 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Every Voice: Towards Inclusive ASR for Rural Bhojpuri Women
Jun 11, 2025Digital inclusion remains a challenge for marginalized communities, especially rural women in low-resource language regions like Bhojpuri. Voice-based access to agricultural services, financial transactions, government schemes, and healthcare is vital for their empowerment, yet existing ASR systems for this group remain largely untested. To address this gap, we create SRUTI ,a benchmark consisting of rural Bhojpuri women speakers. Evaluation of current ASR models on SRUTI shows poor performance due to data scarcity, which is difficult to overcome due to social and cultural barriers that hinder large-scale data collection. To overcome this, we propose generating synthetic speech using just 25-30 seconds of audio per speaker from approximately 100 rural women. Augmenting existing datasets with this synthetic data achieves an improvement of 4.7 WER, providing a scalable, minimally intrusive solution to enhance ASR and promote digital inclusion in low-resource language.
Empowering Low-Resource Language ASR via Large-Scale Pseudo Labeling
Aug 26, 2024



In this study, we tackle the challenge of limited labeled data for low-resource languages in ASR, focusing on Hindi. Specifically, we explore pseudo-labeling, by proposing a generic framework combining multiple ideas from existing works. Our framework integrates multiple base models for transcription and evaluators for assessing audio-transcript pairs, resulting in robust pseudo-labeling for low resource languages. We validate our approach with a new benchmark, IndicYT, comprising diverse YouTube audio files from multiple content categories. Our findings show that augmenting pseudo labeled data from YouTube with existing training data leads to significant performance improvements on IndicYT, without affecting performance on out-of-domain benchmarks, demonstrating the efficacy of pseudo-labeled data in enhancing ASR capabilities for low-resource languages. The benchmark, code and models developed as a part of this work will be made publicly available.
LAHAJA: A Robust Multi-accent Benchmark for Evaluating Hindi ASR Systems
Aug 21, 2024


Hindi, one of the most spoken language of India, exhibits a diverse array of accents due to its usage among individuals from diverse linguistic origins. To enable a robust evaluation of Hindi ASR systems on multiple accents, we create a benchmark, LAHAJA, which contains read and extempore speech on a diverse set of topics and use cases, with a total of 12.5 hours of Hindi audio, sourced from 132 speakers spanning 83 districts of India. We evaluate existing open-source and commercial models on LAHAJA and find their performance to be poor. We then train models using different datasets and find that our model trained on multilingual data with good speaker diversity outperforms existing models by a significant margin. We also present a fine-grained analysis which shows that the performance declines for speakers from North-East and South India, especially with content heavy in named entities and specialized terminology.
IndicVoices: Towards building an Inclusive Multilingual Speech Dataset for Indian Languages
Mar 04, 2024We present INDICVOICES, a dataset of natural and spontaneous speech containing a total of 7348 hours of read (9%), extempore (74%) and conversational (17%) audio from 16237 speakers covering 145 Indian districts and 22 languages. Of these 7348 hours, 1639 hours have already been transcribed, with a median of 73 hours per language. Through this paper, we share our journey of capturing the cultural, linguistic and demographic diversity of India to create a one-of-its-kind inclusive and representative dataset. More specifically, we share an open-source blueprint for data collection at scale comprising of standardised protocols, centralised tools, a repository of engaging questions, prompts and conversation scenarios spanning multiple domains and topics of interest, quality control mechanisms, comprehensive transcription guidelines and transcription tools. We hope that this open source blueprint will serve as a comprehensive starter kit for data collection efforts in other multilingual regions of the world. Using INDICVOICES, we build IndicASR, the first ASR model to support all the 22 languages listed in the 8th schedule of the Constitution of India. All the data, tools, guidelines, models and other materials developed as a part of this work will be made publicly available
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023
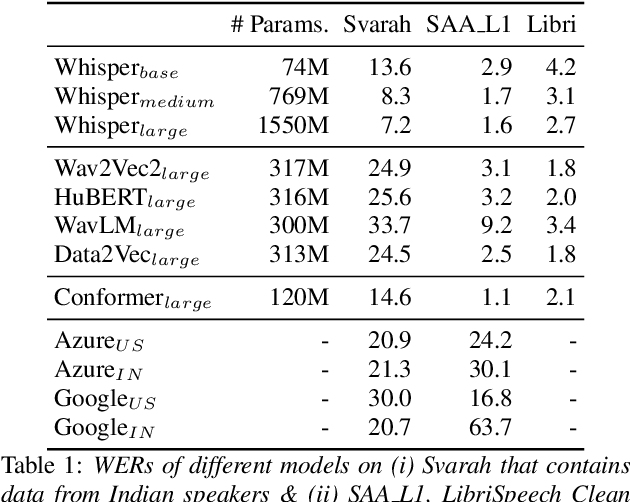
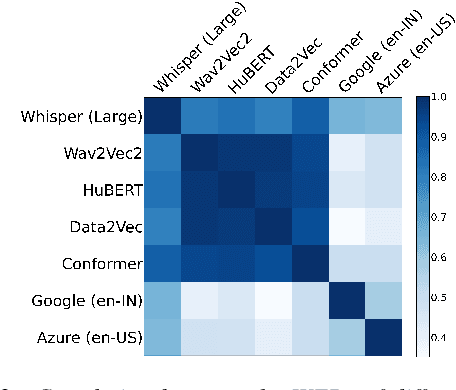
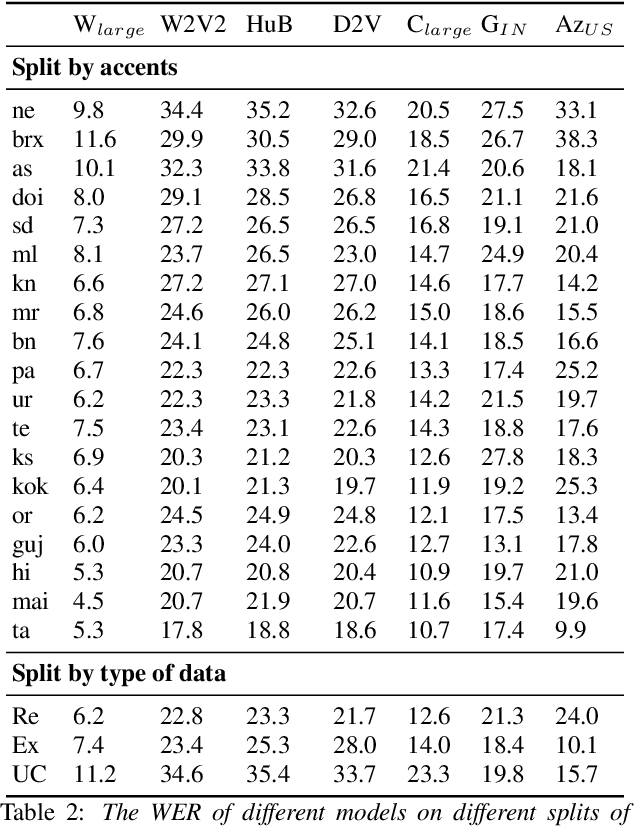
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
Vistaar: Diverse Benchmarks and Training Sets for Indian Language ASR
May 24, 2023Improving ASR systems is necessary to make new LLM-based use-cases accessible to people across the globe. In this paper, we focus on Indian languages, and make the case that diverse benchmarks are required to evaluate and improve ASR systems for Indian languages. To address this, we collate Vistaar as a set of 59 benchmarks across various language and domain combinations, on which we evaluate 3 publicly available ASR systems and 2 commercial systems. We also train IndicWhisper models by fine-tuning the Whisper models on publicly available training datasets across 12 Indian languages totalling to 10.7K hours. We show that IndicWhisper significantly improves on considered ASR systems on the Vistaar benchmark. Indeed, IndicWhisper has the lowest WER in 39 out of the 59 benchmarks, with an average reduction of 4.1 WER. We open-source all datasets, code and models.
Effectiveness of Mining Audio and Text Pairs from Public Data for Improving ASR Systems for Low-Resource Languages
Aug 26, 2022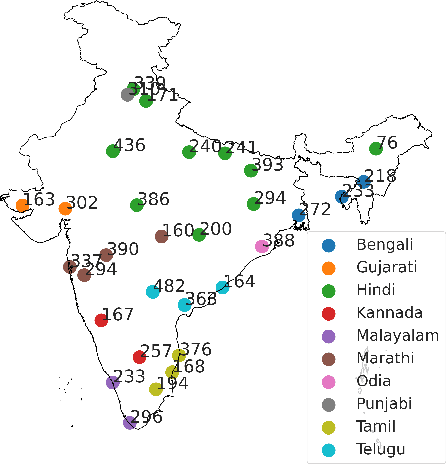
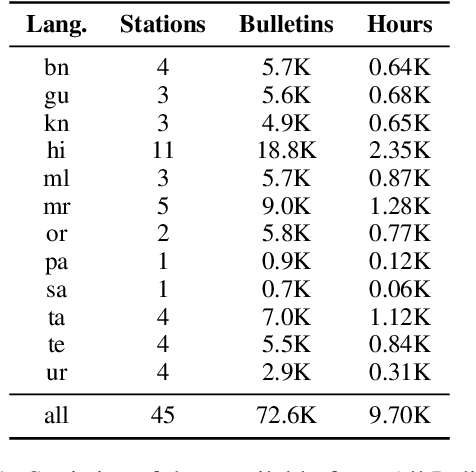

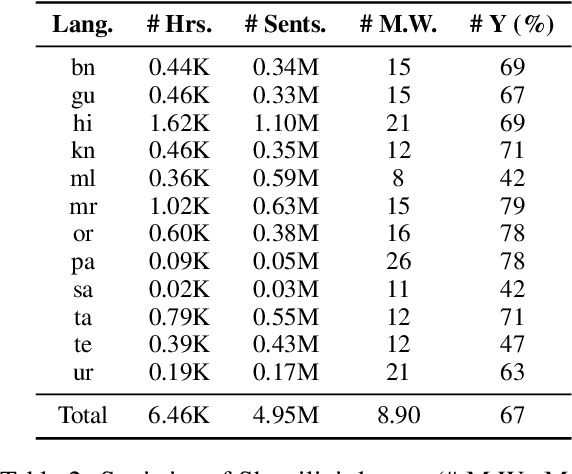
End-to-end (E2E) models have become the default choice for state-of-the-art speech recognition systems. Such models are trained on large amounts of labelled data, which are often not available for low-resource languages. Techniques such as self-supervised learning and transfer learning hold promise, but have not yet been effective in training accurate models. On the other hand, collecting labelled datasets on a diverse set of domains and speakers is very expensive. In this work, we demonstrate an inexpensive and effective alternative to these approaches by ``mining'' text and audio pairs for Indian languages from public sources, specifically from the public archives of All India Radio. As a key component, we adapt the Needleman-Wunsch algorithm to align sentences with corresponding audio segments given a long audio and a PDF of its transcript, while being robust to errors due to OCR, extraneous text, and non-transcribed speech. We thus create Shrutilipi, a dataset which contains over 6,400 hours of labelled audio across 12 Indian languages totalling to 4.95M sentences. On average, Shrutilipi results in a 2.3x increase over publicly available labelled data. We establish the quality of Shrutilipi with 21 human evaluators across the 12 languages. We also establish the diversity of Shrutilipi in terms of represented regions, speakers, and mentioned named entities. Significantly, we show that adding Shrutilipi to the training set of Wav2Vec models leads to an average decrease in WER of 5.8\% for 7 languages on the IndicSUPERB benchmark. For Hindi, which has the most benchmarks (7), the average WER falls from 18.8% to 13.5%. This improvement extends to efficient models: We show a 2.3% drop in WER for a Conformer model (10x smaller than Wav2Vec). Finally, we demonstrate the diversity of Shrutilipi by showing that the model trained with it is more robust to noisy input.
IndicSUPERB: A Speech Processing Universal Performance Benchmark for Indian languages
Aug 24, 2022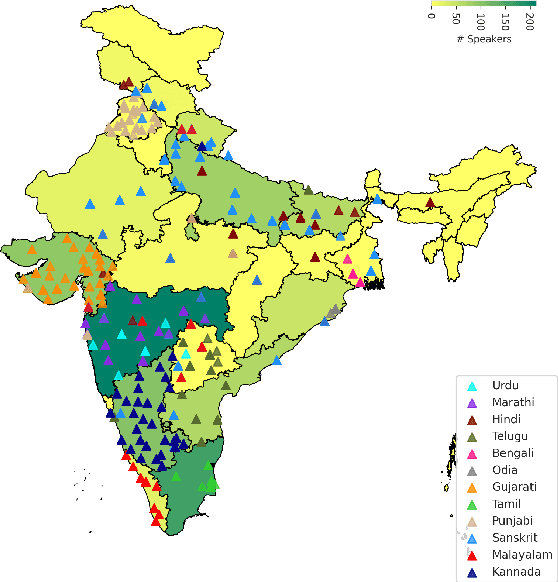
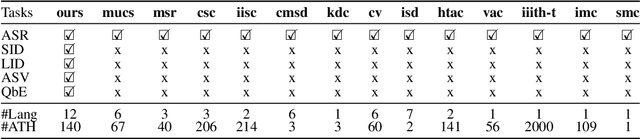

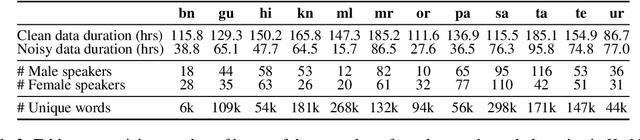
A cornerstone in AI research has been the creation and adoption of standardized training and test datasets to earmark the progress of state-of-the-art models. A particularly successful example is the GLUE dataset for training and evaluating Natural Language Understanding (NLU) models for English. The large body of research around self-supervised BERT-based language models revolved around performance improvements on NLU tasks in GLUE. To evaluate language models in other languages, several language-specific GLUE datasets were created. The area of speech language understanding (SLU) has followed a similar trajectory. The success of large self-supervised models such as wav2vec2 enable creation of speech models with relatively easy to access unlabelled data. These models can then be evaluated on SLU tasks, such as the SUPERB benchmark. In this work, we extend this to Indic languages by releasing the IndicSUPERB benchmark. Specifically, we make the following three contributions. (i) We collect Kathbath containing 1,684 hours of labelled speech data across 12 Indian languages from 1,218 contributors located in 203 districts in India. (ii) Using Kathbath, we create benchmarks across 6 speech tasks: Automatic Speech Recognition, Speaker Verification, Speaker Identification (mono/multi), Language Identification, Query By Example, and Keyword Spotting for 12 languages. (iii) On the released benchmarks, we train and evaluate different self-supervised models alongside a commonly used baseline FBANK. We show that language-specific fine-tuned models are more accurate than baseline on most of the tasks, including a large gap of 76\% for the Language Identification task. However, for speaker identification, self-supervised models trained on large datasets demonstrate an advantage. We hope IndicSUPERB contributes to the progress of developing speech language understanding models for Indian languages.
Towards Building ASR Systems for the Next Billion Users
Nov 12, 2021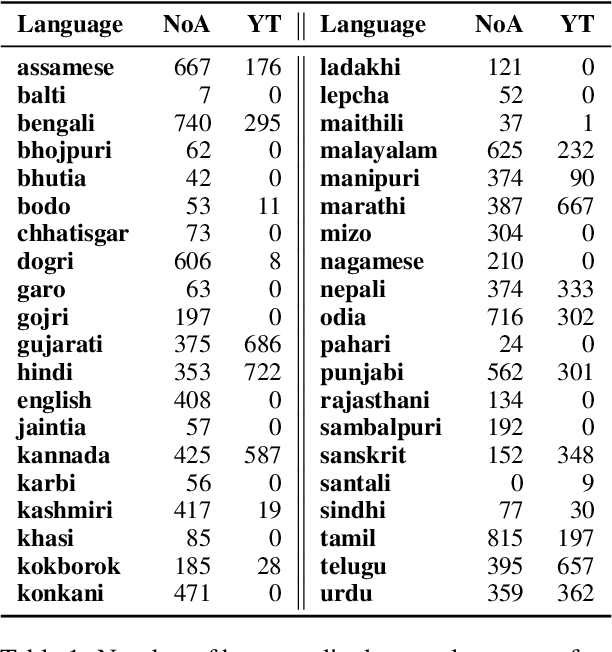
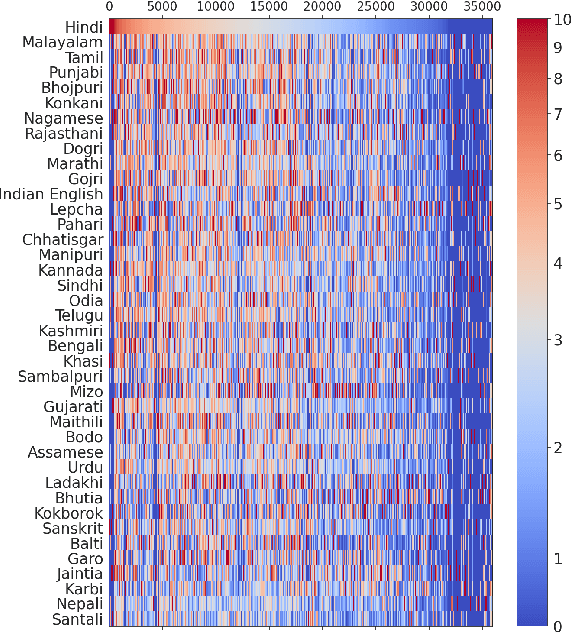
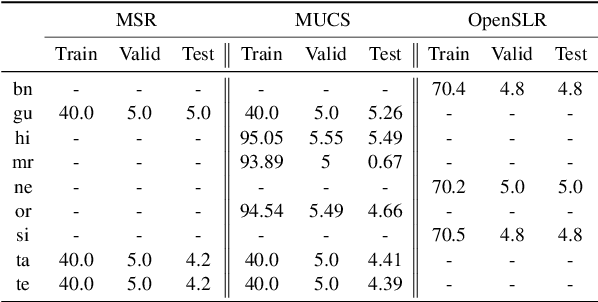
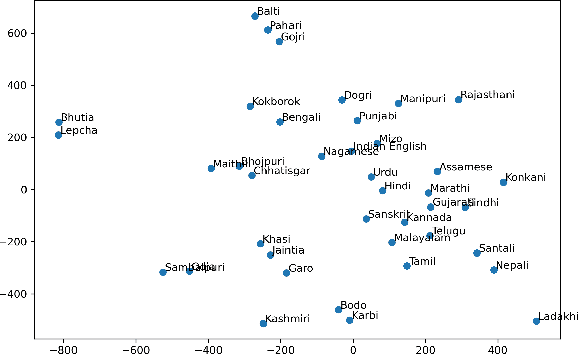
Recent methods in speech and language technology pretrain very LARGE models which are fine-tuned for specific tasks. However, the benefits of such LARGE models are often limited to a few resource rich languages of the world. In this work, we make multiple contributions towards building ASR systems for low resource languages from the Indian subcontinent. First, we curate 17,000 hours of raw speech data for 40 Indian languages from a wide variety of domains including education, news, technology, and finance. Second, using this raw speech data we pretrain several variants of wav2vec style models for 40 Indian languages. Third, we analyze the pretrained models to find key features: codebook vectors of similar sounding phonemes are shared across languages, representations across layers are discriminative of the language family, and attention heads often pay attention within small local windows. Fourth, we fine-tune this model for downstream ASR for 9 languages and obtain state-of-the-art results on 3 public datasets, including on very low-resource languages such as Sinhala and Nepali. Our work establishes that multilingual pretraining is an effective strategy for building ASR systems for the linguistically diverse speakers of the Indian subcontinent.