 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetrization of 3D Generative Models
Dec 22, 2025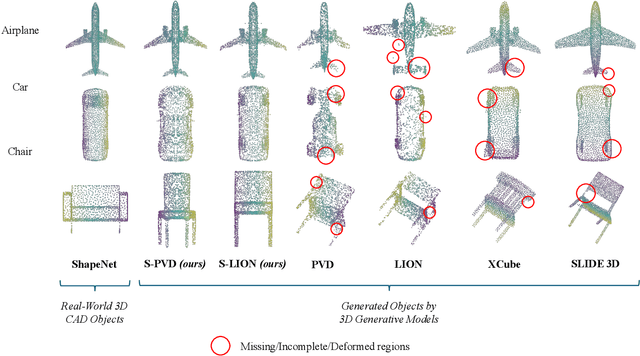
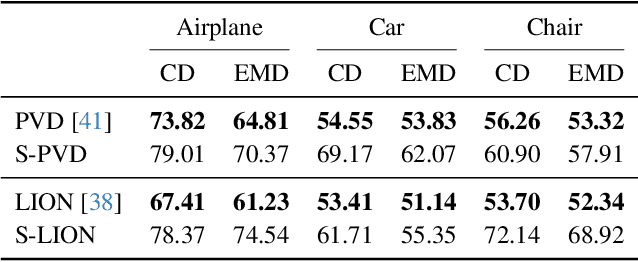
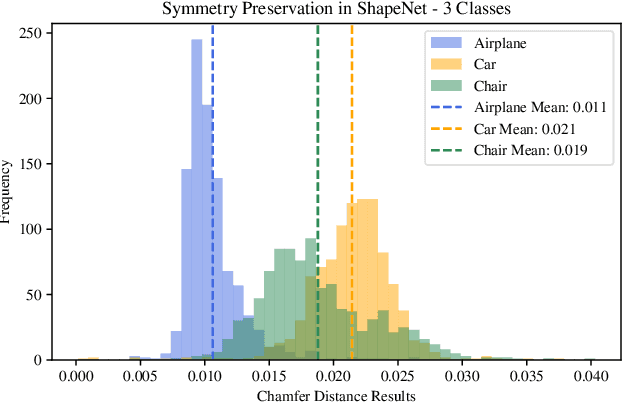
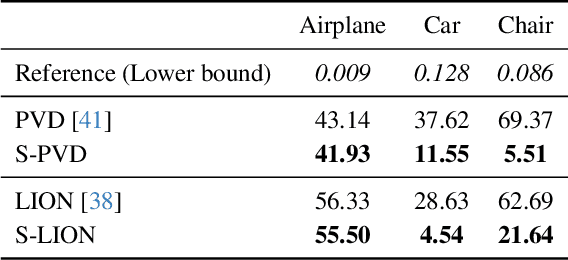
We propose a novel data-centric approach to promote symmetry in 3D generative models by modifying the training data rather than the model architecture. Our method begins with an analysis of reflectional symmetry in both real-world 3D shapes and samples generated by state-of-the-art models. We hypothesize that training a generative model exclusively on half-objects, obtained by reflecting one half of the shapes along the x=0 plane, enables the model to learn a rich distribution of partial geometries which, when reflected during generation, yield complete shapes that are both visually plausible and geometrically symmetric. To test this, we construct a new dataset of half-objects from three ShapeNet classes (Airplane, Car, and Chair) and train two generative models. Experiments demonstrate that the generated shapes are symmetrical and consistent, compared with the generated objects from the original model and the original dataset objects.
Training-free zero-shot 3D symmetry detection with visual features back-projected to geometry
May 30, 2025



We present a simple yet effective training-free approach for zero-shot 3D symmetry detection that leverages visual features from foundation vision models such as DINOv2. Our method extracts features from rendered views of 3D objects and backprojects them onto the original geometry. We demonstrate the symmetric invariance of these features and use them to identify reflection-symmetry planes through a proposed algorithm. Experiments on a subset of ShapeNet demonstrate that our approach outperforms both traditional geometric methods and learning-based approaches without requiring any training data. Our work demonstrates how foundation vision models can help in solving complex 3D geometric problems such as symmetry detection.
A dataset-free approach for self-supervised learning of 3D reflectional symmetries
Mar 05, 2025



In this paper, we explore a self-supervised model that learns to detect the symmetry of a single object without requiring a dataset-relying solely on the input object itself. We hypothesize that the symmetry of an object can be determined by its intrinsic features, eliminating the need for large datasets during training. Additionally, we design a self-supervised learning strategy that removes the necessity of ground truth labels. These two key elements make our approach both effective and efficient, addressing the prohibitive costs associated with constructing large, labeled datasets for this task. The novelty of our method lies in computing features for each point on the object based on the idea that symmetric points should exhibit similar visual appearances. To achieve this, we leverage features extracted from a foundational image model to compute a visual descriptor for the points. This approach equips the point cloud with visual features that facilitate the optimization of our self-supervised model. Experimental results demonstrate that our method surpasses the state-of-the-art models trained on large datasets. Furthermore, our model is more efficient, effective, and operates with minimal computational and data resources.
Cultural Heritage 3D Reconstruction with Diffusion Networks
Oct 14, 2024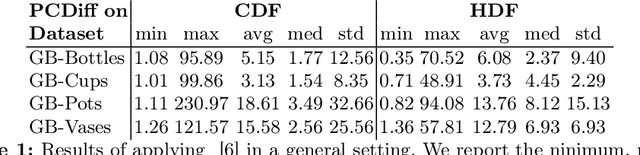

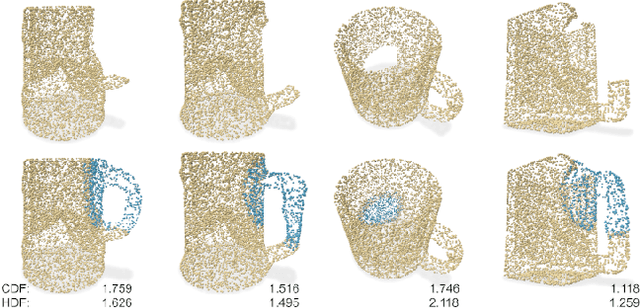

This article explores the use of recent generative AI algorithms for repairing cultural heritage objects, leveraging a conditional diffusion model designed to reconstruct 3D point clouds effectively. Our study evaluates the model's performance across general and cultural heritage-specific settings. Results indicate that, with considerations for object variability, the diffusion model can accurately reproduce cultural heritage geometries. Despite encountering challenges like data diversity and outlier sensitivity, the model demonstrates significant potential in artifact restoration research. This work lays groundwork for advancing restoration methodologies for ancient artifacts using AI technologies.
SHREC 2022: pothole and crack detection in the road pavement using images and RGB-D data
May 27, 2022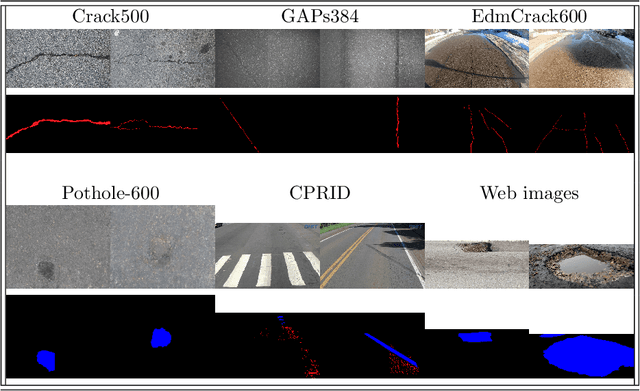
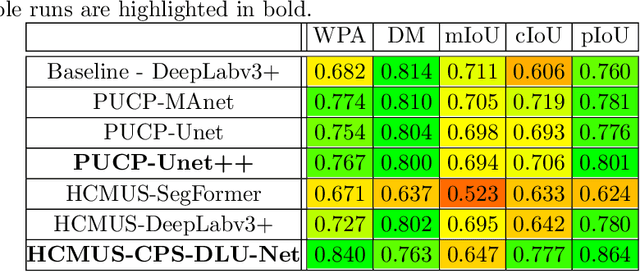

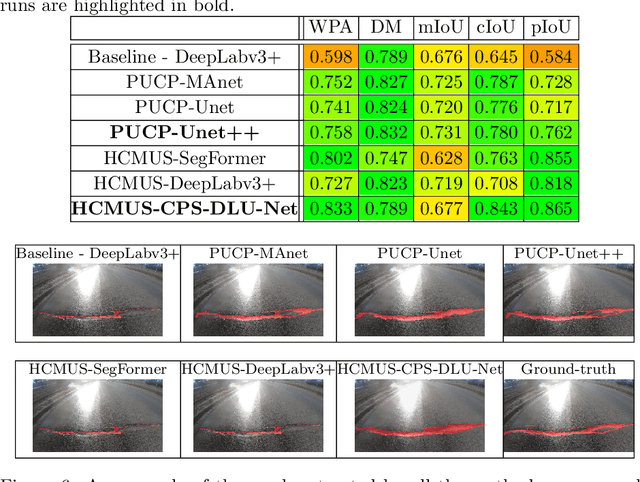
This paper describes the methods submitted for evaluation to the SHREC 2022 track on pothole and crack detection in the road pavement. A total of 7 different runs for the semantic segmentation of the road surface are compared, 6 from the participants plus a baseline method. All methods exploit Deep Learning techniques and their performance is tested using the same environment (i.e.: a single Jupyter notebook). A training set, composed of 3836 semantic segmentation image/mask pairs and 797 RGB-D video clips collected with the latest depth cameras was made available to the participants. The methods are then evaluated on the 496 image/mask pairs in the validation set, on the 504 pairs in the test set and finally on 8 video clips. The analysis of the results is based on quantitative metrics for image segmentation and qualitative analysis of the video clips. The participation and the results show that the scenario is of great interest and that the use of RGB-D data is still challenging in this context.
Bridging Vision and Language from the Video-to-Text Perspective: A Comprehensive Review
Mar 27, 2021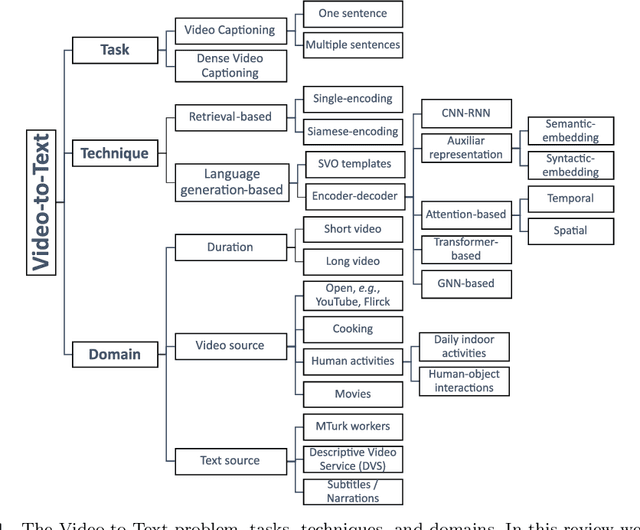
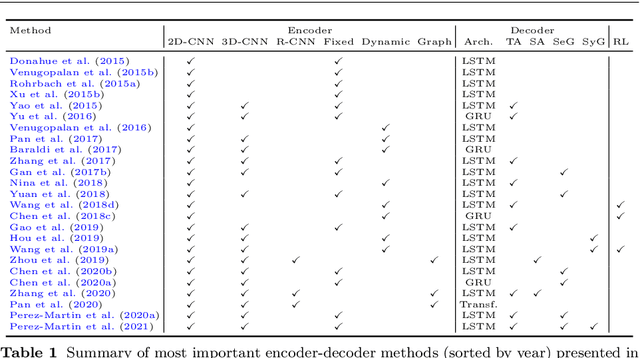
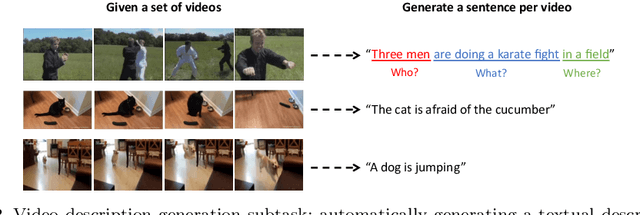
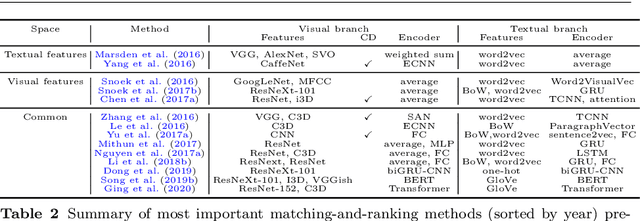
Research in the area of Vision and Language encompasses challenging topics that seek to connect visual and textual information. The video-to-text problem is one of these topics, in which the goal is to connect an input video with its textual description. This connection can be mainly made by retrieving the most significant descriptions from a corpus or generating a new one given a context video. These two ways represent essential tasks for Computer Vision and Natural Language Processing communities, called text retrieval from video task and video captioning/description task. These two tasks are substantially more complex than predicting or retrieving a single sentence from an image. The spatiotemporal information present in videos introduces diversity and complexity regarding the visual content and the structure of associated language descriptions. This review categorizes and describes the state-of-the-art techniques for the video-to-text problem. It covers the main video-to-text methods and the ways to evaluate their performance. We analyze how the most reported benchmark datasets have been created, showing their drawbacks and strengths for the problem requirements. We also show the impressive progress that researchers have made on each dataset, and we analyze why, despite this progress, the video-to-text conversion is still unsolved. State-of-the-art techniques are still a long way from achieving human-like performance in generating or retrieving video descriptions. We cover several significant challenges in the field and discuss future research directions.
A Convolutional Architecture for 3D Model Embedding
Mar 05, 2021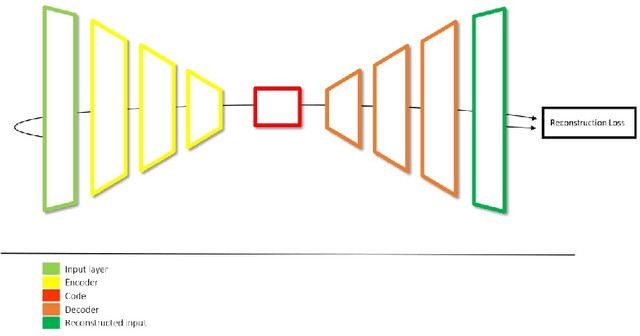
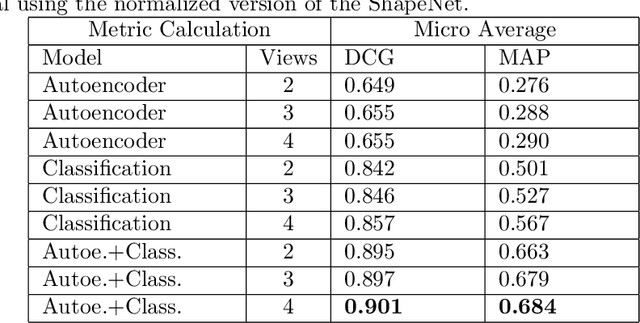
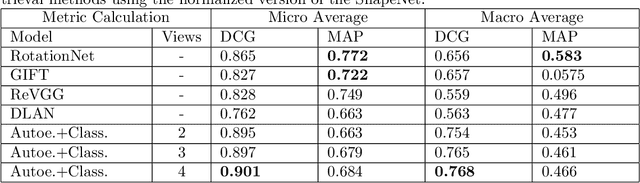
During the last years, many advances have been made in tasks like3D model retrieval, 3D model classification, and 3D model segmentation.The typical 3D representations such as point clouds, voxels, and poly-gon meshes are mostly suitable for rendering purposes, while their use forcognitive processes (retrieval, classification, segmentation) is limited dueto their high redundancy and complexity. We propose a deep learningarchitecture to handle 3D models as an input. We combine this architec-ture with other standard architectures like Convolutional Neural Networksand autoencoders for computing 3D model embeddings. Our goal is torepresent a 3D model as a vector with enough information to substitutethe 3D model for high-level tasks. Since this vector is a learned repre-sentation which tries to capture the relevant information of a 3D model,we show that the embedding representation conveys semantic informationthat helps to deal with the similarity assessment of 3D objects. Our ex-periments show the benefit of computing the embeddings of a 3D modeldata set and use them for effective 3D Model Retrieval.
Refinement of Predicted Missing Parts Enhance Point Cloud Completion
Oct 08, 2020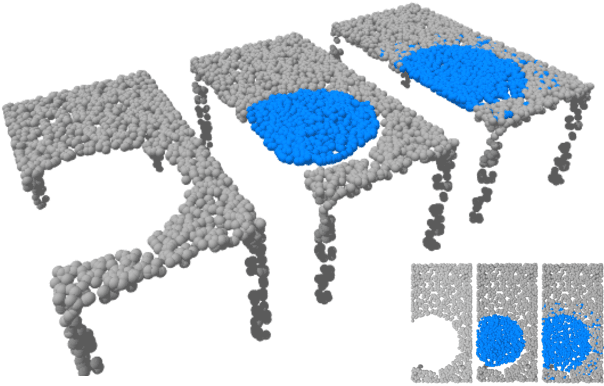
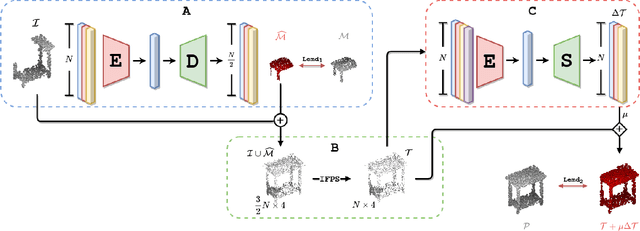


Point cloud completion is the task of predicting complete geometry from partial observations using a point set representation for a 3D shape. Previous approaches propose neural networks to directly estimate the whole point cloud through encoder-decoder models fed by the incomplete point set. By predicting the complete model, the current methods compute redundant information because the output also contains the known incomplete input geometry. This paper proposes an end-to-end neural network architecture that focuses on computing the missing geometry and merging the known input and the predicted point cloud. Our method is composed of two neural networks: the missing part prediction network and the merging-refinement network. The first module focuses on extracting information from the incomplete input to infer the missing geometry. The second module merges both point clouds and improves the distribution of the points. Our experiments on ShapeNet dataset show that our method outperforms the state-of-the-art methods in point cloud completion. The code of our methods and experiments is available in \url{https://github.com/ivansipiran/Refinement-Point-Cloud-Completion}.
3D Reconstruction of Incomplete Archaeological Objects Using a Generative Adversarial Network
Mar 10, 2018

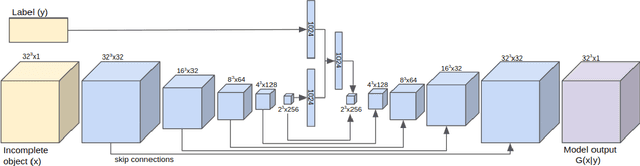
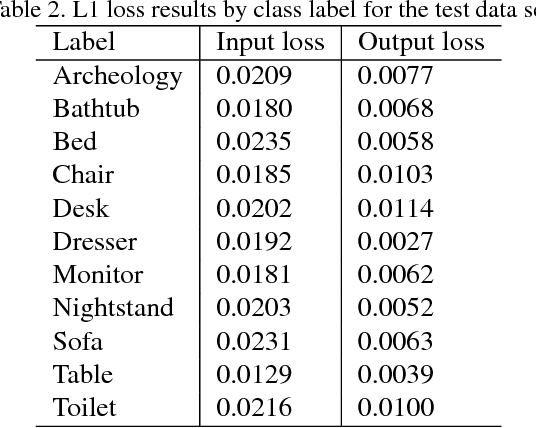
We introduce a data-driven approach to aid the repairing and conservation of archaeological objects: ORGAN, an object reconstruction generative adversarial network (GAN). By using an encoder-decoder 3D deep neural network on a GAN architecture, and combining two loss objectives: a completion loss and an Improved Wasserstein GAN loss, we can train a network to effectively predict the missing geometry of damaged objects. As archaeological objects can greatly differ between them, the network is conditioned on a variable, which can be a culture, a region or any metadata of the object. In our results, we show that our method can recover most of the information from damaged objects, even in cases where more than half of the voxels are missing, without producing many errors.