 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicSUPERB: A Speech Processing Universal Performance Benchmark for Indian languages
Paper and Code
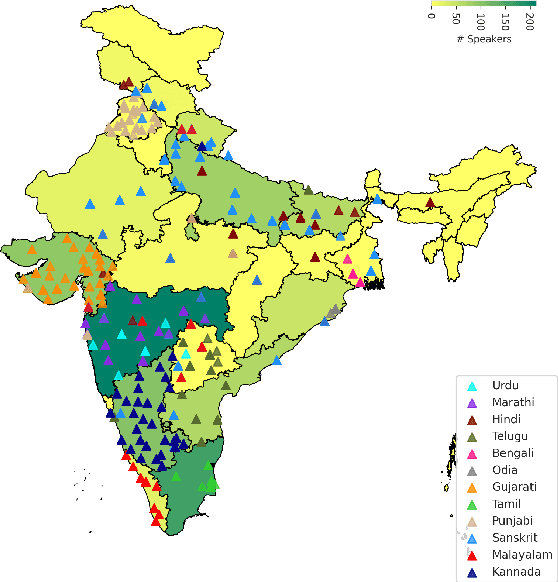
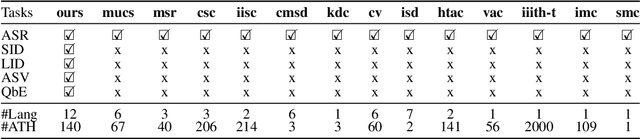

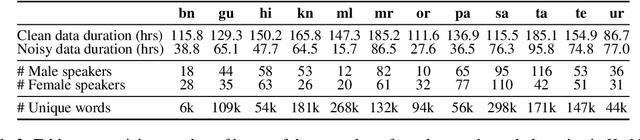
A cornerstone in AI research has been the creation and adoption of standardized training and test datasets to earmark the progress of state-of-the-art models. A particularly successful example is the GLUE dataset for training and evaluating Natural Language Understanding (NLU) models for English. The large body of research around self-supervised BERT-based language models revolved around performance improvements on NLU tasks in GLUE. To evaluate language models in other languages, several language-specific GLUE datasets were created. The area of speech language understanding (SLU) has followed a similar trajectory. The success of large self-supervised models such as wav2vec2 enable creation of speech models with relatively easy to access unlabelled data. These models can then be evaluated on SLU tasks, such as the SUPERB benchmark. In this work, we extend this to Indic languages by releasing the IndicSUPERB benchmark. Specifically, we make the following three contributions. (i) We collect Kathbath containing 1,684 hours of labelled speech data across 12 Indian languages from 1,218 contributors located in 203 districts in India. (ii) Using Kathbath, we create benchmarks across 6 speech tasks: Automatic Speech Recognition, Speaker Verification, Speaker Identification (mono/multi), Language Identification, Query By Example, and Keyword Spotting for 12 languages. (iii) On the released benchmarks, we train and evaluate different self-supervised models alongside a commonly used baseline FBANK. We show that language-specific fine-tuned models are more accurate than baseline on most of the tasks, including a large gap of 76\% for the Language Identification task. However, for speaker identification, self-supervised models trained on large datasets demonstrate an advantage. We hope IndicSUPERB contributes to the progress of developing speech language understanding models for Indian languages.