 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSvarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023
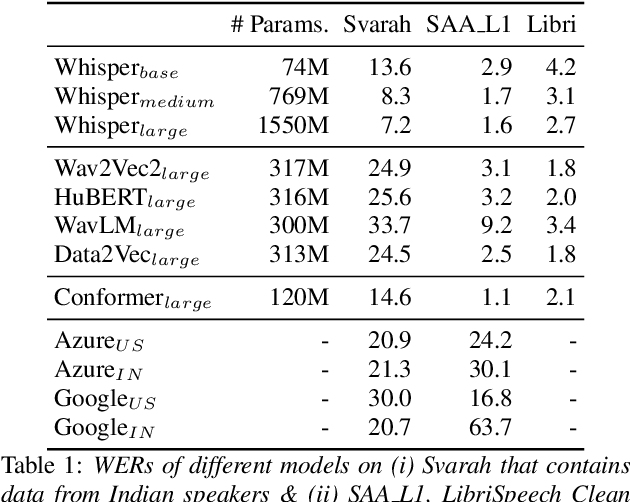
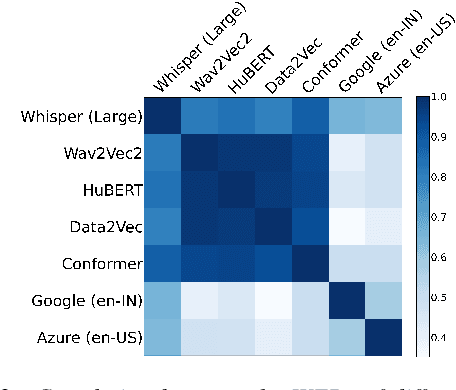
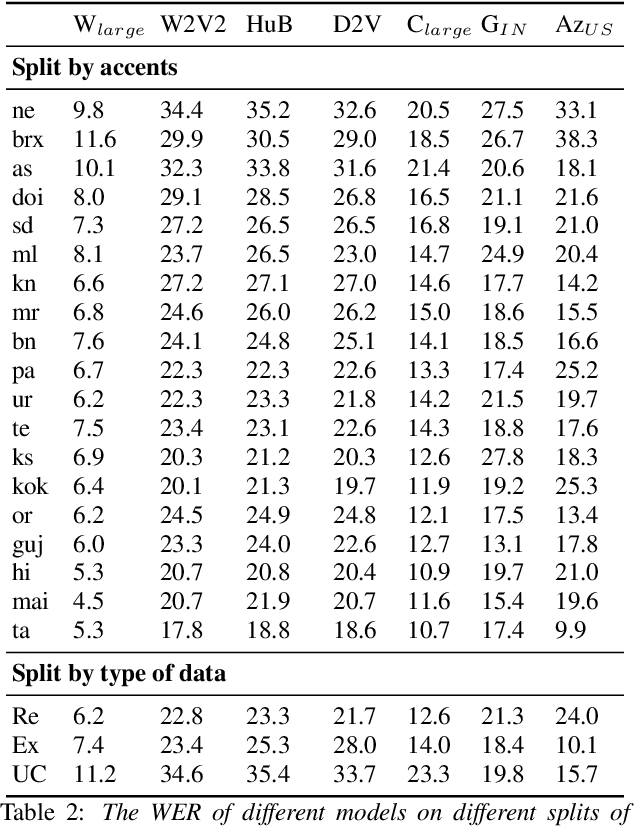
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
Vistaar: Diverse Benchmarks and Training Sets for Indian Language ASR
May 24, 2023Improving ASR systems is necessary to make new LLM-based use-cases accessible to people across the globe. In this paper, we focus on Indian languages, and make the case that diverse benchmarks are required to evaluate and improve ASR systems for Indian languages. To address this, we collate Vistaar as a set of 59 benchmarks across various language and domain combinations, on which we evaluate 3 publicly available ASR systems and 2 commercial systems. We also train IndicWhisper models by fine-tuning the Whisper models on publicly available training datasets across 12 Indian languages totalling to 10.7K hours. We show that IndicWhisper significantly improves on considered ASR systems on the Vistaar benchmark. Indeed, IndicWhisper has the lowest WER in 39 out of the 59 benchmarks, with an average reduction of 4.1 WER. We open-source all datasets, code and models.