 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeedles in Haystacks: On Classifying Tiny Objects in Large Images
Paper and Code
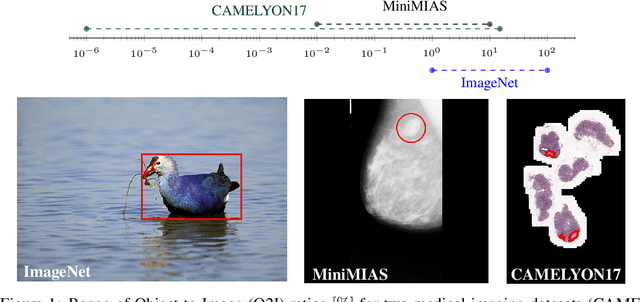
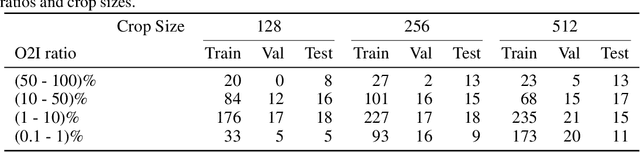
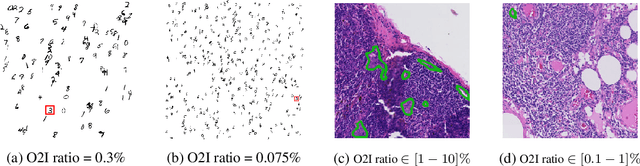
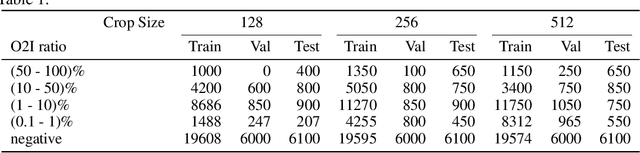
In some computer vision domains, such as medical or hyperspectral imaging, we care about the classification of tiny objects in large images. However, most Convolutional Neural Networks (CNNs) for image classification were developed and analyzed using biased datasets that contain large objects, most often, in central image positions. To assess whether classical CNN architectures work well for tiny object classification we build a comprehensive testbed containing two datasets: one derived from MNIST digits and other from histopathology images. This testbed allows us to perform controlled experiments to stress-test CNN architectures using a broad spectrum of signal-to-noise ratios. Our observations suggest that: (1) There exists a limit to signal-to-noise below which CNNs fail to generalize and that this limit is affected by dataset size - more data leading to better performances; however, the amount of training data required for the model to generalize scales rapidly with the inverse of the object-to-image ratio (2) in general, higher capacity models exhibit better generalization; (3) when knowing the approximate object sizes, adapting receptive field is beneficial; and (4) for very small signal-to-noise ratio the choice of global pooling operation affects optimization, whereas for relatively large signal-to-noise values, all tested global pooling operations exhibit similar performance.