 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendering Humans from Object-Occluded Monocular Videos
Paper and Code
Aug 08, 2023


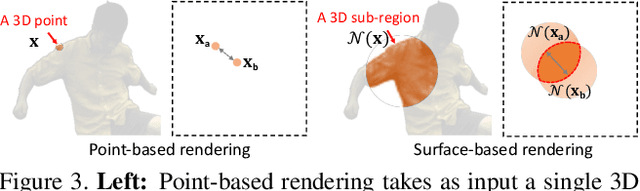
3D understanding and rendering of moving humans from monocular videos is a challenging task. Despite recent progress, the task remains difficult in real-world scenarios, where obstacles may block the camera view and cause partial occlusions in the captured videos. Existing methods cannot handle such defects due to two reasons. First, the standard rendering strategy relies on point-point mapping, which could lead to dramatic disparities between the visible and occluded areas of the body. Second, the naive direct regression approach does not consider any feasibility criteria (ie, prior information) for rendering under occlusions. To tackle the above drawbacks, we present OccNeRF, a neural rendering method that achieves better rendering of humans in severely occluded scenes. As direct solutions to the two drawbacks, we propose surface-based rendering by integrating geometry and visibility priors. We validate our method on both simulated and real-world occlusions and demonstrate our method's superiority.