 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
A Multi-Center Study on the Adaptability of a Shared Foundation Model for Electronic Health Records
Nov 20, 2023Foundation models hold promise for transforming AI in healthcare by providing modular components that are easily adaptable to downstream healthcare tasks, making AI development more scalable and cost-effective. Structured EHR foundation models, trained on coded medical records from millions of patients, demonstrated benefits including increased performance with fewer training labels, and improved robustness to distribution shifts. However, questions remain on the feasibility of sharing these models across different hospitals and their performance for local task adaptation. This multi-center study examined the adaptability of a recently released structured EHR foundation model ($FM_{SM}$), trained on longitudinal medical record data from 2.57M Stanford Medicine patients. Experiments were conducted using EHR data at The Hospital for Sick Children and MIMIC-IV. We assessed both adaptability via continued pretraining on local data, and task adaptability compared to baselines of training models from scratch at each site, including a local foundation model. We evaluated the performance of these models on 8 clinical prediction tasks. In both datasets, adapting the off-the-shelf $FM_{SM}$ matched the performance of GBM models locally trained on all data while providing a 13% improvement in settings with few task-specific training labels. With continued pretraining on local data, label efficiency substantially improved, such that $FM_{SM}$ required fewer than 1% of training examples to match the fully trained GBM's performance. Continued pretraining was also 60 to 90% more sample-efficient than training local foundation models from scratch. Our findings show that adapting shared EHR foundation models across hospitals provides improved prediction performance at less cost, underscoring the utility of base foundation models as modular components to streamline the development of healthcare AI.
EHRSHOT: An EHR Benchmark for Few-Shot Evaluation of Foundation Models
Jul 05, 2023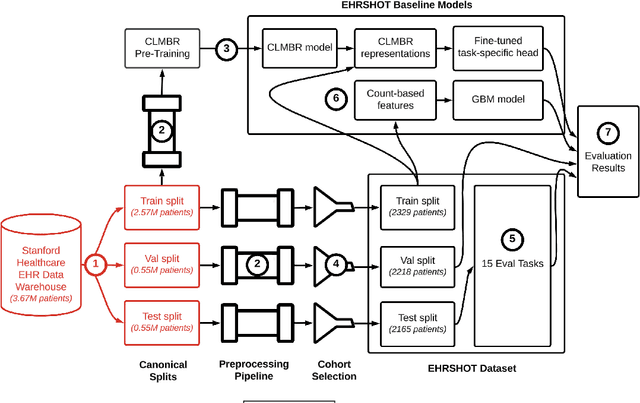
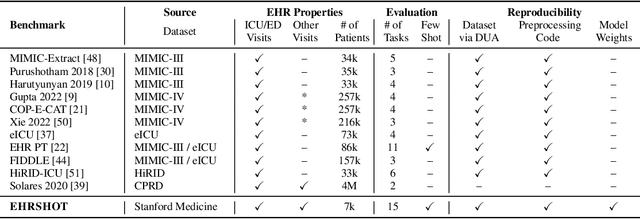

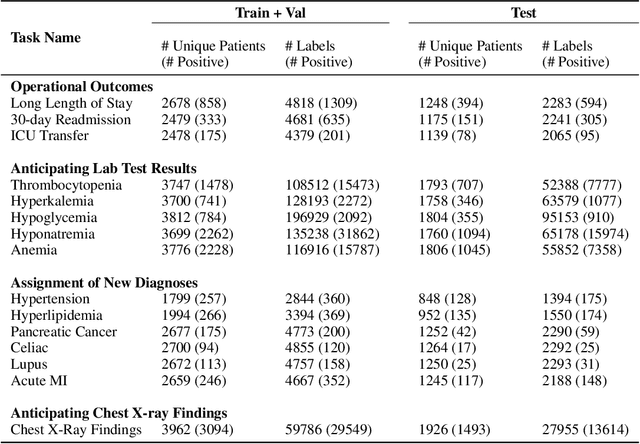
While the general machine learning (ML) community has benefited from public datasets, tasks, and models, the progress of ML in healthcare has been hampered by a lack of such shared assets. The success of foundation models creates new challenges for healthcare ML by requiring access to shared pretrained models to validate performance benefits. We help address these challenges through three contributions. First, we publish a new dataset, EHRSHOT, containing de-identified structured data from the electronic health records (EHRs) of 6,712 patients from Stanford Medicine. Unlike MIMIC-III/IV and other popular EHR datasets, EHRSHOT is longitudinal and not restricted to ICU/ED patients. Second, we publish the weights of a 141M parameter clinical foundation model pretrained on the structured EHR data of 2.57M patients. We are one of the first to fully release such a model for coded EHR data; in contrast, most prior models released for clinical data (e.g. GatorTron, ClinicalBERT) only work with unstructured text and cannot process the rich, structured data within an EHR. We provide an end-to-end pipeline for the community to validate and build upon its performance. Third, we define 15 few-shot clinical prediction tasks, enabling evaluation of foundation models on benefits such as sample efficiency and task adaption. The code to reproduce our results, as well as the model and dataset (via a research data use agreement), are available at our Github repo here: https://github.com/som-shahlab/ehrshot-benchmark
The Shaky Foundations of Clinical Foundation Models: A Survey of Large Language Models and Foundation Models for EMRs
Mar 24, 2023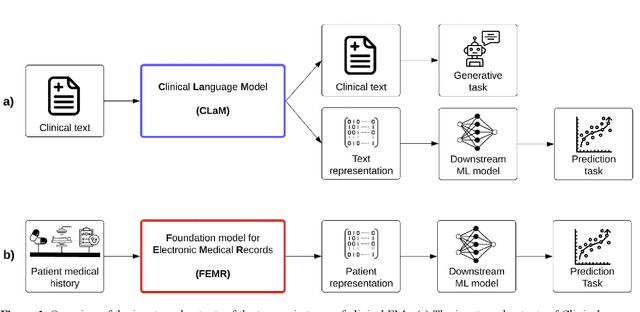
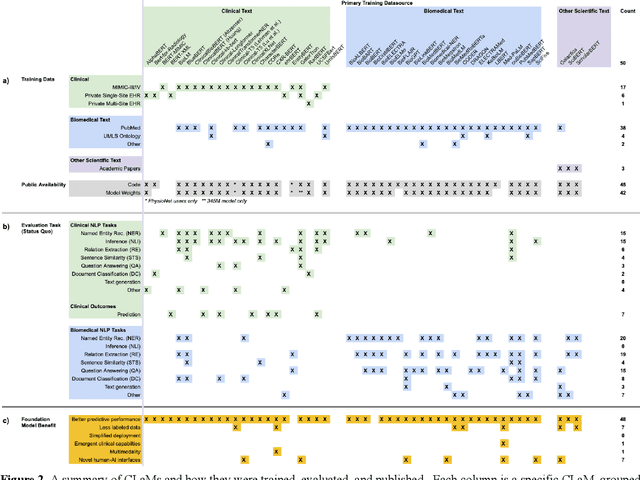
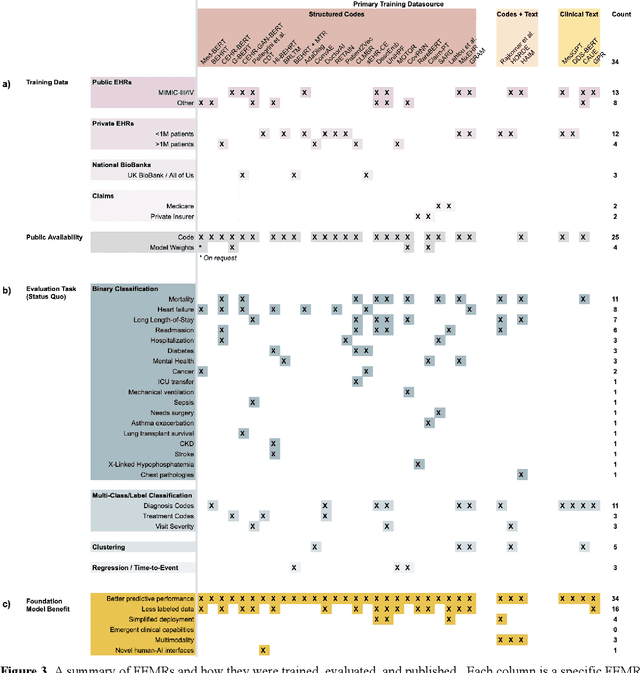

The successes of foundation models such as ChatGPT and AlphaFold have spurred significant interest in building similar models for electronic medical records (EMRs) to improve patient care and hospital operations. However, recent hype has obscured critical gaps in our understanding of these models' capabilities. We review over 80 foundation models trained on non-imaging EMR data (i.e. clinical text and/or structured data) and create a taxonomy delineating their architectures, training data, and potential use cases. We find that most models are trained on small, narrowly-scoped clinical datasets (e.g. MIMIC-III) or broad, public biomedical corpora (e.g. PubMed) and are evaluated on tasks that do not provide meaningful insights on their usefulness to health systems. In light of these findings, we propose an improved evaluation framework for measuring the benefits of clinical foundation models that is more closely grounded to metrics that matter in healthcare.
Self-Supervised Time-to-Event Modeling with Structured Medical Records
Jan 09, 2023



Time-to-event models (also known as survival models) are used in medicine and other fields for estimating the probability distribution of the time until a particular event occurs. While providing many advantages over traditional classification models, such as naturally handling censoring, time-to-event models require more parameters and are challenging to learn in settings with limited labeled training data. High censoring rates, common in events with long time horizons, further limit available training data and exacerbate the risk of overfitting. Existing methods, such as proportional hazard or accelerated failure time-based approaches, employ distributional assumptions to reduce parameter size, but they are vulnerable to model misspecification. In this work, we address these challenges with MOTOR, a self-supervised model that leverages temporal structure found in large-scale collections of timestamped, but largely unlabeled events, typical of electronic health record data. MOTOR defines a time-to-event pretraining task that naturally captures the probability distribution of event times, making it well-suited to applications in medicine. After pretraining on 8,192 tasks auto-generated from 2.7M patients (2.4B clinical events), we evaluate the performance of our pretrained model after fine-tuning to unseen time-to-event tasks. MOTOR-derived models improve upon current state-of-the-art C statistic performance by 6.6% and decrease training time (in wall time) by up to 8.2 times. We further improve sample efficiency, with adapted models matching current state-of-the-art performance using 95% less training data.
Multi-Resolution Weak Supervision for Sequential Data
Oct 21, 2019
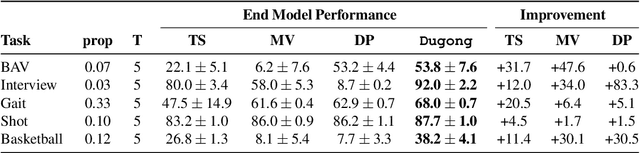
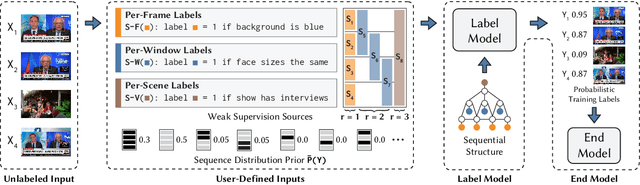

Since manually labeling training data is slow and expensive, recent industrial and scientific research efforts have turned to weaker or noisier forms of supervision sources. However, existing weak supervision approaches fail to model multi-resolution sources for sequential data, like video, that can assign labels to individual elements or collections of elements in a sequence. A key challenge in weak supervision is estimating the unknown accuracies and correlations of these sources without using labeled data. Multi-resolution sources exacerbate this challenge due to complex correlations and sample complexity that scales in the length of the sequence. We propose Dugong, the first framework to model multi-resolution weak supervision sources with complex correlations to assign probabilistic labels to training data. Theoretically, we prove that Dugong, under mild conditions, can uniquely recover the unobserved accuracy and correlation parameters and use parameter sharing to improve sample complexity. Our method assigns clinician-validated labels to population-scale biomedical video repositories, helping outperform traditional supervision by 36.8 F1 points and addressing a key use case where machine learning has been severely limited by the lack of expert labeled data. On average, Dugong improves over traditional supervision by 16.0 F1 points and existing weak supervision approaches by 24.2 F1 points across several video and sensor classification tasks.
Snorkel: Rapid Training Data Creation with Weak Supervision
Nov 28, 2017
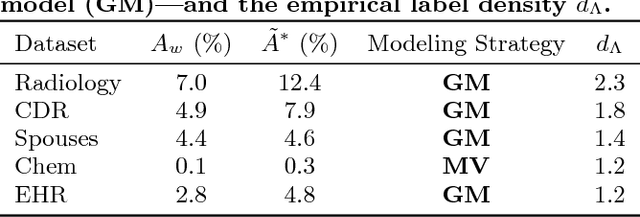

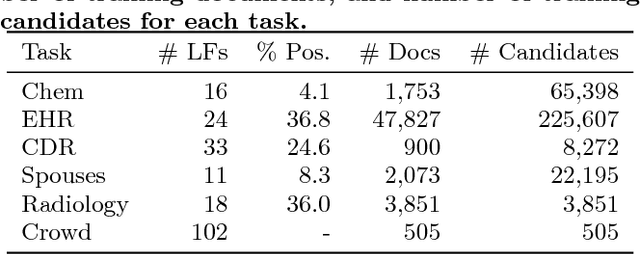
Labeling training data is increasingly the largest bottleneck in deploying machine learning systems. We present Snorkel, a first-of-its-kind system that enables users to train state-of-the-art models without hand labeling any training data. Instead, users write labeling functions that express arbitrary heuristics, which can have unknown accuracies and correlations. Snorkel denoises their outputs without access to ground truth by incorporating the first end-to-end implementation of our recently proposed machine learning paradigm, data programming. We present a flexible interface layer for writing labeling functions based on our experience over the past year collaborating with companies, agencies, and research labs. In a user study, subject matter experts build models 2.8x faster and increase predictive performance an average 45.5% versus seven hours of hand labeling. We study the modeling tradeoffs in this new setting and propose an optimizer for automating tradeoff decisions that gives up to 1.8x speedup per pipeline execution. In two collaborations, with the U.S. Department of Veterans Affairs and the U.S. Food and Drug Administration, and on four open-source text and image data sets representative of other deployments, Snorkel provides 132% average improvements to predictive performance over prior heuristic approaches and comes within an average 3.60% of the predictive performance of large hand-curated training sets.
ShortFuse: Biomedical Time Series Representations in the Presence of Structured Information
May 16, 2017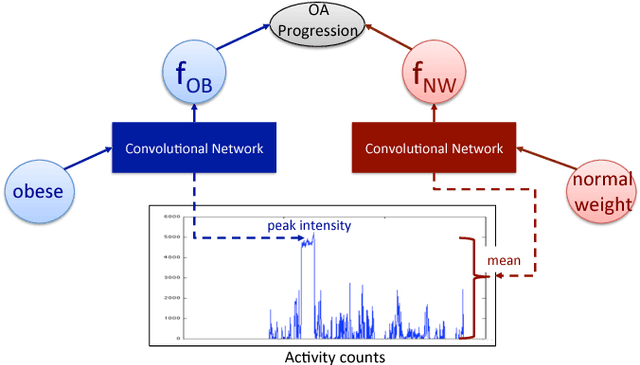
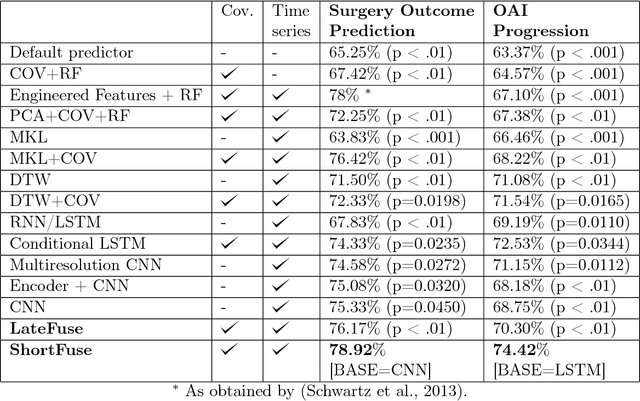
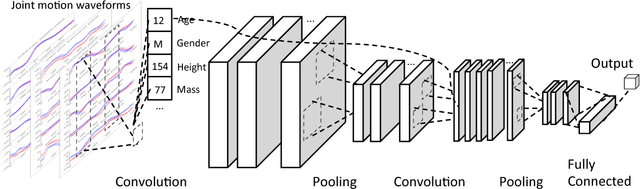
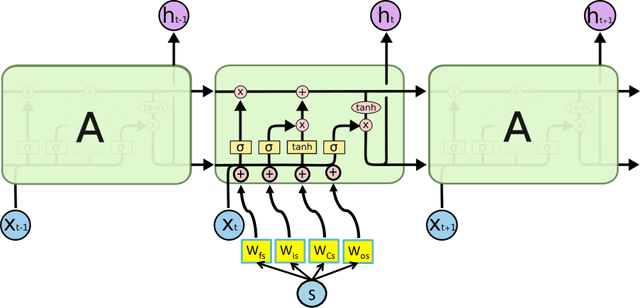
In healthcare applications, temporal variables that encode movement, health status and longitudinal patient evolution are often accompanied by rich structured information such as demographics, diagnostics and medical exam data. However, current methods do not jointly optimize over structured covariates and time series in the feature extraction process. We present ShortFuse, a method that boosts the accuracy of deep learning models for time series by explicitly modeling temporal interactions and dependencies with structured covariates. ShortFuse introduces hybrid convolutional and LSTM cells that incorporate the covariates via weights that are shared across the temporal domain. ShortFuse outperforms competing models by 3% on two biomedical applications, forecasting osteoarthritis-related cartilage degeneration and predicting surgical outcomes for cerebral palsy patients, matching or exceeding the accuracy of models that use features engineered by domain experts.
SwellShark: A Generative Model for Biomedical Named Entity Recognition without Labeled Data
Apr 20, 2017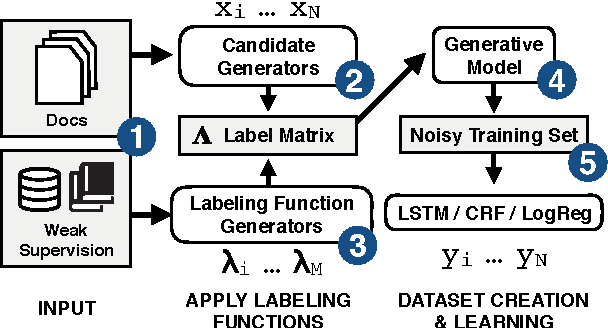

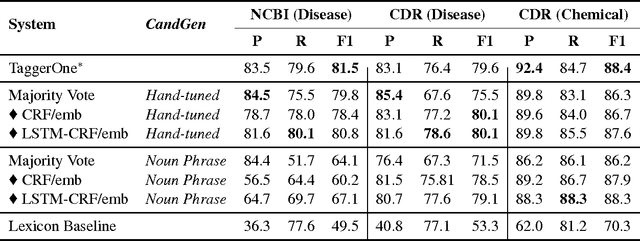
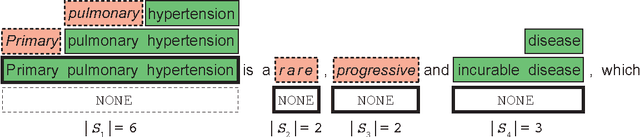
We present SwellShark, a framework for building biomedical named entity recognition (NER) systems quickly and without hand-labeled data. Our approach views biomedical resources like lexicons as function primitives for autogenerating weak supervision. We then use a generative model to unify and denoise this supervision and construct large-scale, probabilistically labeled datasets for training high-accuracy NER taggers. In three biomedical NER tasks, SwellShark achieves competitive scores with state-of-the-art supervised benchmarks using no hand-labeled training data. In a drug name extraction task using patient medical records, one domain expert using SwellShark achieved within 5.1% of a crowdsourced annotation approach -- which originally utilized 20 teams over the course of several weeks -- in 24 hours.