 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Mining Audio and Text Pairs from Public Data for Improving ASR Systems for Low-Resource Languages
Paper and Code
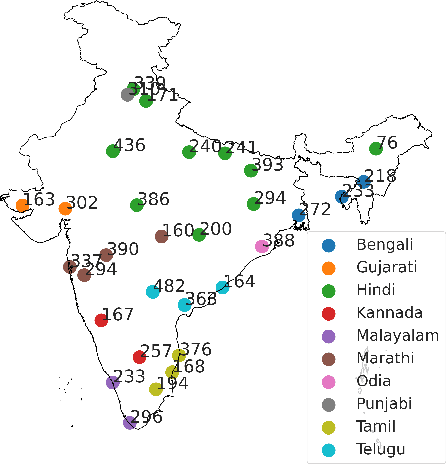
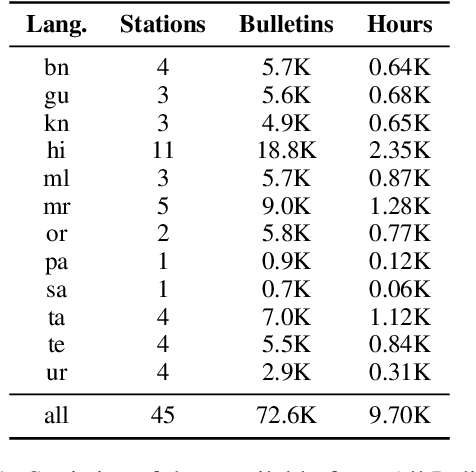

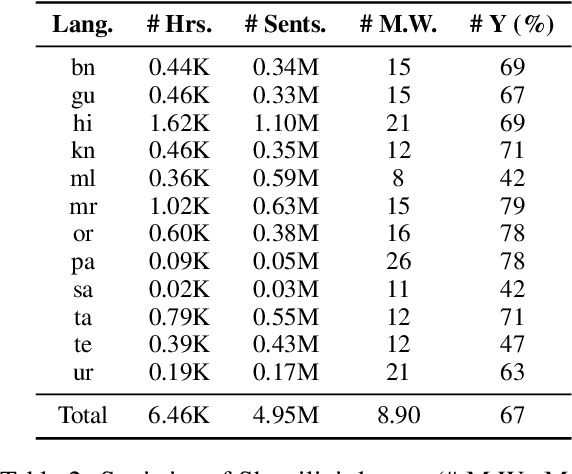
End-to-end (E2E) models have become the default choice for state-of-the-art speech recognition systems. Such models are trained on large amounts of labelled data, which are often not available for low-resource languages. Techniques such as self-supervised learning and transfer learning hold promise, but have not yet been effective in training accurate models. On the other hand, collecting labelled datasets on a diverse set of domains and speakers is very expensive. In this work, we demonstrate an inexpensive and effective alternative to these approaches by ``mining'' text and audio pairs for Indian languages from public sources, specifically from the public archives of All India Radio. As a key component, we adapt the Needleman-Wunsch algorithm to align sentences with corresponding audio segments given a long audio and a PDF of its transcript, while being robust to errors due to OCR, extraneous text, and non-transcribed speech. We thus create Shrutilipi, a dataset which contains over 6,400 hours of labelled audio across 12 Indian languages totalling to 4.95M sentences. On average, Shrutilipi results in a 2.3x increase over publicly available labelled data. We establish the quality of Shrutilipi with 21 human evaluators across the 12 languages. We also establish the diversity of Shrutilipi in terms of represented regions, speakers, and mentioned named entities. Significantly, we show that adding Shrutilipi to the training set of Wav2Vec models leads to an average decrease in WER of 5.8\% for 7 languages on the IndicSUPERB benchmark. For Hindi, which has the most benchmarks (7), the average WER falls from 18.8% to 13.5%. This improvement extends to efficient models: We show a 2.3% drop in WER for a Conformer model (10x smaller than Wav2Vec). Finally, we demonstrate the diversity of Shrutilipi by showing that the model trained with it is more robust to noisy input.