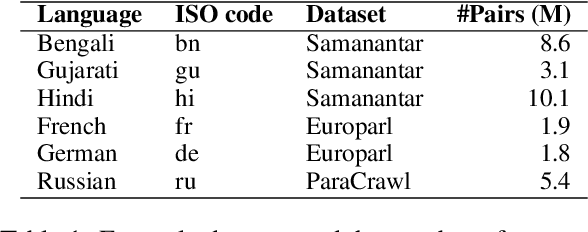
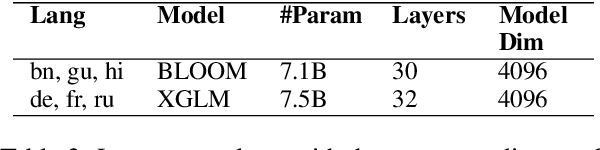
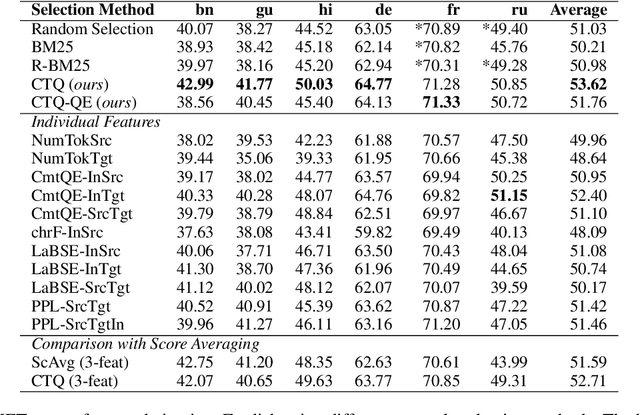
Large language models have demonstrated the capability to perform well on many NLP tasks when the input is prompted with a few examples (in-context learning) including machine translation, which is the focus of this work. The quality of translation depends on various features of the selected examples, such as their quality and relevance. However, previous work has predominantly focused on individual features for example selection. We propose a general framework for combining different features influencing example selection. We learn a regression function that selects examples based on multiple features in order to maximize the translation quality. On multiple language pairs and language models, we show that our example selection method significantly outperforms random selection as well as strong single-factor baselines reported in the literature. Using our example selection method, we see an improvement of over 2.5 COMET points on average with respect to a strong BM25 retrieval-based baseline.