 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanish Pre-trained BERT Model and Evaluation Data
Aug 06, 2023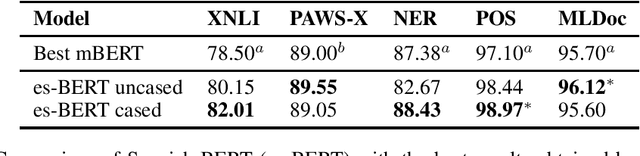

The Spanish language is one of the top 5 spoken languages in the world. Nevertheless, finding resources to train or evaluate Spanish language models is not an easy task. In this paper we help bridge this gap by presenting a BERT-based language model pre-trained exclusively on Spanish data. As a second contribution, we also compiled several tasks specifically for the Spanish language in a single repository much in the spirit of the GLUE benchmark. By fine-tuning our pre-trained Spanish model, we obtain better results compared to other BERT-based models pre-trained on multilingual corpora for most of the tasks, even achieving a new state-of-the-art on some of them. We have publicly released our model, the pre-training data, and the compilation of the Spanish benchmarks.
QuickCent: a fast and frugal heuristic for harmonic centrality estimation on scale-free networks
Mar 02, 2023


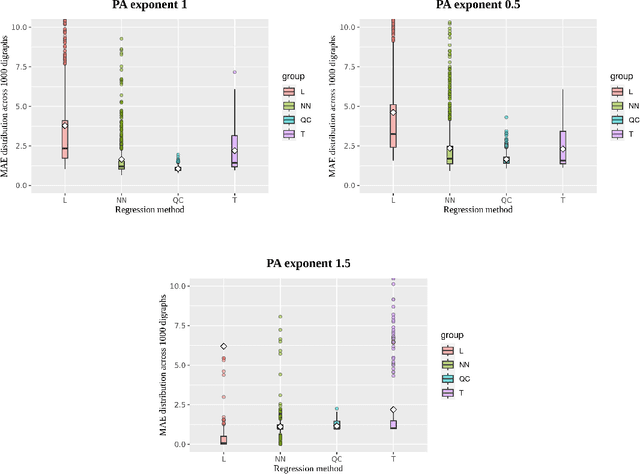
We present a simple and quick method to approximate network centrality indexes. Our approach, called QuickCent, is inspired by so-called fast and frugal heuristics, which are heuristics initially proposed to model some human decision and inference processes. The centrality index that we estimate is the harmonic centrality, which is a measure based on shortest-path distances, so infeasible to compute on large networks. We compare QuickCent with known machine learning algorithms on synthetic data generated with preferential attachment, and some empirical networks. Our experiments show that QuickCent is able to make estimates that are competitive in accuracy with the best alternative methods tested, either on synthetic scale-free networks or empirical networks. QuickCent has the feature of achieving low error variance estimates, even with a small training set. Moreover, QuickCent is comparable in efficiency -- accuracy and time cost -- to those produced by more complex methods. We discuss and provide some insight into how QuickCent exploits the fact that in some networks, such as those generated by preferential attachment, local density measures such as the in-degree, can be a proxy for the size of the network region to which a node has access, opening up the possibility of approximating centrality indices based on size such as the harmonic centrality. Our initial results show that simple heuristics and biologically inspired computational methods are a promising line of research in the context of network measure estimations.
Cross-Lingual and Cross-Domain Crisis Classification for Low-Resource Scenarios
Sep 05, 2022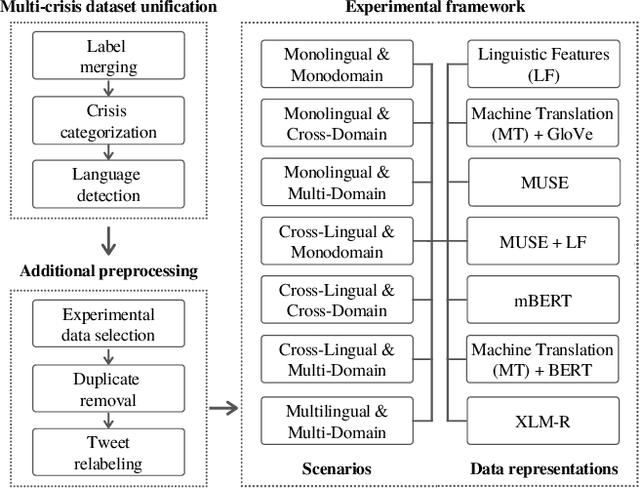
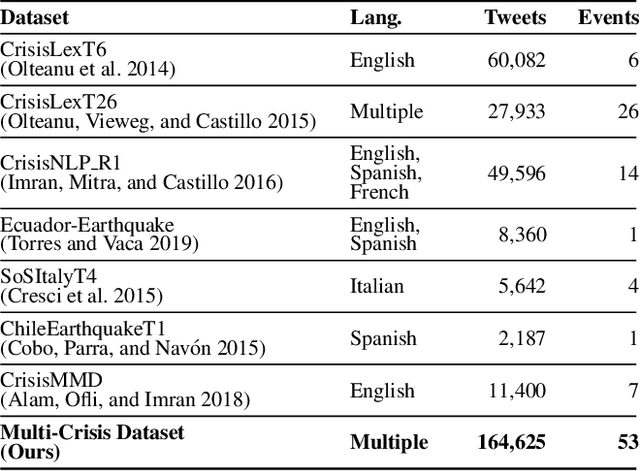
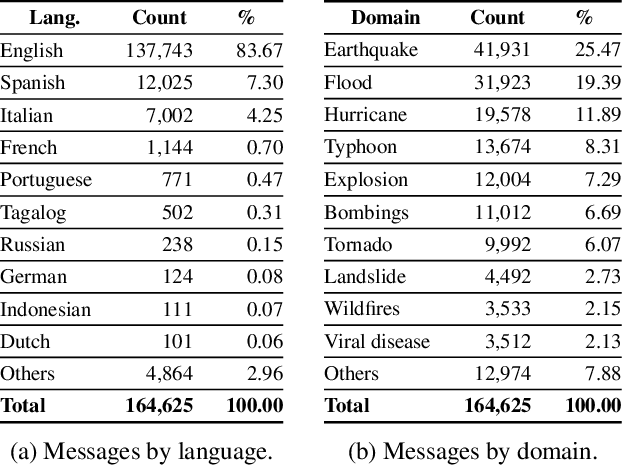
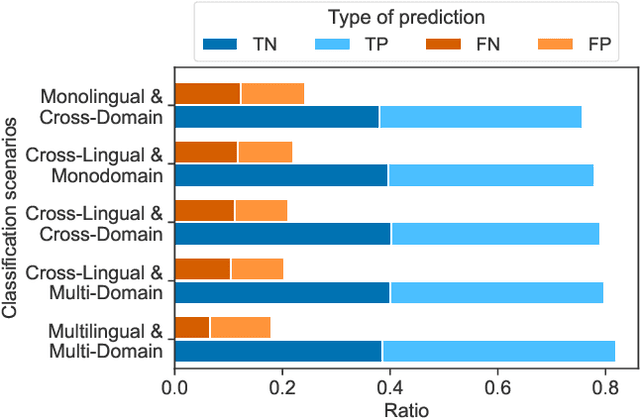
Social media data has emerged as a useful source of timely information about real-world crisis events. One of the main tasks related to the use of social media for disaster management is the automatic identification of crisis-related messages. Most of the studies on this topic have focused on the analysis of data for a particular type of event in a specific language. This limits the possibility of generalizing existing approaches because models cannot be directly applied to new types of events or other languages. In this work, we study the task of automatically classifying messages that are related to crisis events by leveraging cross-language and cross-domain labeled data. Our goal is to make use of labeled data from high-resource languages to classify messages from other (low-resource) languages and/or of new (previously unseen) types of crisis situations. For our study we consolidated from the literature a large unified dataset containing multiple crisis events and languages. Our empirical findings show that it is indeed possible to leverage data from crisis events in English to classify the same type of event in other languages, such as Spanish and Italian (80.0% F1-score). Furthermore, we achieve good performance for the cross-domain task (80.0% F1-score) in a cross-lingual setting. Overall, our work contributes to improving the data scarcity problem that is so important for multilingual crisis classification. In particular, mitigating cold-start situations in emergency events, when time is of essence.
Foundations of Symbolic Languages for Model Interpretability
Oct 05, 2021
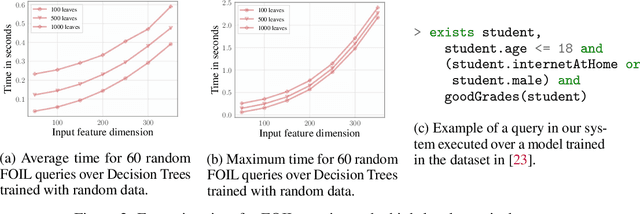
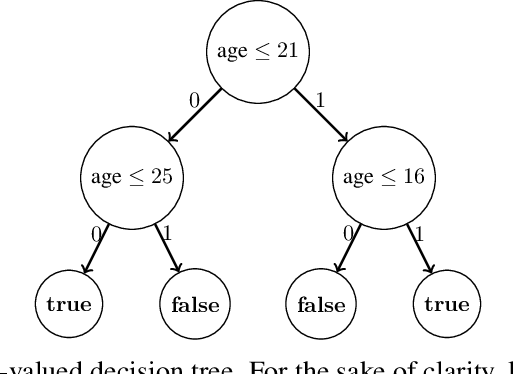
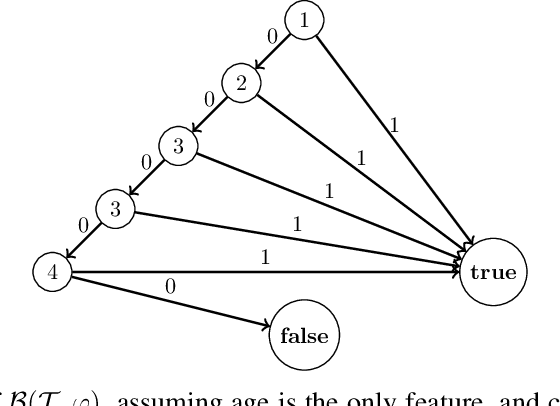
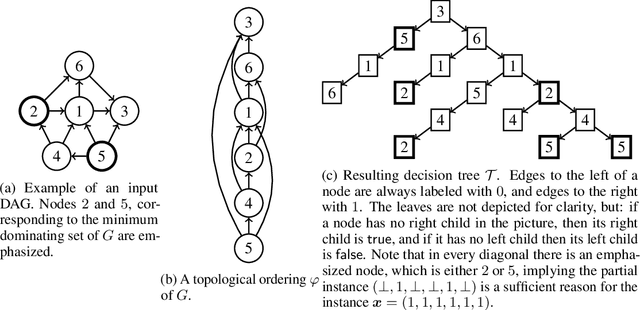
Several queries and scores have recently been proposed to explain individual predictions over ML models. Given the need for flexible, reliable, and easy-to-apply interpretability methods for ML models, we foresee the need for developing declarative languages to naturally specify different explainability queries. We do this in a principled way by rooting such a language in a logic, called FOIL, that allows for expressing many simple but important explainability queries, and might serve as a core for more expressive interpretability languages. We study the computational complexity of FOIL queries over two classes of ML models often deemed to be easily interpretable: decision trees and OBDDs. Since the number of possible inputs for an ML model is exponential in its dimension, the tractability of the FOIL evaluation problem is delicate but can be achieved by either restricting the structure of the models or the fragment of FOIL being evaluated. We also present a prototype implementation of FOIL wrapped in a high-level declarative language and perform experiments showing that such a language can be used in practice.
Cross-lingual hate speech detection based on multilingual domain-specific word embeddings
Apr 30, 2021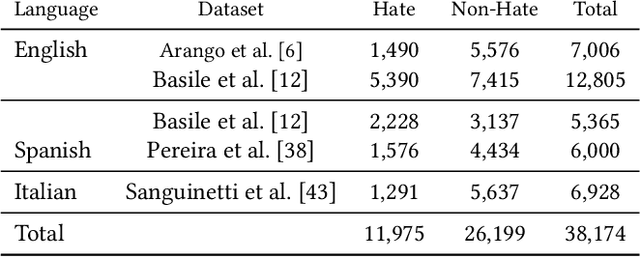
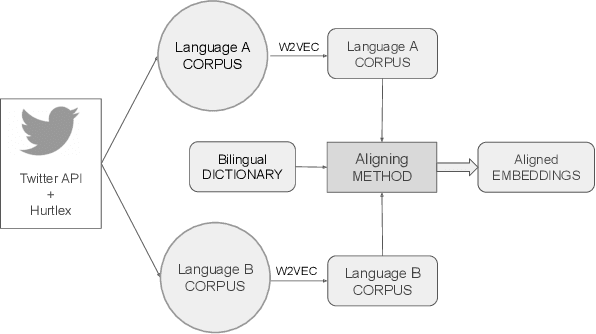
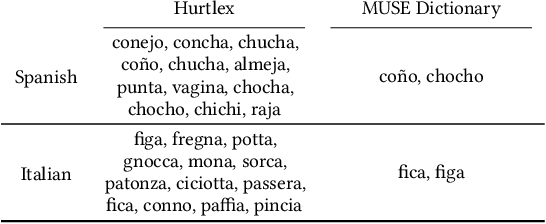

Automatic hate speech detection in online social networks is an important open problem in Natural Language Processing (NLP). Hate speech is a multidimensional issue, strongly dependant on language and cultural factors. Despite its relevance, research on this topic has been almost exclusively devoted to English. Most supervised learning resources, such as labeled datasets and NLP tools, have been created for this same language. Considering that a large portion of users worldwide speak in languages other than English, there is an important need for creating efficient approaches for multilingual hate speech detection. In this work we propose to address the problem of multilingual hate speech detection from the perspective of transfer learning. Our goal is to determine if knowledge from one particular language can be used to classify other language, and to determine effective ways to achieve this. We propose a hate specific data representation and evaluate its effectiveness against general-purpose universal representations most of which, unlike our proposed model, have been trained on massive amounts of data. We focus on a cross-lingual setting, in which one needs to classify hate speech in one language without having access to any labeled data for that language. We show that the use of our simple yet specific multilingual hate representations improves classification results. We explain this with a qualitative analysis showing that our specific representation is able to capture some common patterns in how hate speech presents itself in different languages. Our proposal constitutes, to the best of our knowledge, the first attempt for constructing multilingual specific-task representations. Despite its simplicity, our model outperformed the previous approaches for most of the experimental setups. Our findings can orient future solutions toward the use of domain-specific representations.
Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review
Mar 27, 2021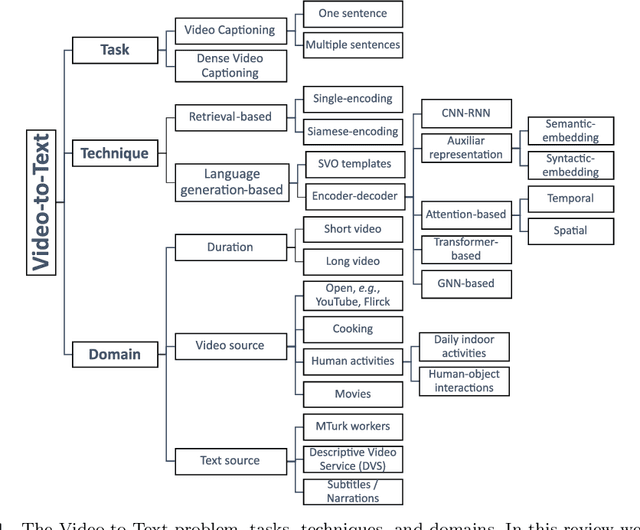
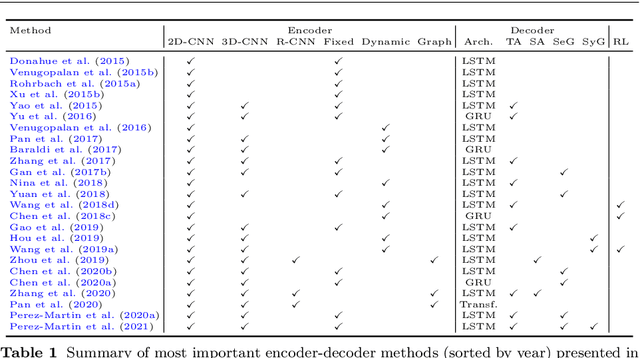
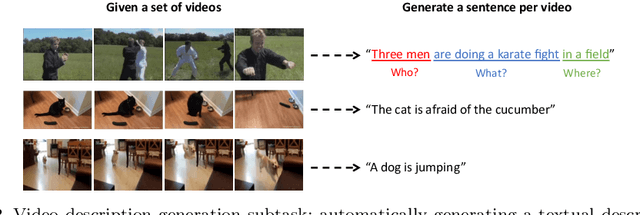
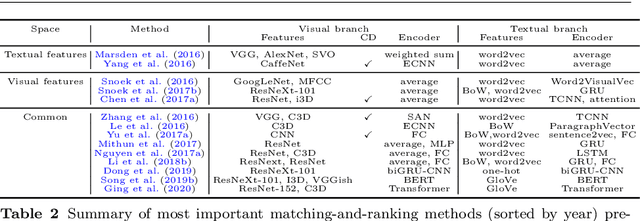
Research in the area of Vision and Language encompasses challenging topics that seek to connect visual and textual information. The video-to-text problem is one of these topics, in which the goal is to connect an input video with its textual description. This connection can be mainly made by retrieving the most significant descriptions from a corpus or generating a new one given a context video. These two ways represent essential tasks for Computer Vision and Natural Language Processing communities, called text retrieval from video task and video captioning/description task. These two tasks are substantially more complex than predicting or retrieving a single sentence from an image. The spatiotemporal information present in videos introduces diversity and complexity regarding the visual content and the structure of associated language descriptions. This review categorizes and describes the state-of-the-art techniques for the video-to-text problem. It covers the main video-to-text methods and the ways to evaluate their performance. We analyze how the most reported benchmark datasets have been created, showing their drawbacks and strengths for the problem requirements. We also show the impressive progress that researchers have made on each dataset, and we analyze why, despite this progress, the video-to-text conversion is still unsolved. State-of-the-art techniques are still a long way from achieving human-like performance in generating or retrieving video descriptions. We cover several significant challenges in the field and discuss future research directions.
Model Interpretability through the Lens of Computational Complexity
Oct 23, 2020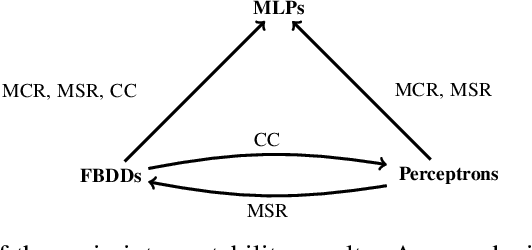

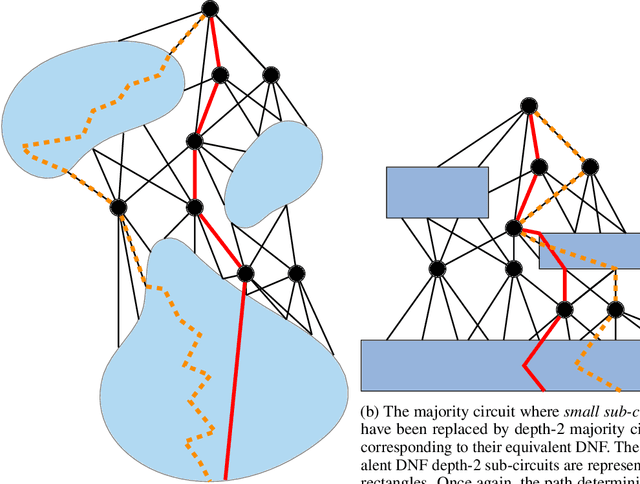
In spite of several claims stating that some models are more interpretable than others -- e.g., "linear models are more interpretable than deep neural networks" -- we still lack a principled notion of interpretability to formally compare among different classes of models. We make a step towards such a notion by studying whether folklore interpretability claims have a correlate in terms of computational complexity theory. We focus on local post-hoc explainability queries that, intuitively, attempt to answer why individual inputs are classified in a certain way by a given model. In a nutshell, we say that a class $\mathcal{C}_1$ of models is more interpretable than another class $\mathcal{C}_2$, if the computational complexity of answering post-hoc queries for models in $\mathcal{C}_2$ is higher than for those in $\mathcal{C}_1$. We prove that this notion provides a good theoretical counterpart to current beliefs on the interpretability of models; in particular, we show that under our definition and assuming standard complexity-theoretical assumptions (such as P$\neq$NP), both linear and tree-based models are strictly more interpretable than neural networks. Our complexity analysis, however, does not provide a clear-cut difference between linear and tree-based models, as we obtain different results depending on the particular post-hoc explanations considered. Finally, by applying a finer complexity analysis based on parameterized complexity, we are able to prove a theoretical result suggesting that shallow neural networks are more interpretable than deeper ones.
Predicting Unplanned Readmissions with Highly Unstructured Data
Apr 05, 2020
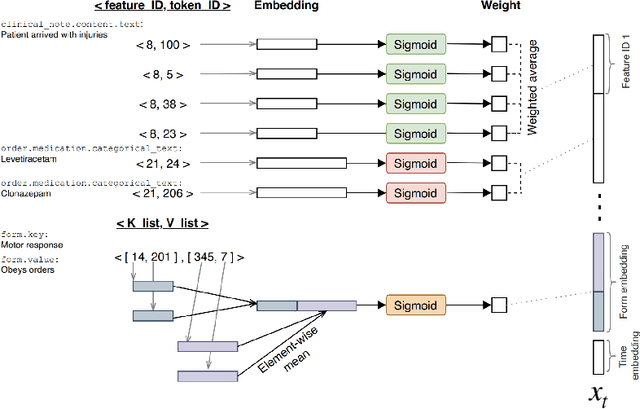

Deep learning techniques have been successfully applied to predict unplanned readmissions of patients in medical centers. The training data for these models is usually based on historical medical records that contain a significant amount of free-text from admission reports, referrals, exam notes, etc. Most of the models proposed so far are tailored to English text data and assume that electronic medical records follow standards common in developed countries. These two characteristics make them difficult to apply in developing countries that do not necessarily follow international standards for registering patient information, or that store text information in languages other than English. In this paper we propose a deep learning architecture for predicting unplanned readmissions that consumes data that is significantly less structured compared with previous models in the literature. We use it to present the first results for this task in a large clinical dataset that mainly contains Spanish text data. The dataset is composed of almost 10 years of records in a Chilean medical center. On this dataset, our model achieves results that are comparable to some of the most recent results obtained in US medical centers for the same task (0.76 AUROC).
On the Turing Completeness of Modern Neural Network Architectures
Jan 10, 2019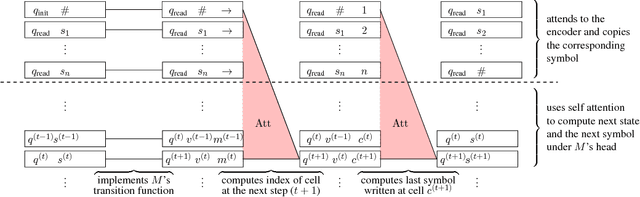
Alternatives to recurrent neural networks, in particular, architectures based on attention or convolutions, have been gaining momentum for processing input sequences. In spite of their relevance, the computational properties of these alternatives have not yet been fully explored. We study the computational power of two of the most paradigmatic architectures exemplifying these mechanisms: the Transformer (Vaswani et al., 2017) and the Neural GPU (Kaiser & Sutskever, 2016). We show both models to be Turing complete exclusively based on their capacity to compute and access internal dense representations of the data. In particular, neither the Transformer nor the Neural GPU requires access to an external memory to become Turing complete. Our study also reveals some minimal sets of elements needed to obtain these completeness results.