 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State Of TTS: A Case Study with Human Fooling Rates
Aug 06, 2025


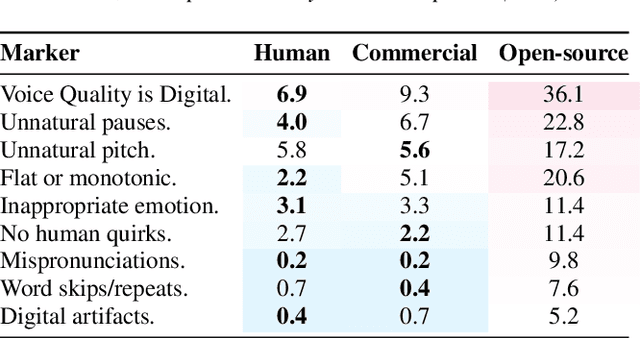
While subjective evaluations in recent years indicate rapid progress in TTS, can current TTS systems truly pass a human deception test in a Turing-like evaluation? We introduce Human Fooling Rate (HFR), a metric that directly measures how often machine-generated speech is mistaken for human. Our large-scale evaluation of open-source and commercial TTS models reveals critical insights: (i) CMOS-based claims of human parity often fail under deception testing, (ii) TTS progress should be benchmarked on datasets where human speech achieves high HFRs, as evaluating against monotonous or less expressive reference samples sets a low bar, (iii) Commercial models approach human deception in zero-shot settings, while open-source systems still struggle with natural conversational speech; (iv) Fine-tuning on high-quality data improves realism but does not fully bridge the gap. Our findings underscore the need for more realistic, human-centric evaluations alongside existing subjective tests.
Rethinking MUSHRA: Addressing Modern Challenges in Text-to-Speech Evaluation
Nov 19, 2024Despite rapid advancements in TTS models, a consistent and robust human evaluation framework is still lacking. For example, MOS tests fail to differentiate between similar models, and CMOS's pairwise comparisons are time-intensive. The MUSHRA test is a promising alternative for evaluating multiple TTS systems simultaneously, but in this work we show that its reliance on matching human reference speech unduly penalises the scores of modern TTS systems that can exceed human speech quality. More specifically, we conduct a comprehensive assessment of the MUSHRA test, focusing on its sensitivity to factors such as rater variability, listener fatigue, and reference bias. Based on our extensive evaluation involving 471 human listeners across Hindi and Tamil we identify two primary shortcomings: (i) reference-matching bias, where raters are unduly influenced by the human reference, and (ii) judgement ambiguity, arising from a lack of clear fine-grained guidelines. To address these issues, we propose two refined variants of the MUSHRA test. The first variant enables fairer ratings for synthesized samples that surpass human reference quality. The second variant reduces ambiguity, as indicated by the relatively lower variance across raters. By combining these approaches, we achieve both more reliable and more fine-grained assessments. We also release MANGO, a massive dataset of 47,100 human ratings, the first-of-its-kind collection for Indian languages, aiding in analyzing human preferences and developing automatic metrics for evaluating TTS systems.
Are Natural Language Inference Models IMPPRESsive? Learning IMPlicature and PRESupposition
Apr 07, 2020

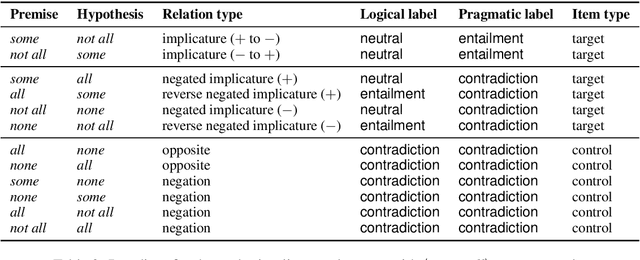

Natural language inference (NLI) is an increasingly important task for natural language understanding, which requires one to infer whether one sentence entails another. However, the ability of NLI models to make pragmatic inferences remains understudied. We create an IMPlicature and PRESupposition diagnostic dataset (IMPPRES), consisting of 32K semi-automatically generated sentence pairs illustrating well-studied pragmatic inference types. We use IMPPRES to evaluate whether BERT, BOW, and InferSent NLI models trained on MultiNLI (Williams et al., 2018) learn to make pragmatic inferences. Although MultiNLI contains vanishingly few pairs illustrating these inference types, we find that BERT learns to draw pragmatic inferences: it reliably treats implicatures triggered by "some" as entailments. For some presupposition triggers like "only", BERT reliably recognizes the presupposition as an entailment, even when the trigger is embedded under an entailment canceling operator like negation. BOW and InferSent show weaker evidence of pragmatic reasoning. We conclude that NLI training encourages models to learn some, but not all, pragmatic inferences.
Supervised Multimodal Bitransformers for Classifying Images and Text
Sep 06, 2019



Self-supervised bidirectional transformer models such as BERT have led to dramatic improvements in a wide variety of textual classification tasks. The modern digital world is increasingly multimodal, however, and textual information is often accompanied by other modalities such as images. We introduce a supervised multimodal bitransformer model that fuses information from text and image encoders, and obtain state-of-the-art performance on various multimodal classification benchmark tasks, outperforming strong baselines, including on hard test sets specifically designed to measure multimodal performance.
Needles in Haystacks: On Classifying Tiny Objects in Large Images
Aug 16, 2019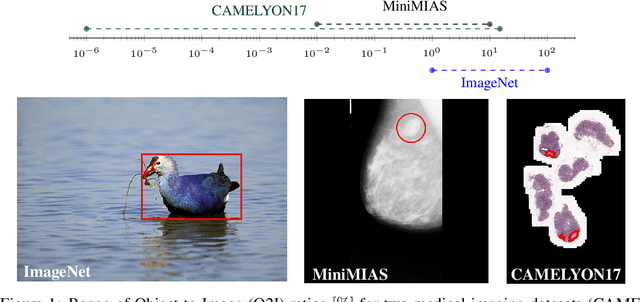
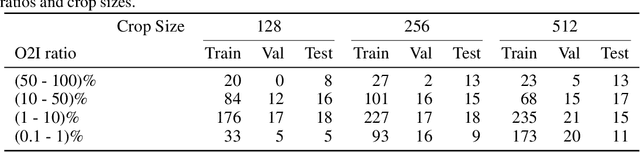
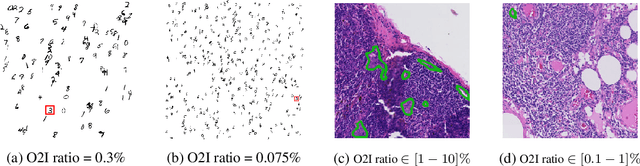
In some computer vision domains, such as medical or hyperspectral imaging, we care about the classification of tiny objects in large images. However, most Convolutional Neural Networks (CNNs) for image classification were developed and analyzed using biased datasets that contain large objects, most often, in central image positions. To assess whether classical CNN architectures work well for tiny object classification we build a comprehensive testbed containing two datasets: one derived from MNIST digits and other from histopathology images. This testbed allows us to perform controlled experiments to stress-test CNN architectures using a broad spectrum of signal-to-noise ratios. Our observations suggest that: (1) There exists a limit to signal-to-noise below which CNNs fail to generalize and that this limit is affected by dataset size - more data leading to better performances; however, the amount of training data required for the model to generalize scales rapidly with the inverse of the object-to-image ratio (2) in general, higher capacity models exhibit better generalization; (3) when knowing the approximate object sizes, adapting receptive field is beneficial; and (4) for very small signal-to-noise ratio the choice of global pooling operation affects optimization, whereas for relatively large signal-to-noise values, all tested global pooling operations exhibit similar performance.
Drive2Vec: Multiscale State-Space Embedding of Vehicular Sensor Data
Jun 12, 2018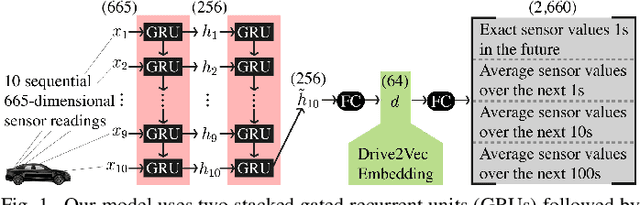
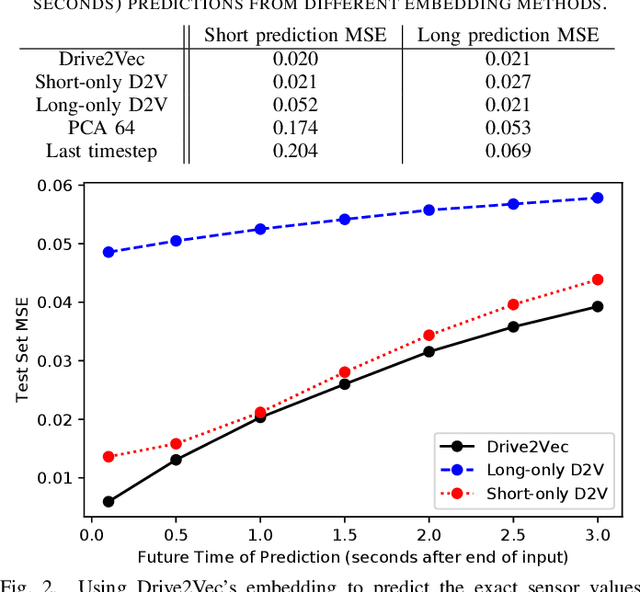
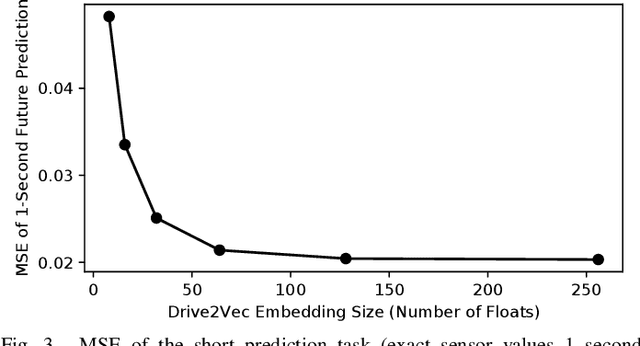

With automobiles becoming increasingly reliant on sensors to perform various driving tasks, it is important to encode the relevant CAN bus sensor data in a way that captures the general state of the vehicle in a compact form. In this paper, we develop a deep learning-based method, called Drive2Vec, for embedding such sensor data in a low-dimensional yet actionable form. Our method is based on stacked gated recurrent units (GRUs). It accepts a short interval of automobile sensor data as input and computes a low-dimensional representation of that data, which can then be used to accurately solve a range of tasks. With this representation, we (1) predict the exact values of the sensors in the short term (up to three seconds in the future), (2) forecast the long-term average values of these same sensors, (3) infer additional contextual information that is not encoded in the data, including the identity of the driver behind the wheel, and (4) build a knowledge base that can be used to auto-label data and identify risky states. We evaluate our approach on a dataset collected by Audi, which equipped a fleet of test vehicles with data loggers to store all sensor readings on 2,098 hours of driving on real roads. We show in several experiments that our method outperforms other baselines by up to 90%, and we further demonstrate how these embeddings of sensor data can be used to solve a variety of real-world automotive applications.
ShortFuse: Biomedical Time Series Representations in the Presence of Structured Information
May 16, 2017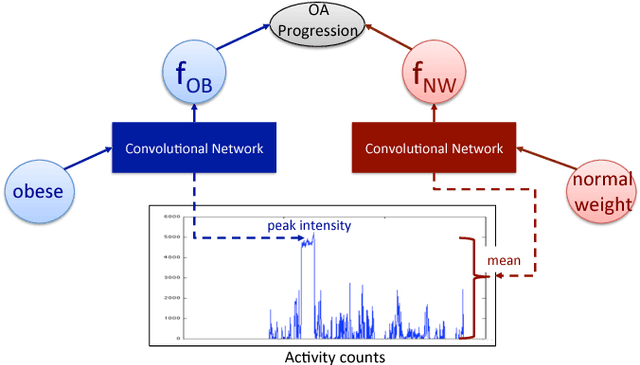
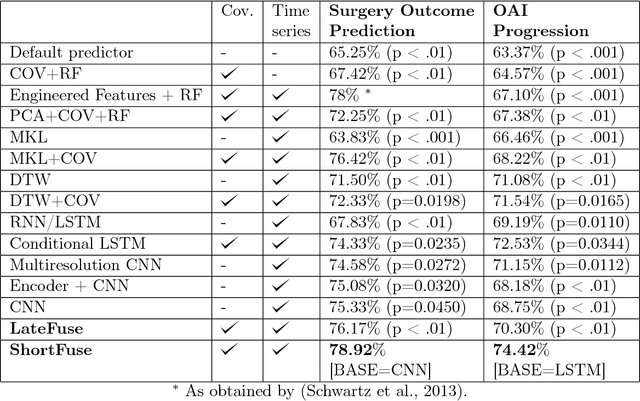
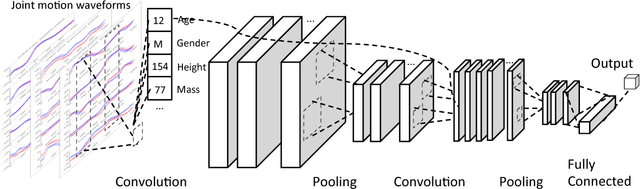
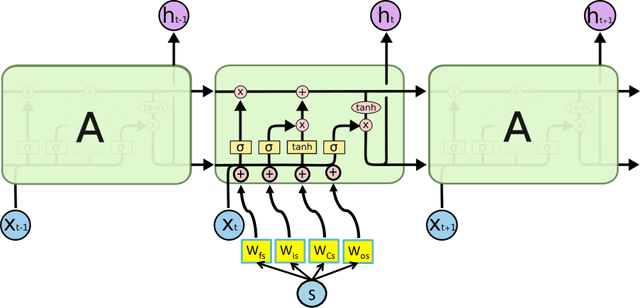
In healthcare applications, temporal variables that encode movement, health status and longitudinal patient evolution are often accompanied by rich structured information such as demographics, diagnostics and medical exam data. However, current methods do not jointly optimize over structured covariates and time series in the feature extraction process. We present ShortFuse, a method that boosts the accuracy of deep learning models for time series by explicitly modeling temporal interactions and dependencies with structured covariates. ShortFuse introduces hybrid convolutional and LSTM cells that incorporate the covariates via weights that are shared across the temporal domain. ShortFuse outperforms competing models by 3% on two biomedical applications, forecasting osteoarthritis-related cartilage degeneration and predicting surgical outcomes for cerebral palsy patients, matching or exceeding the accuracy of models that use features engineered by domain experts.