 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
TimeGraphs: Graph-based Temporal Reasoning
Jan 06, 2024Many real-world systems exhibit temporal, dynamic behaviors, which are captured as time series of complex agent interactions. To perform temporal reasoning, current methods primarily encode temporal dynamics through simple sequence-based models. However, in general these models fail to efficiently capture the full spectrum of rich dynamics in the input, since the dynamics is not uniformly distributed. In particular, relevant information might be harder to extract and computing power is wasted for processing all individual timesteps, even if they contain no significant changes or no new information. Here we propose TimeGraphs, a novel approach that characterizes dynamic interactions as a hierarchical temporal graph, diverging from traditional sequential representations. Our approach models the interactions using a compact graph-based representation, enabling adaptive reasoning across diverse time scales. Adopting a self-supervised method, TimeGraphs constructs a multi-level event hierarchy from a temporal input, which is then used to efficiently reason about the unevenly distributed dynamics. This construction process is scalable and incremental to accommodate streaming data. We evaluate TimeGraphs on multiple datasets with complex, dynamic agent interactions, including a football simulator, the Resistance game, and the MOMA human activity dataset. The results demonstrate both robustness and efficiency of TimeGraphs on a range of temporal reasoning tasks. Our approach obtains state-of-the-art performance and leads to a performance increase of up to 12.2% on event prediction and recognition tasks over current approaches. Our experiments further demonstrate a wide array of capabilities including zero-shot generalization, robustness in case of data sparsity, and adaptability to streaming data flow.
F-FADE: Frequency Factorization for Anomaly Detection in Edge Streams
Nov 09, 2020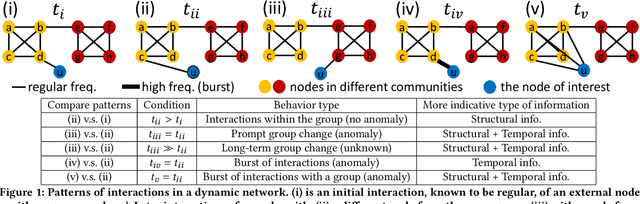

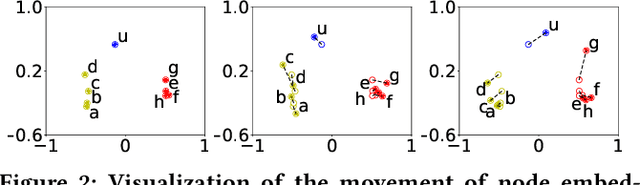

Edge streams are commonly used to capture interactions in dynamic networks, such as email, social, or computer networks. The problem of detecting anomalies or rare events in edge streams has a wide range of applications. However, it presents many challenges due to lack of labels, a highly dynamic nature of interactions, and the entanglement of temporal and structural changes in the network. Current methods are limited in their ability to address the above challenges and to efficiently process a large number of interactions. Here, we propose F-FADE, a new approach for detection of anomalies in edge streams, which uses a novel frequency-factorization technique to efficiently model the time-evolving distributions of frequencies of interactions between node-pairs. The anomalies are then determined based on the likelihood of the observed frequency of each incoming interaction. F-FADE is able to handle in an online streaming setting a broad variety of anomalies with temporal and structural changes, while requiring only constant memory. Our experiments on one synthetic and six real-world dynamic networks show that F-FADE achieves state of the art performance and may detect anomalies that previous methods are unable to find.
CASC: Context-Aware Segmentation and Clustering for Motif Discovery in Noisy Time Series Data
Sep 06, 2018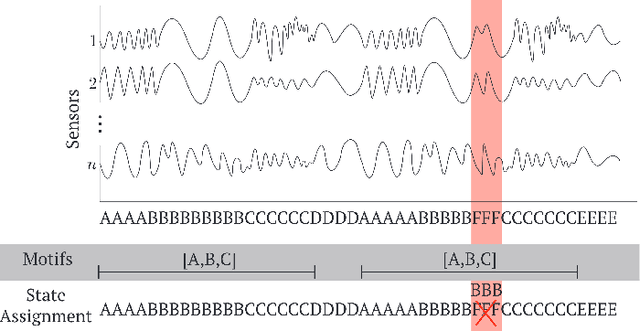
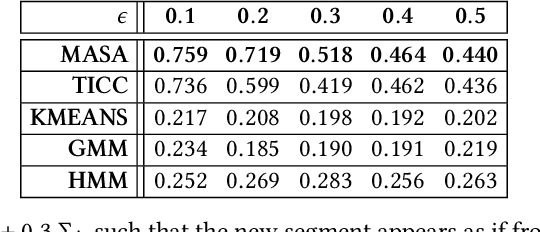
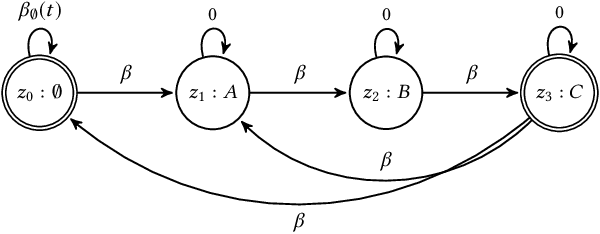
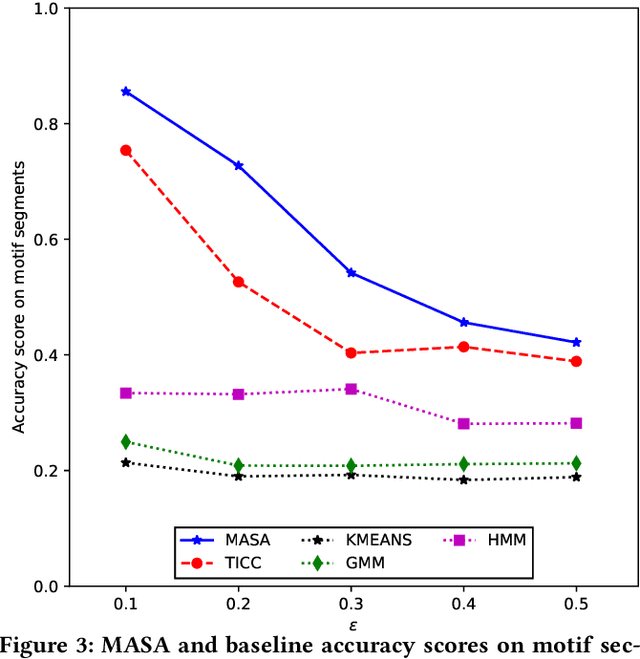
Complex systems, such as airplanes, cars, or financial markets, produce multivariate time series data consisting of system observations over a period of time. Such data can be interpreted as a sequence of segments, where each segment is associated with a certain state of the system. An important problem in this domain is to identify repeated sequences of states, known as motifs. Such motifs correspond to complex behaviors that capture common sequences of state transitions. For example, a motif of "making a turn" might manifest in sensor data as a sequence of states: slowing down, turning the wheel, and then speeding back up. However, discovering these motifs is challenging, because the individual states are unknown and need to be learned from the noisy time series. Simultaneously, the time series also needs to be precisely segmented and each segment needs to be associated with a state. Here we develop context-aware segmentation and clustering (CASC), a method for discovering common motifs in time series data. We formulate the problem of motif discovery as a large optimization problem, which we then solve using a greedy alternating minimization-based approach. CASC performs well in the presence of noise in the input data and is scalable to very large datasets. Furthermore, CASC leverages common motifs to more robustly segment the time series and assign segments to states. Experiments on synthetic data show that CASC outperforms state-of-the-art baselines by up to 38.2%, and two case studies demonstrate how our approach discovers insightful motifs in real-world time series data.
Drive2Vec: Multiscale State-Space Embedding of Vehicular Sensor Data
Jun 12, 2018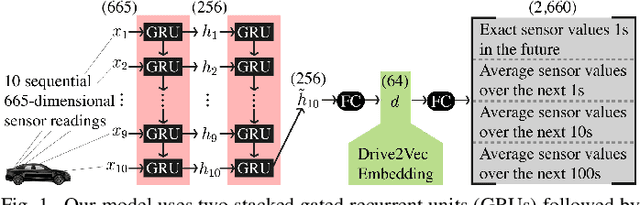
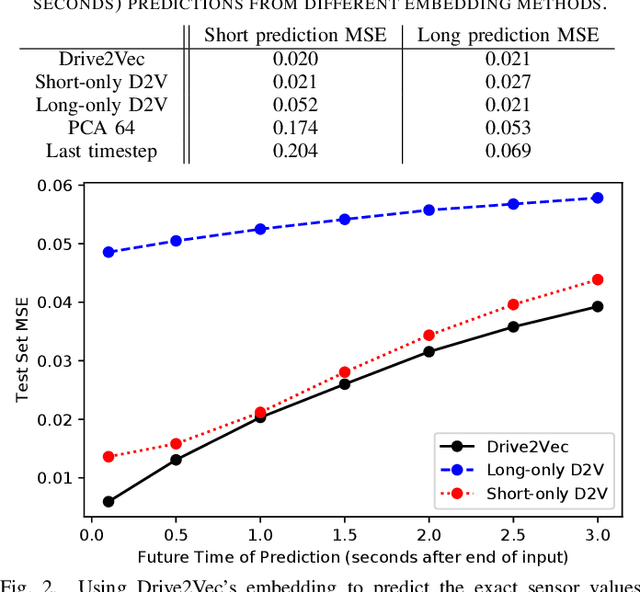
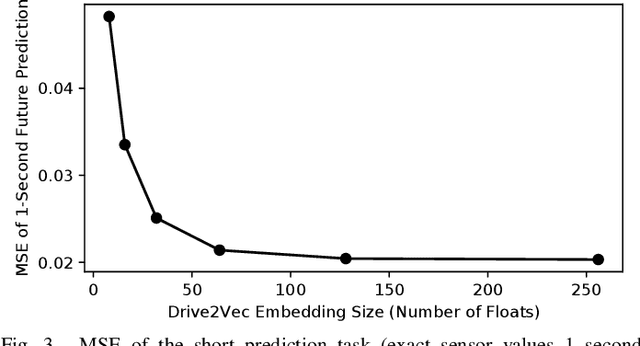

With automobiles becoming increasingly reliant on sensors to perform various driving tasks, it is important to encode the relevant CAN bus sensor data in a way that captures the general state of the vehicle in a compact form. In this paper, we develop a deep learning-based method, called Drive2Vec, for embedding such sensor data in a low-dimensional yet actionable form. Our method is based on stacked gated recurrent units (GRUs). It accepts a short interval of automobile sensor data as input and computes a low-dimensional representation of that data, which can then be used to accurately solve a range of tasks. With this representation, we (1) predict the exact values of the sensors in the short term (up to three seconds in the future), (2) forecast the long-term average values of these same sensors, (3) infer additional contextual information that is not encoded in the data, including the identity of the driver behind the wheel, and (4) build a knowledge base that can be used to auto-label data and identify risky states. We evaluate our approach on a dataset collected by Audi, which equipped a fleet of test vehicles with data loggers to store all sensor readings on 2,098 hours of driving on real roads. We show in several experiments that our method outperforms other baselines by up to 90%, and we further demonstrate how these embeddings of sensor data can be used to solve a variety of real-world automotive applications.
Prioritizing network communities
May 28, 2018
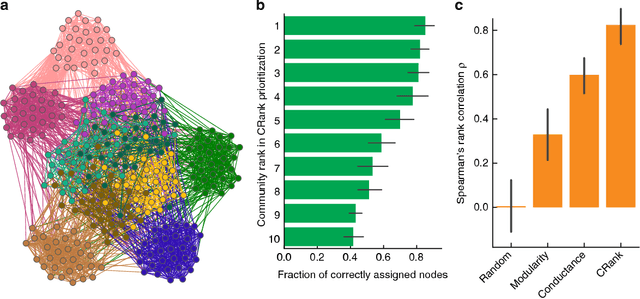
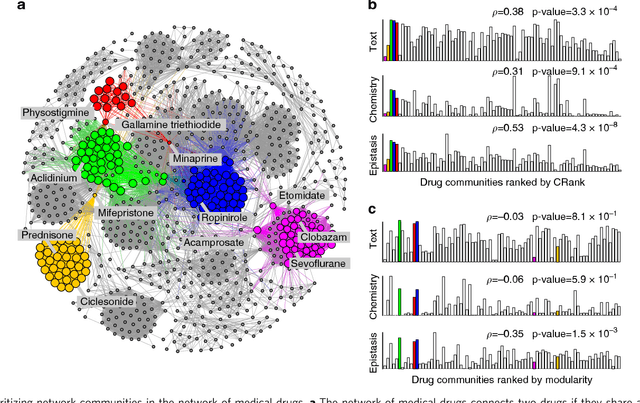

Uncovering modular structure in networks is fundamental for systems in biology, physics, and engineering. Community detection identifies candidate modules as hypotheses, which then need to be validated through experiments, such as mutagenesis in a biological laboratory. Only a few communities can typically be validated, and it is thus important to prioritize which communities to select for downstream experimentation. Here we develop CRank, a mathematically principled approach for prioritizing network communities. CRank efficiently evaluates robustness and magnitude of structural features of each community and then combines these features into the community prioritization. CRank can be used with any community detection method. It needs only information provided by the network structure and does not require any additional metadata or labels. However, when available, CRank can incorporate domain-specific information to further boost performance. Experiments on many large networks show that CRank effectively prioritizes communities, yielding a nearly 50-fold improvement in community prioritization.
Driver Identification Using Automobile Sensor Data from a Single Turn
Jun 09, 2017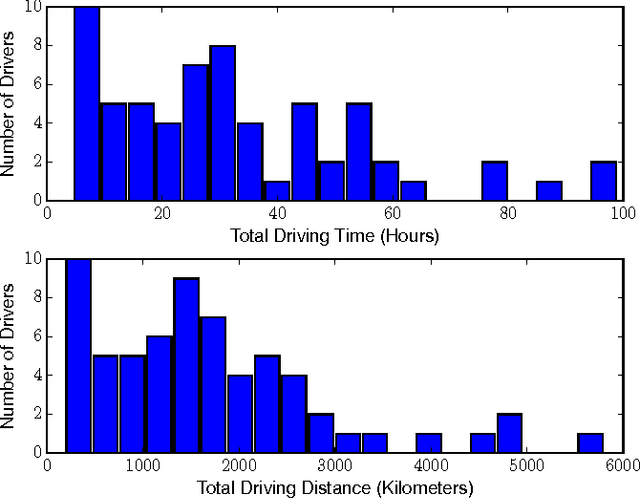

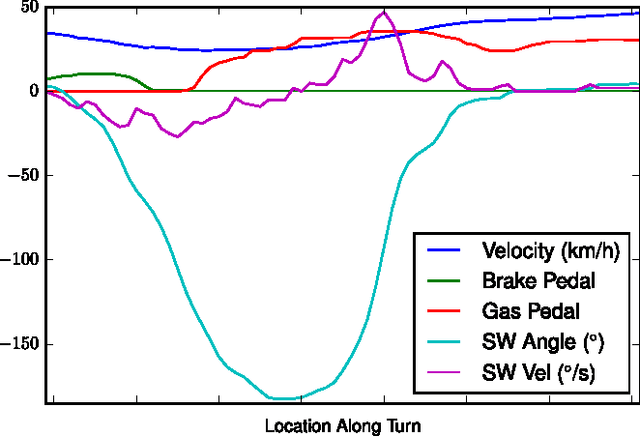

As automotive electronics continue to advance, cars are becoming more and more reliant on sensors to perform everyday driving operations. These sensors are omnipresent and help the car navigate, reduce accidents, and provide comfortable rides. However, they can also be used to learn about the drivers themselves. In this paper, we propose a method to predict, from sensor data collected at a single turn, the identity of a driver out of a given set of individuals. We cast the problem in terms of time series classification, where our dataset contains sensor readings at one turn, repeated several times by multiple drivers. We build a classifier to find unique patterns in each individual's driving style, which are visible in the data even on such a short road segment. To test our approach, we analyze a new dataset collected by AUDI AG and Audi Electronics Venture, where a fleet of test vehicles was equipped with automotive data loggers storing all sensor readings on real roads. We show that turns are particularly well-suited for detecting variations across drivers, especially when compared to straightaways. We then focus on the 12 most frequently made turns in the dataset, which include rural, urban, highway on-ramps, and more, obtaining accurate identification results and learning useful insights about driver behavior in a variety of settings.