 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation
Mar 20, 2025Recent advances in text-to-image diffusion models have been driven by the increasing availability of paired 2D data. However, the development of 3D diffusion models has been hindered by the scarcity of high-quality 3D data, resulting in less competitive performance compared to their 2D counterparts. To address this challenge, we propose repurposing pre-trained 2D diffusion models for 3D object generation. We introduce Gaussian Atlas, a novel representation that utilizes dense 2D grids, enabling the fine-tuning of 2D diffusion models to generate 3D Gaussians. Our approach demonstrates successful transfer learning from a pre-trained 2D diffusion model to a 2D manifold flattened from 3D structures. To support model training, we compile GaussianVerse, a large-scale dataset comprising 205K high-quality 3D Gaussian fittings of various 3D objects. Our experimental results show that text-to-image diffusion models can be effectively adapted for 3D content generation, bridging the gap between 2D and 3D modeling.
OccFusion: Rendering Occluded Humans with Generative Diffusion Priors
Jun 29, 2024Most existing human rendering methods require every part of the human to be fully visible throughout the input video. However, this assumption does not hold in real-life settings where obstructions are common, resulting in only partial visibility of the human. Considering this, we present OccFusion, an approach that utilizes efficient 3D Gaussian splatting supervised by pretrained 2D diffusion models for efficient and high-fidelity human rendering. We propose a pipeline consisting of three stages. In the Initialization stage, complete human masks are generated from partial visibility masks. In the Optimization stage, 3D human Gaussians are optimized with additional supervision by Score-Distillation Sampling (SDS) to create a complete geometry of the human. Finally, in the Refinement stage, in-context inpainting is designed to further improve rendering quality on the less observed human body parts. We evaluate OccFusion on ZJU-MoCap and challenging OcMotion sequences and find that it achieves state-of-the-art performance in the rendering of occluded humans.
Wild2Avatar: Rendering Humans Behind Occlusions
Dec 31, 2023Rendering the visual appearance of moving humans from occluded monocular videos is a challenging task. Most existing research renders 3D humans under ideal conditions, requiring a clear and unobstructed scene. Those methods cannot be used to render humans in real-world scenes where obstacles may block the camera's view and lead to partial occlusions. In this work, we present Wild2Avatar, a neural rendering approach catered for occluded in-the-wild monocular videos. We propose occlusion-aware scene parameterization for decoupling the scene into three parts - occlusion, human, and background. Additionally, extensive objective functions are designed to help enforce the decoupling of the human from both the occlusion and the background and to ensure the completeness of the human model. We verify the effectiveness of our approach with experiments on in-the-wild videos.
Diffusion Inertial Poser: Human Motion Reconstruction from Arbitrary Sparse IMU Configurations
Aug 31, 2023



Motion capture from a limited number of inertial measurement units (IMUs) has important applications in health, human performance, and virtual reality. Real-world limitations and application-specific goals dictate different IMU configurations (i.e., number of IMUs and chosen attachment body segments), trading off accuracy and practicality. Although recent works were successful in accurately reconstructing whole-body motion from six IMUs, these systems only work with a specific IMU configuration. Here we propose a single diffusion generative model, Diffusion Inertial Poser (DiffIP), which reconstructs human motion in real-time from arbitrary IMU configurations. We show that DiffIP has the benefit of flexibility with respect to the IMU configuration while being as accurate as the state-of-the-art for the commonly used six IMU configuration. Our system enables selecting an optimal configuration for different applications without retraining the model. For example, when only four IMUs are available, DiffIP found that the configuration that minimizes errors in joint kinematics instruments the thighs and forearms. However, global translation reconstruction is better when instrumenting the feet instead of the thighs. Although our approach is agnostic to the underlying model, we built DiffIP based on physiologically realistic musculoskeletal models to enable use in biomedical research and health applications.
Medical device surveillance with electronic health records
Apr 03, 2019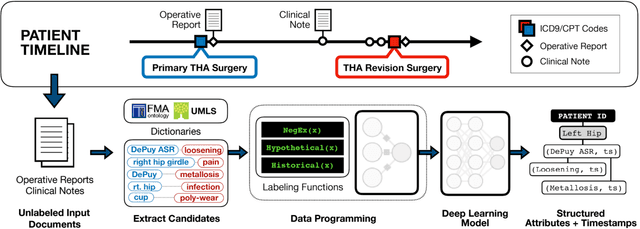
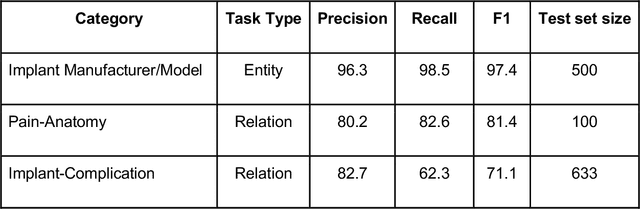

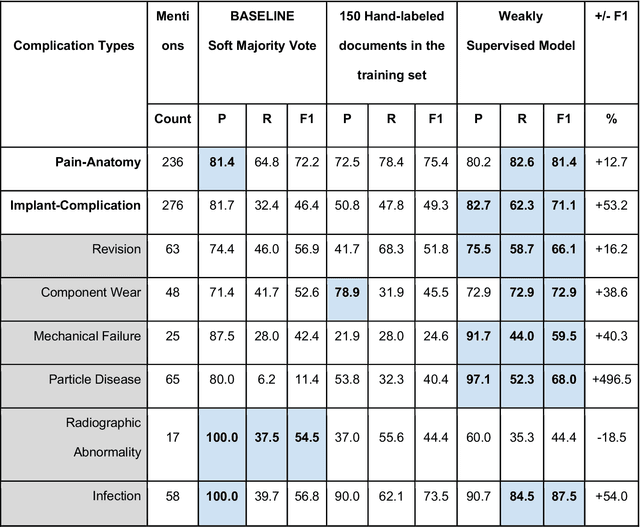
Post-market medical device surveillance is a challenge facing manufacturers, regulatory agencies, and health care providers. Electronic health records are valuable sources of real world evidence to assess device safety and track device-related patient outcomes over time. However, distilling this evidence remains challenging, as information is fractured across clinical notes and structured records. Modern machine learning methods for machine reading promise to unlock increasingly complex information from text, but face barriers due to their reliance on large and expensive hand-labeled training sets. To address these challenges, we developed and validated state-of-the-art deep learning methods that identify patient outcomes from clinical notes without requiring hand-labeled training data. Using hip replacements as a test case, our methods accurately extracted implant details and reports of complications and pain from electronic health records with up to 96.3% precision, 98.5% recall, and 97.4% F1, improved classification performance by 12.7- 53.0% over rule-based methods, and detected over 6 times as many complication events compared to using structured data alone. Using these events to assess complication-free survivorship of different implant systems, we found significant variation between implants, including for risk of revision surgery, which could not be detected using coded data alone. Patients with revision surgeries had more hip pain mentions in the post-hip replacement, pre-revision period compared to patients with no evidence of revision surgery (mean hip pain mentions 4.97 vs. 3.23; t = 5.14; p < 0.001). Some implant models were associated with higher or lower rates of hip pain mentions. Our methods complement existing surveillance mechanisms by requiring orders of magnitude less hand-labeled training data, offering a scalable solution for national medical device surveillance.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
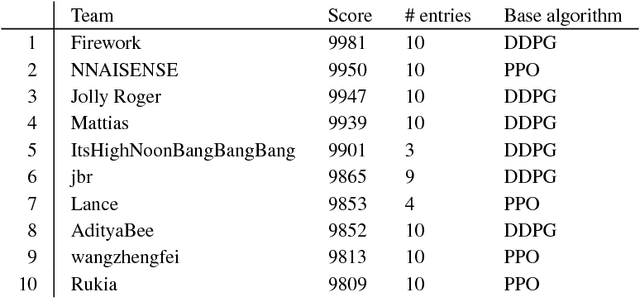

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments
Apr 02, 2018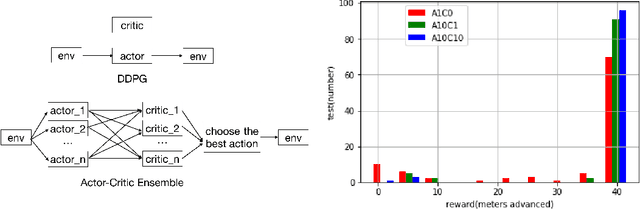

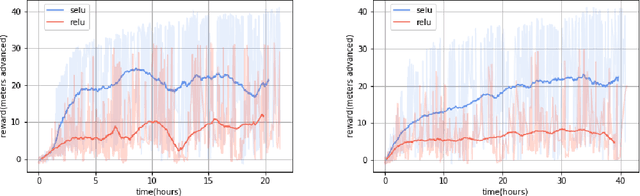
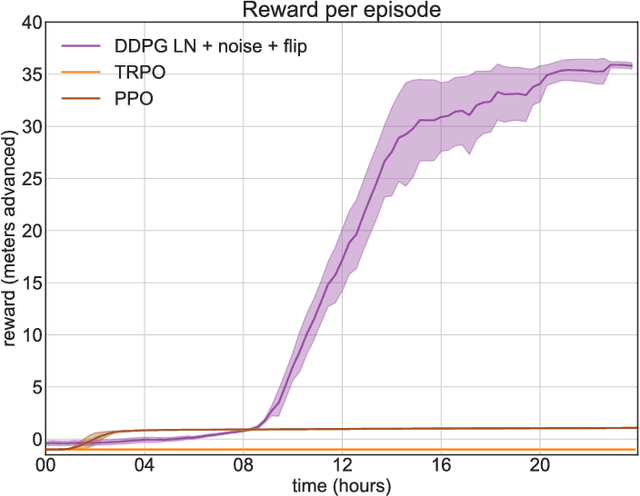
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.
ShortFuse: Biomedical Time Series Representations in the Presence of Structured Information
May 16, 2017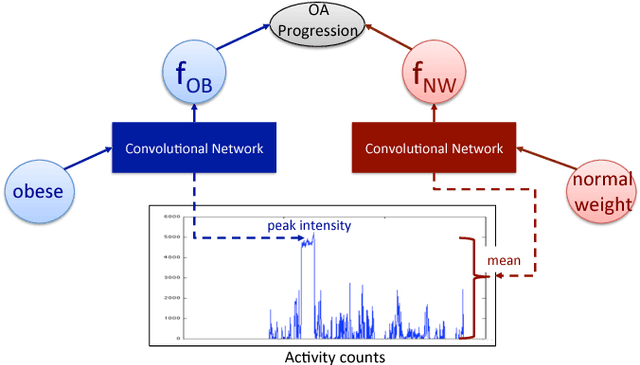
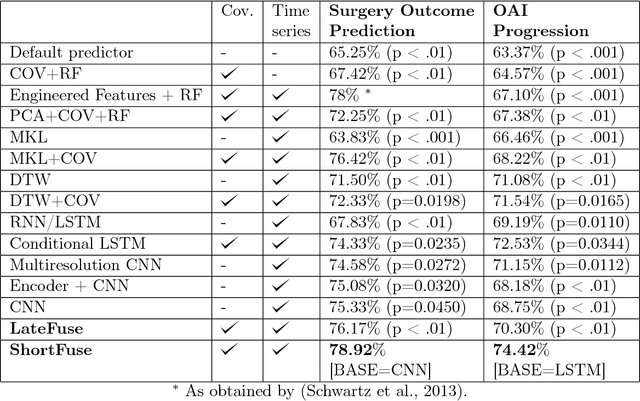
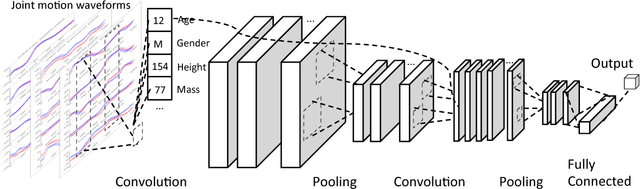
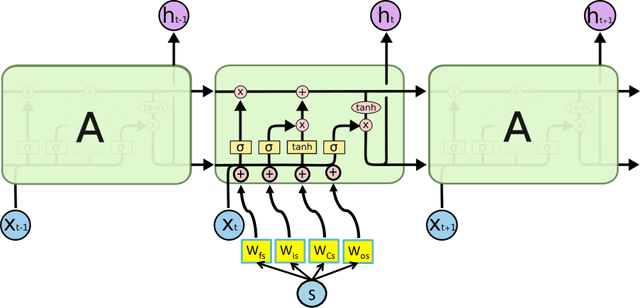
In healthcare applications, temporal variables that encode movement, health status and longitudinal patient evolution are often accompanied by rich structured information such as demographics, diagnostics and medical exam data. However, current methods do not jointly optimize over structured covariates and time series in the feature extraction process. We present ShortFuse, a method that boosts the accuracy of deep learning models for time series by explicitly modeling temporal interactions and dependencies with structured covariates. ShortFuse introduces hybrid convolutional and LSTM cells that incorporate the covariates via weights that are shared across the temporal domain. ShortFuse outperforms competing models by 3% on two biomedical applications, forecasting osteoarthritis-related cartilage degeneration and predicting surgical outcomes for cerebral palsy patients, matching or exceeding the accuracy of models that use features engineered by domain experts.