 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAHAJA: A Robust Multi-accent Benchmark for Evaluating Hindi ASR Systems
Paper and Code
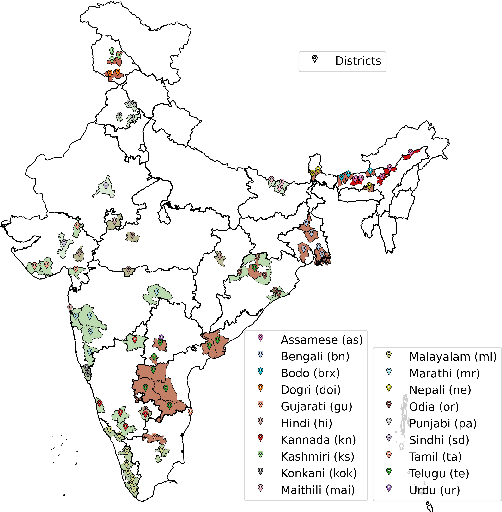

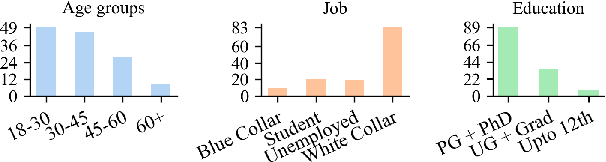

Hindi, one of the most spoken language of India, exhibits a diverse array of accents due to its usage among individuals from diverse linguistic origins. To enable a robust evaluation of Hindi ASR systems on multiple accents, we create a benchmark, LAHAJA, which contains read and extempore speech on a diverse set of topics and use cases, with a total of 12.5 hours of Hindi audio, sourced from 132 speakers spanning 83 districts of India. We evaluate existing open-source and commercial models on LAHAJA and find their performance to be poor. We then train models using different datasets and find that our model trained on multilingual data with good speaker diversity outperforms existing models by a significant margin. We also present a fine-grained analysis which shows that the performance declines for speakers from North-East and South India, especially with content heavy in named entities and specialized terminology.