 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Cross-Lingual and Cross-Domain Crisis Classification for Low-Resource Scenarios
Sep 05, 2022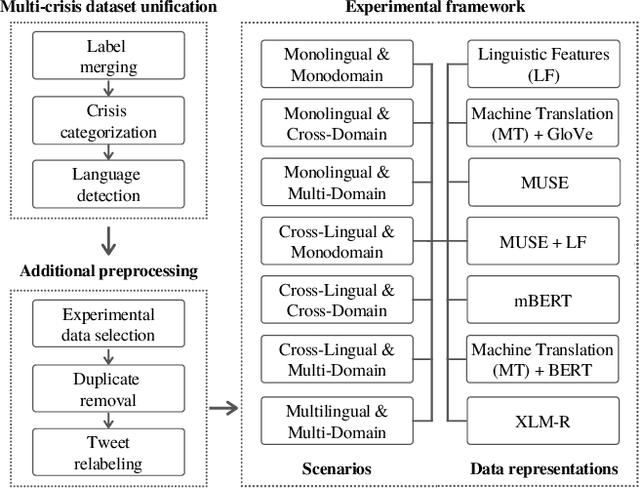
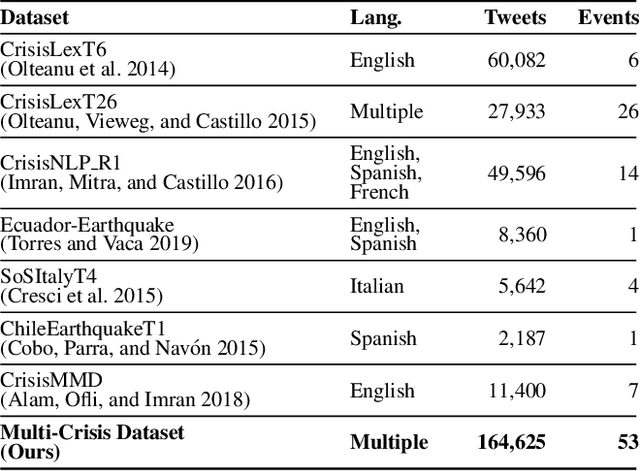
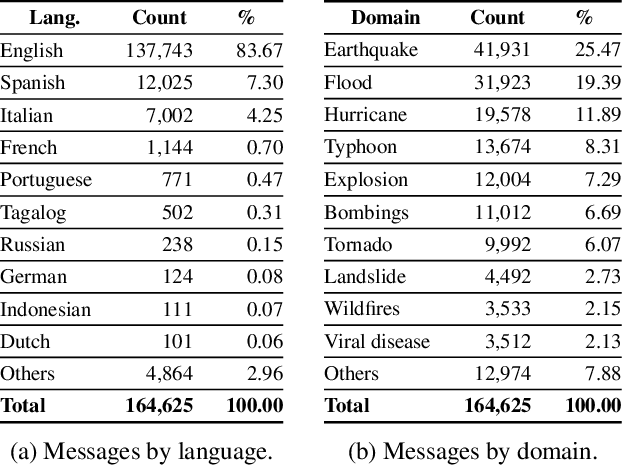
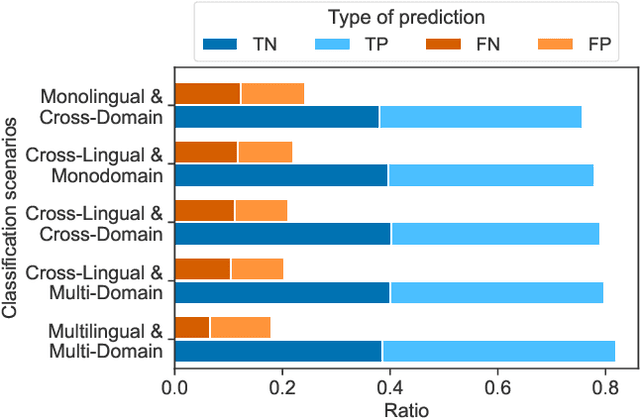
Social media data has emerged as a useful source of timely information about real-world crisis events. One of the main tasks related to the use of social media for disaster management is the automatic identification of crisis-related messages. Most of the studies on this topic have focused on the analysis of data for a particular type of event in a specific language. This limits the possibility of generalizing existing approaches because models cannot be directly applied to new types of events or other languages. In this work, we study the task of automatically classifying messages that are related to crisis events by leveraging cross-language and cross-domain labeled data. Our goal is to make use of labeled data from high-resource languages to classify messages from other (low-resource) languages and/or of new (previously unseen) types of crisis situations. For our study we consolidated from the literature a large unified dataset containing multiple crisis events and languages. Our empirical findings show that it is indeed possible to leverage data from crisis events in English to classify the same type of event in other languages, such as Spanish and Italian (80.0% F1-score). Furthermore, we achieve good performance for the cross-domain task (80.0% F1-score) in a cross-lingual setting. Overall, our work contributes to improving the data scarcity problem that is so important for multilingual crisis classification. In particular, mitigating cold-start situations in emergency events, when time is of essence.
Detecting Polarized Topics in COVID-19 News Using Partisanship-aware Contextualized Topic Embeddings
Apr 15, 2021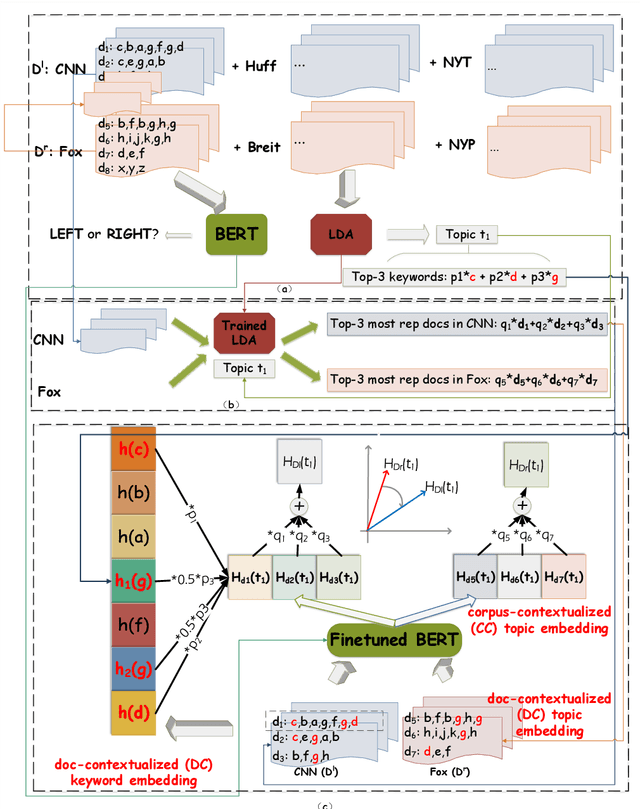

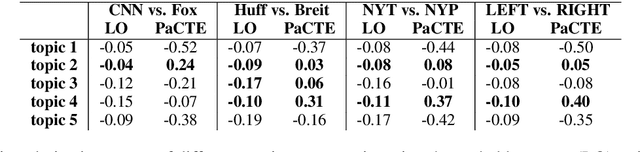
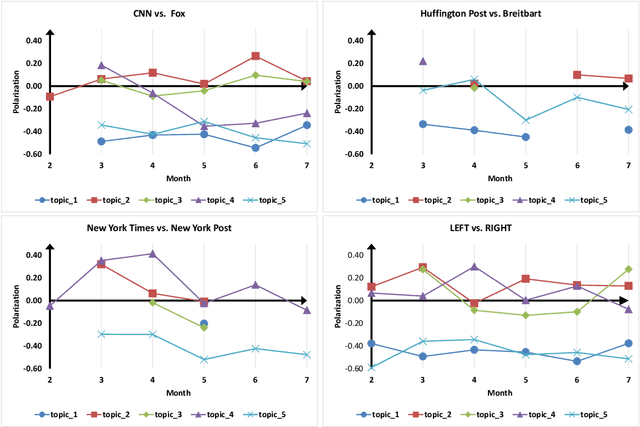
Growing polarization of the news media has been blamed for fanning disagreement, controversy and even violence. Early identification of polarized topics is thus an urgent matter that can help mitigate conflict. However, accurate measurement of polarization is still an open research challenge. To address this gap, we propose Partisanship-aware Contextualized Topic Embeddings (PaCTE), a method to automatically detect polarized topics from partisan news sources. Specifically, we represent the ideology of a news source on a topic by corpus-contextualized topic embedding utilizing a language model that has been finetuned on recognizing partisanship of the news articles, and measure the polarization between sources using cosine similarity. We apply our method to a corpus of news about COVID-19 pandemic. Extensive experiments on different news sources and topics demonstrate the effectiveness of our method to precisely capture the topical polarization and alignment between different news sources. To help clarify and validate results, we explain the polarization using the Moral Foundation Theory.
Leveraging Clickstream Trajectories to Reveal Low-Quality Workers in Crowdsourced Forecasting Platforms
Sep 04, 2020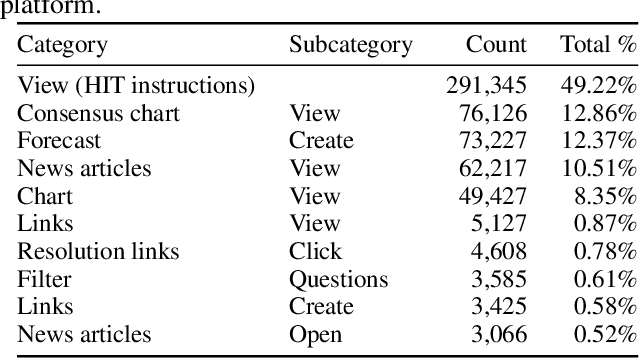
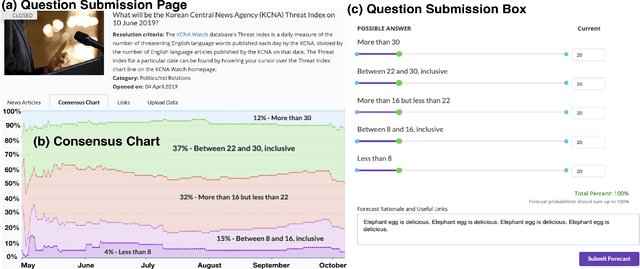
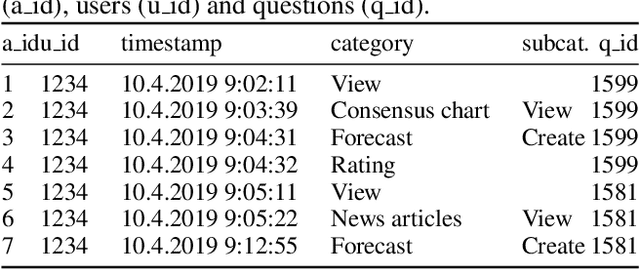
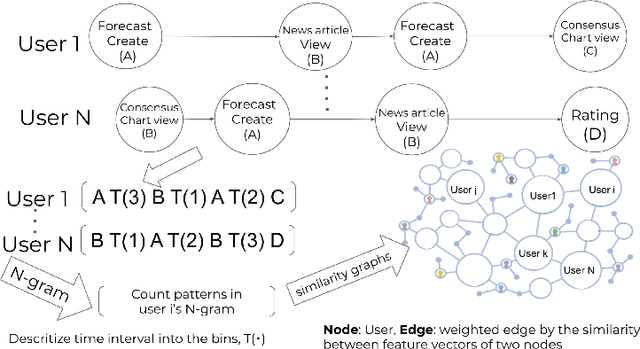
Crowdwork often entails tackling cognitively-demanding and time-consuming tasks. Crowdsourcing can be used for complex annotation tasks, from medical imaging to geospatial data, and such data powers sensitive applications, such as health diagnostics or autonomous driving. However, the existence and prevalence of underperforming crowdworkers is well-recognized, and can pose a threat to the validity of crowdsourcing. In this study, we propose the use of a computational framework to identify clusters of underperforming workers using clickstream trajectories. We focus on crowdsourced geopolitical forecasting. The framework can reveal different types of underperformers, such as workers with forecasts whose accuracy is far from the consensus of the crowd, those who provide low-quality explanations for their forecasts, and those who simply copy-paste their forecasts from other users. Our study suggests that clickstream clustering and analysis are fundamental tools to diagnose the performance of crowdworkers in platforms leveraging the wisdom of crowds.
A Computational Model of Commonsense Moral Decision Making
Jan 12, 2018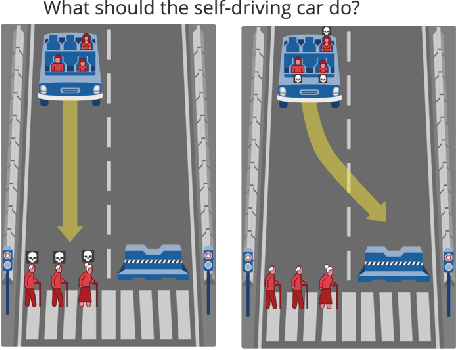

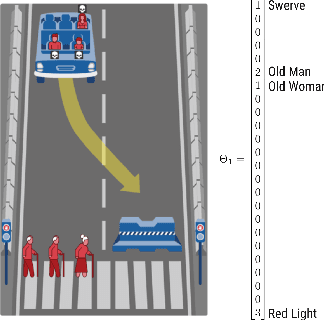
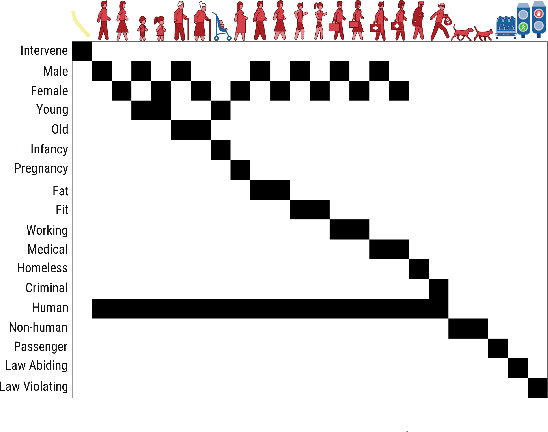
We introduce a new computational model of moral decision making, drawing on a recent theory of commonsense moral learning via social dynamics. Our model describes moral dilemmas as a utility function that computes trade-offs in values over abstract moral dimensions, which provide interpretable parameter values when implemented in machine-led ethical decision-making. Moreover, characterizing the social structures of individuals and groups as a hierarchical Bayesian model, we show that a useful description of an individual's moral values - as well as a group's shared values - can be inferred from a limited amount of observed data. Finally, we apply and evaluate our approach to data from the Moral Machine, a web application that collects human judgments on moral dilemmas involving autonomous vehicles.
Superintelligence cannot be contained: Lessons from Computability Theory
Jul 04, 2016



Superintelligence is a hypothetical agent that possesses intelligence far surpassing that of the brightest and most gifted human minds. In light of recent advances in machine intelligence, a number of scientists, philosophers and technologists have revived the discussion about the potential catastrophic risks entailed by such an entity. In this article, we trace the origins and development of the neo-fear of superintelligence, and some of the major proposals for its containment. We argue that such containment is, in principle, impossible, due to fundamental limits inherent to computing itself. Assuming that a superintelligence will contain a program that includes all the programs that can be executed by a universal Turing machine on input potentially as complex as the state of the world, strict containment requires simulations of such a program, something theoretically (and practically) infeasible.
Interdependent Scheduling Games
May 31, 2016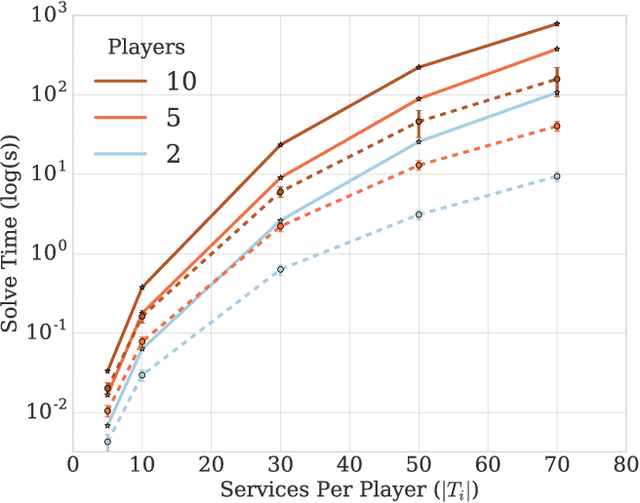
We propose a model of interdependent scheduling games in which each player controls a set of services that they schedule independently. A player is free to schedule his own services at any time; however, each of these services only begins to accrue reward for the player when all predecessor services, which may or may not be controlled by the same player, have been activated. This model, where players have interdependent services, is motivated by the problems faced in planning and coordinating large-scale infrastructures, e.g., restoring electricity and gas to residents after a natural disaster or providing medical care in a crisis when different agencies are responsible for the delivery of staff, equipment, and medicine. We undertake a game-theoretic analysis of this setting and in particular consider the issues of welfare maximization, computing best responses, Nash dynamics, and existence and computation of Nash equilibria.