 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State Of TTS: A Case Study with Human Fooling Rates
Aug 06, 2025


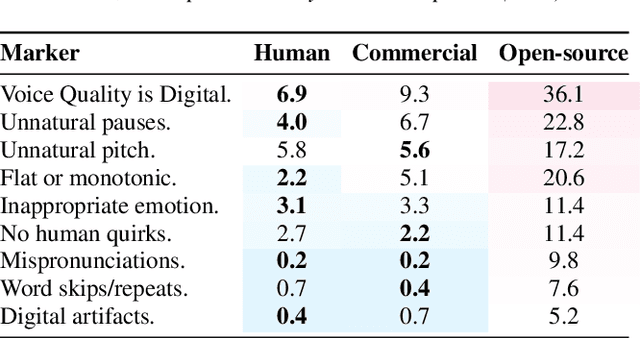
While subjective evaluations in recent years indicate rapid progress in TTS, can current TTS systems truly pass a human deception test in a Turing-like evaluation? We introduce Human Fooling Rate (HFR), a metric that directly measures how often machine-generated speech is mistaken for human. Our large-scale evaluation of open-source and commercial TTS models reveals critical insights: (i) CMOS-based claims of human parity often fail under deception testing, (ii) TTS progress should be benchmarked on datasets where human speech achieves high HFRs, as evaluating against monotonous or less expressive reference samples sets a low bar, (iii) Commercial models approach human deception in zero-shot settings, while open-source systems still struggle with natural conversational speech; (iv) Fine-tuning on high-quality data improves realism but does not fully bridge the gap. Our findings underscore the need for more realistic, human-centric evaluations alongside existing subjective tests.
Phir Hera Fairy: An English Fairytaler is a Strong Faker of Fluent Speech in Low-Resource Indian Languages
May 27, 2025What happens when an English Fairytaler is fine-tuned on Indian languages? We evaluate how the English F5-TTS model adapts to 11 Indian languages, measuring polyglot fluency, voice-cloning, style-cloning, and code-mixing. We compare: (i) training from scratch, (ii) fine-tuning English F5 on Indian data, and (iii) fine-tuning on both Indian and English data to prevent forgetting. Fine-tuning with only Indian data proves most effective and the resultant IN-F5 is a near-human polyglot; that enables speakers of one language (e.g., Odia) to fluently speak in another (e.g., Hindi). Our results show English pretraining aids low-resource TTS in reaching human parity. To aid progress in other low-resource languages, we study data-constrained setups and arrive at a compute optimal strategy. Finally, we show IN-F5 can synthesize unseen languages like Bhojpuri and Tulu using a human-in-the-loop approach for zero-resource TTS via synthetic data generation.
RASMALAI: Resources for Adaptive Speech Modeling in Indian Languages with Accents and Intonations
May 24, 2025We introduce RASMALAI, a large-scale speech dataset with rich text descriptions, designed to advance controllable and expressive text-to-speech (TTS) synthesis for 23 Indian languages and English. It comprises 13,000 hours of speech and 24 million text-description annotations with fine-grained attributes like speaker identity, accent, emotion, style, and background conditions. Using RASMALAI, we develop IndicParlerTTS, the first open-source, text-description-guided TTS for Indian languages. Systematic evaluation demonstrates its ability to generate high-quality speech for named speakers, reliably follow text descriptions and accurately synthesize specified attributes. Additionally, it effectively transfers expressive characteristics both within and across languages. IndicParlerTTS consistently achieves strong performance across these evaluations, setting a new standard for controllable multilingual expressive speech synthesis in Indian languages.
Rethinking MUSHRA: Addressing Modern Challenges in Text-to-Speech Evaluation
Nov 19, 2024Despite rapid advancements in TTS models, a consistent and robust human evaluation framework is still lacking. For example, MOS tests fail to differentiate between similar models, and CMOS's pairwise comparisons are time-intensive. The MUSHRA test is a promising alternative for evaluating multiple TTS systems simultaneously, but in this work we show that its reliance on matching human reference speech unduly penalises the scores of modern TTS systems that can exceed human speech quality. More specifically, we conduct a comprehensive assessment of the MUSHRA test, focusing on its sensitivity to factors such as rater variability, listener fatigue, and reference bias. Based on our extensive evaluation involving 471 human listeners across Hindi and Tamil we identify two primary shortcomings: (i) reference-matching bias, where raters are unduly influenced by the human reference, and (ii) judgement ambiguity, arising from a lack of clear fine-grained guidelines. To address these issues, we propose two refined variants of the MUSHRA test. The first variant enables fairer ratings for synthesized samples that surpass human reference quality. The second variant reduces ambiguity, as indicated by the relatively lower variance across raters. By combining these approaches, we achieve both more reliable and more fine-grained assessments. We also release MANGO, a massive dataset of 47,100 human ratings, the first-of-its-kind collection for Indian languages, aiding in analyzing human preferences and developing automatic metrics for evaluating TTS systems.
ELAICHI: Enhancing Low-resource TTS by Addressing Infrequent and Low-frequency Character Bigrams
Oct 23, 2024Recent advancements in Text-to-Speech (TTS) technology have led to natural-sounding speech for English, primarily due to the availability of large-scale, high-quality web data. However, many other languages lack access to such resources, relying instead on limited studio-quality data. This scarcity results in synthesized speech that often suffers from intelligibility issues, particularly with low-frequency character bigrams. In this paper, we propose three solutions to address this challenge. First, we leverage high-quality data from linguistically or geographically related languages to improve TTS for the target language. Second, we utilize low-quality Automatic Speech Recognition (ASR) data recorded in non-studio environments, which is refined using denoising and speech enhancement models. Third, we apply knowledge distillation from large-scale models using synthetic data to generate more robust outputs. Our experiments with Hindi demonstrate significant reductions in intelligibility issues, as validated by human evaluators. We propose this methodology as a viable alternative for languages with limited access to high-quality data, enabling them to collectively benefit from shared resources.
IndicVoices-R: Unlocking a Massive Multilingual Multi-speaker Speech Corpus for Scaling Indian TTS
Sep 09, 2024



Recent advancements in text-to-speech (TTS) synthesis show that large-scale models trained with extensive web data produce highly natural-sounding output. However, such data is scarce for Indian languages due to the lack of high-quality, manually subtitled data on platforms like LibriVox or YouTube. To address this gap, we enhance existing large-scale ASR datasets containing natural conversations collected in low-quality environments to generate high-quality TTS training data. Our pipeline leverages the cross-lingual generalization of denoising and speech enhancement models trained on English and applied to Indian languages. This results in IndicVoices-R (IV-R), the largest multilingual Indian TTS dataset derived from an ASR dataset, with 1,704 hours of high-quality speech from 10,496 speakers across 22 Indian languages. IV-R matches the quality of gold-standard TTS datasets like LJSpeech, LibriTTS, and IndicTTS. We also introduce the IV-R Benchmark, the first to assess zero-shot, few-shot, and many-shot speaker generalization capabilities of TTS models on Indian voices, ensuring diversity in age, gender, and style. We demonstrate that fine-tuning an English pre-trained model on a combined dataset of high-quality IndicTTS and our IV-R dataset results in better zero-shot speaker generalization compared to fine-tuning on the IndicTTS dataset alone. Further, our evaluation reveals limited zero-shot generalization for Indian voices in TTS models trained on prior datasets, which we improve by fine-tuning the model on our data containing diverse set of speakers across language families. We open-source all data and code, releasing the first TTS model for all 22 official Indian languages.
Rasa: Building Expressive Speech Synthesis Systems for Indian Languages in Low-resource Settings
Jul 19, 2024



We release Rasa, the first multilingual expressive TTS dataset for any Indian language, which contains 10 hours of neutral speech and 1-3 hours of expressive speech for each of the 6 Ekman emotions covering 3 languages: Assamese, Bengali, & Tamil. Our ablation studies reveal that just 1 hour of neutral and 30 minutes of expressive data can yield a Fair system as indicated by MUSHRA scores. Increasing neutral data to 10 hours, with minimal expressive data, significantly enhances expressiveness. This offers a practical recipe for resource-constrained languages, prioritizing easily obtainable neutral data alongside smaller amounts of expressive data. We show the importance of syllabically balanced data and pooling emotions to enhance expressiveness. We also highlight challenges in generating specific emotions, e.g., fear and surprise.
Enhancing Out-of-Vocabulary Performance of Indian TTS Systems for Practical Applications through Low-Effort Data Strategies
Jul 18, 2024



Publicly available TTS datasets for low-resource languages like Hindi and Tamil typically contain 10-20 hours of data, leading to poor vocabulary coverage. This limitation becomes evident in downstream applications where domain-specific vocabulary coupled with frequent code-mixing with English, results in many OOV words. To highlight this problem, we create a benchmark containing OOV words from several real-world applications. Indeed, state-of-the-art Hindi and Tamil TTS systems perform poorly on this OOV benchmark, as indicated by intelligibility tests. To improve the model's OOV performance, we propose a low-effort and economically viable strategy to obtain more training data. Specifically, we propose using volunteers as opposed to high quality voice artists to record words containing character bigrams unseen in the training data. We show that using such inexpensive data, the model's performance improves on OOV words, while not affecting voice quality and in-domain performance.