 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Multi-sensor Conditioning for Street-view Novel-view Synthesis
Jun 01, 2026Modern vehicle platforms are equipped with a rich sensor suite, including LiDAR, calibrated multi-camera rigs, and accurate ego-motion, that in principle offers strong signal for re-rendering a driving scene from novel viewpoints. A growing line of recent work leverages video diffusion models for this task, using their generative priors to synthesize plausible novel views from sparse vehicle observations. In practice, however, existing methods exploit only a fragment of this signal, and their quality tends to degrade as the target trajectory departs from the recorded driving path. We argue that this is fundamentally a multi-sensor fusion problem: sparse LiDAR reprojections supply accurate but incomplete metric geometry, surround-view reference imagery supplies dense appearance but no metric depth, and camera poses tie the two together across views. We introduce StreetNVS, a video diffusion framework that jointly conditions on all three signals through a Reference-Enhanced Camera Attention module based on a relative ray-level positional encoding. We develop a two-stage curriculum training strategy that gradually exposes the model to increasingly sparse LiDAR. On the Waymo Open Dataset, StreetNVS substantially outperforms state-of-the-art baselines under sparse LiDAR conditioning, matches methods that rely on 10-100 times denser point clouds. We further show capabilities of synthesizing coherent videos along extreme out-of-trajectory paths such as elevation, lane-shift, pullback, and rotation. Our website: https://streetnvs.github.io
OccFusion: Rendering Occluded Humans with Generative Diffusion Priors
Jun 29, 2024



Most existing human rendering methods require every part of the human to be fully visible throughout the input video. However, this assumption does not hold in real-life settings where obstructions are common, resulting in only partial visibility of the human. Considering this, we present OccFusion, an approach that utilizes efficient 3D Gaussian splatting supervised by pretrained 2D diffusion models for efficient and high-fidelity human rendering. We propose a pipeline consisting of three stages. In the Initialization stage, complete human masks are generated from partial visibility masks. In the Optimization stage, 3D human Gaussians are optimized with additional supervision by Score-Distillation Sampling (SDS) to create a complete geometry of the human. Finally, in the Refinement stage, in-context inpainting is designed to further improve rendering quality on the less observed human body parts. We evaluate OccFusion on ZJU-MoCap and challenging OcMotion sequences and find that it achieves state-of-the-art performance in the rendering of occluded humans.
Wild2Avatar: Rendering Humans Behind Occlusions
Dec 31, 2023Rendering the visual appearance of moving humans from occluded monocular videos is a challenging task. Most existing research renders 3D humans under ideal conditions, requiring a clear and unobstructed scene. Those methods cannot be used to render humans in real-world scenes where obstacles may block the camera's view and lead to partial occlusions. In this work, we present Wild2Avatar, a neural rendering approach catered for occluded in-the-wild monocular videos. We propose occlusion-aware scene parameterization for decoupling the scene into three parts - occlusion, human, and background. Additionally, extensive objective functions are designed to help enforce the decoupling of the human from both the occlusion and the background and to ensure the completeness of the human model. We verify the effectiveness of our approach with experiments on in-the-wild videos.
Rendering Humans from Object-Occluded Monocular Videos
Aug 08, 2023


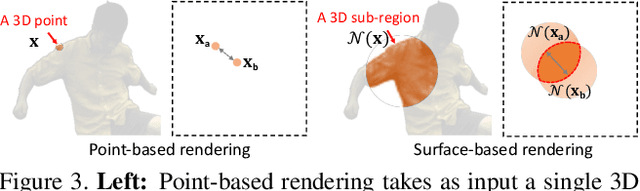
3D understanding and rendering of moving humans from monocular videos is a challenging task. Despite recent progress, the task remains difficult in real-world scenarios, where obstacles may block the camera view and cause partial occlusions in the captured videos. Existing methods cannot handle such defects due to two reasons. First, the standard rendering strategy relies on point-point mapping, which could lead to dramatic disparities between the visible and occluded areas of the body. Second, the naive direct regression approach does not consider any feasibility criteria (ie, prior information) for rendering under occlusions. To tackle the above drawbacks, we present OccNeRF, a neural rendering method that achieves better rendering of humans in severely occluded scenes. As direct solutions to the two drawbacks, we propose surface-based rendering by integrating geometry and visibility priors. We validate our method on both simulated and real-world occlusions and demonstrate our method's superiority.