 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSvarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023
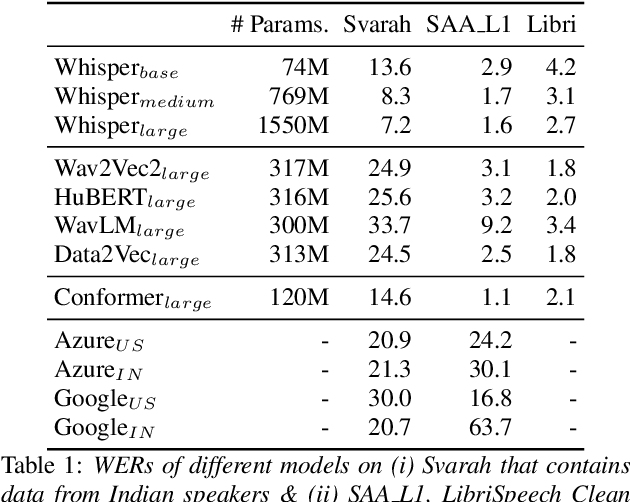
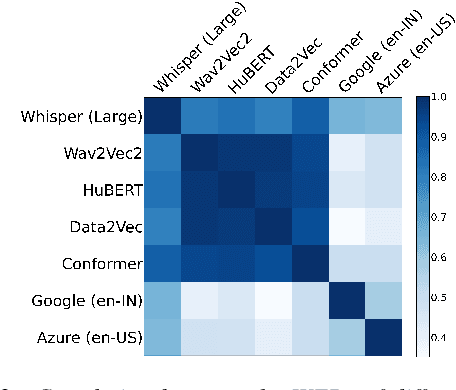
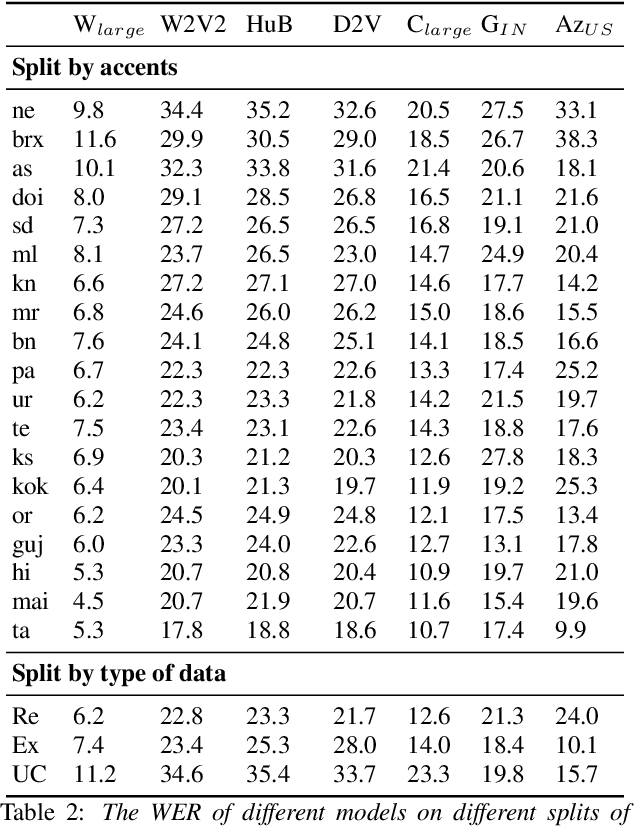
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.
IndicMT Eval: A Dataset to Meta-Evaluate Machine Translation metrics for Indian Languages
Dec 20, 2022



The rapid growth of machine translation (MT) systems has necessitated comprehensive studies to meta-evaluate evaluation metrics being used, which enables a better selection of metrics that best reflect MT quality. Unfortunately, most of the research focuses on high-resource languages, mainly English, the observations for which may not always apply to other languages. Indian languages, having over a billion speakers, are linguistically different from English, and to date, there has not been a systematic study of evaluating MT systems from English into Indian languages. In this paper, we fill this gap by creating an MQM dataset consisting of 7000 fine-grained annotations, spanning 5 Indian languages and 7 MT systems, and use it to establish correlations between annotator scores and scores obtained using existing automatic metrics. Our results show that pre-trained metrics, such as COMET, have the highest correlations with annotator scores. Additionally, we find that the metrics do not adequately capture fluency-based errors in Indian languages, and there is a need to develop metrics focused on Indian languages. We hope that our dataset and analysis will help promote further research in this area.