 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETAIN: Interactive Tool for Regression Testing Guided LLM Migration
Sep 05, 2024



Large Language Models (LLMs) are increasingly integrated into diverse applications. The rapid evolution of LLMs presents opportunities for developers to enhance applications continuously. However, this constant adaptation can also lead to performance regressions during model migrations. While several interactive tools have been proposed to streamline the complexity of prompt engineering, few address the specific requirements of regression testing for LLM Migrations. To bridge this gap, we introduce RETAIN (REgression Testing guided LLM migrAtIoN), a tool designed explicitly for regression testing in LLM Migrations. RETAIN comprises two key components: an interactive interface tailored to regression testing needs during LLM migrations, and an error discovery module that facilitates understanding of differences in model behaviors. The error discovery module generates textual descriptions of various errors or differences between model outputs, providing actionable insights for prompt refinement. Our automatic evaluation and empirical user studies demonstrate that RETAIN, when compared to manual evaluation, enabled participants to identify twice as many errors, facilitated experimentation with 75% more prompts, and achieves 12% higher metric scores in a given time frame.
Improving Factuality of Abstractive Summarization without Sacrificing Summary Quality
May 24, 2023



Improving factual consistency of abstractive summarization has been a widely studied topic. However, most of the prior works on training factuality-aware models have ignored the negative effect it has on summary quality. We propose EFACTSUM (i.e., Effective Factual Summarization), a candidate summary generation and ranking technique to improve summary factuality without sacrificing summary quality. We show that using a contrastive learning framework with our refined candidate summaries leads to significant gains on both factuality and similarity-based metrics. Specifically, we propose a ranking strategy in which we effectively combine two metrics, thereby preventing any conflict during training. Models trained using our approach show up to 6 points of absolute improvement over the base model with respect to FactCC on XSUM and 11 points on CNN/DM, without negatively affecting either similarity-based metrics or absractiveness.
IndicMT Eval: A Dataset to Meta-Evaluate Machine Translation metrics for Indian Languages
Dec 20, 2022



The rapid growth of machine translation (MT) systems has necessitated comprehensive studies to meta-evaluate evaluation metrics being used, which enables a better selection of metrics that best reflect MT quality. Unfortunately, most of the research focuses on high-resource languages, mainly English, the observations for which may not always apply to other languages. Indian languages, having over a billion speakers, are linguistically different from English, and to date, there has not been a systematic study of evaluating MT systems from English into Indian languages. In this paper, we fill this gap by creating an MQM dataset consisting of 7000 fine-grained annotations, spanning 5 Indian languages and 7 MT systems, and use it to establish correlations between annotator scores and scores obtained using existing automatic metrics. Our results show that pre-trained metrics, such as COMET, have the highest correlations with annotator scores. Additionally, we find that the metrics do not adequately capture fluency-based errors in Indian languages, and there is a need to develop metrics focused on Indian languages. We hope that our dataset and analysis will help promote further research in this area.
CORE: A Retrieve-then-Edit Framework for Counterfactual Data Generation
Oct 10, 2022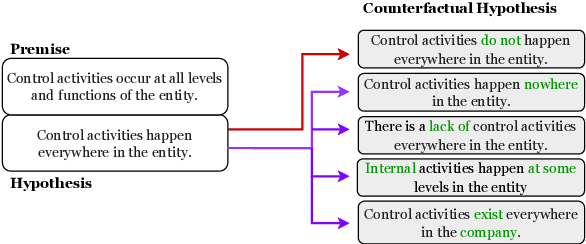

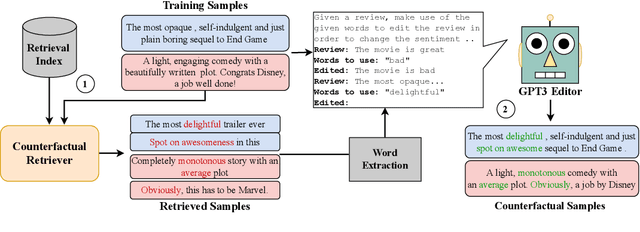
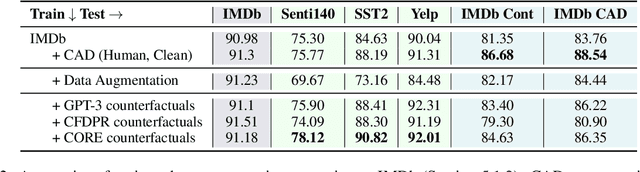
Counterfactual data augmentation (CDA) -- i.e., adding minimally perturbed inputs during training -- helps reduce model reliance on spurious correlations and improves generalization to out-of-distribution (OOD) data. Prior work on generating counterfactuals only considered restricted classes of perturbations, limiting their effectiveness. We present COunterfactual Generation via Retrieval and Editing (CORE), a retrieval-augmented generation framework for creating diverse counterfactual perturbations for CDA. For each training example, CORE first performs a dense retrieval over a task-related unlabeled text corpus using a learned bi-encoder and extracts relevant counterfactual excerpts. CORE then incorporates these into prompts to a large language model with few-shot learning capabilities, for counterfactual editing. Conditioning language model edits on naturally occurring data results in diverse perturbations. Experiments on natural language inference and sentiment analysis benchmarks show that CORE counterfactuals are more effective at improving generalization to OOD data compared to other DA approaches. We also show that the CORE retrieval framework can be used to encourage diversity in manually authored perturbations
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

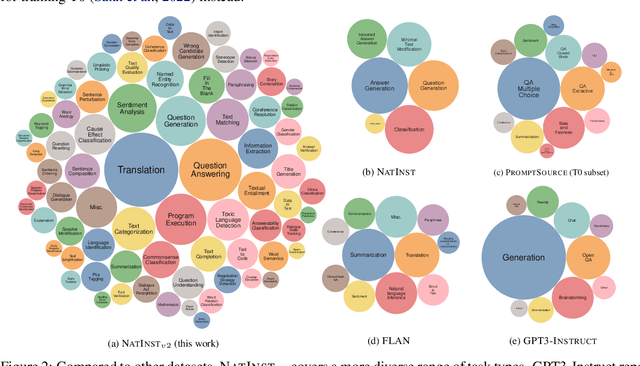
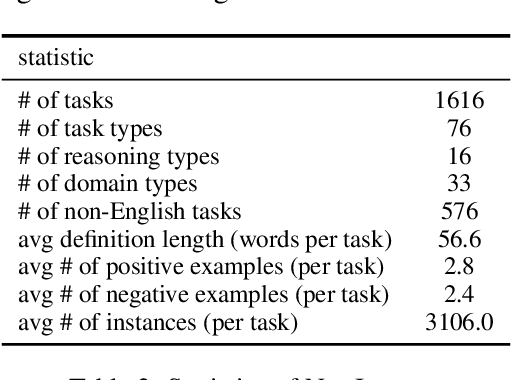
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
LatentGAN Autoencoder: Learning Disentangled Latent Distribution
Apr 05, 2022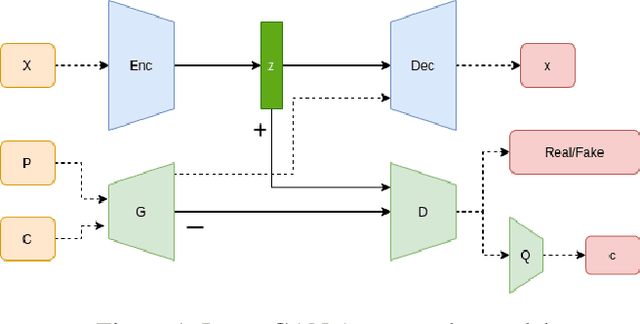
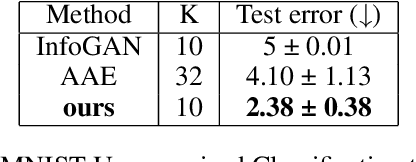


In autoencoder, the encoder generally approximates the latent distribution over the dataset, and the decoder generates samples using this learned latent distribution. There is very little control over the latent vector as using the random latent vector for generation will lead to trivial outputs. This work tries to address this issue by using the LatentGAN generator to directly learn to approximate the latent distribution of the autoencoder and show meaningful results on MNIST, 3D Chair, and CelebA datasets, an additional information-theoretic constrain is used which successfully learns to control autoencoder latent distribution. With this, our model also achieves an error rate of 2.38 on MNIST unsupervised image classification, which is better as compared to InfoGAN and AAE.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Perturbation CheckLists for Evaluating NLG Evaluation Metrics
Sep 13, 2021
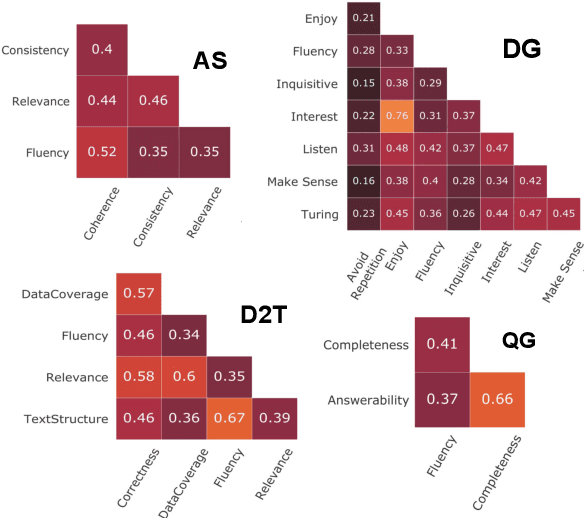
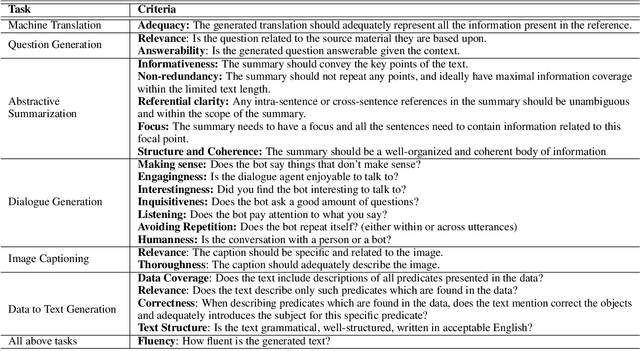
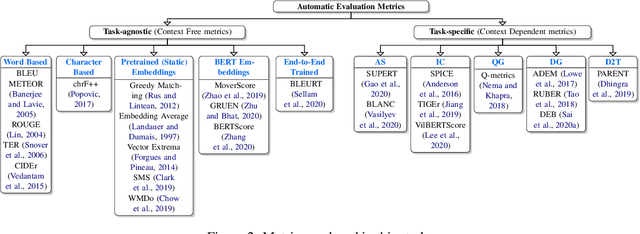
Natural Language Generation (NLG) evaluation is a multifaceted task requiring assessment of multiple desirable criteria, e.g., fluency, coherency, coverage, relevance, adequacy, overall quality, etc. Across existing datasets for 6 NLG tasks, we observe that the human evaluation scores on these multiple criteria are often not correlated. For example, there is a very low correlation between human scores on fluency and data coverage for the task of structured data to text generation. This suggests that the current recipe of proposing new automatic evaluation metrics for NLG by showing that they correlate well with scores assigned by humans for a single criteria (overall quality) alone is inadequate. Indeed, our extensive study involving 25 automatic evaluation metrics across 6 different tasks and 18 different evaluation criteria shows that there is no single metric which correlates well with human scores on all desirable criteria, for most NLG tasks. Given this situation, we propose CheckLists for better design and evaluation of automatic metrics. We design templates which target a specific criteria (e.g., coverage) and perturb the output such that the quality gets affected only along this specific criteria (e.g., the coverage drops). We show that existing evaluation metrics are not robust against even such simple perturbations and disagree with scores assigned by humans to the perturbed output. The proposed templates thus allow for a fine-grained assessment of automatic evaluation metrics exposing their limitations and will facilitate better design, analysis and evaluation of such metrics.