 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Supervision Scarcity in Chest X-ray Classification: Long-Tailed and Zero-Shot Learning
Feb 13, 2026Chest X-ray (CXR) classification in clinical practice is often limited by imperfect supervision, arising from (i) extreme long-tailed multi-label disease distributions and (ii) missing annotations for rare or previously unseen findings. The CXR-LT 2026 challenge addresses these issues on a PadChest-based benchmark with a 36-class label space split into 30 in-distribution classes for training and 6 out-of-distribution (OOD) classes for zero-shot evaluation. We present task-specific solutions tailored to the distinct supervision regimes. For Task 1 (long-tailed multi-label classification), we adopt an imbalance-aware multi-label learning strategy to improve recognition of tail classes while maintaining stable performance on frequent findings. For Task 2 (zero-shot OOD recognition), we propose a prediction approach that produces scores for unseen disease categories without using any supervised labels or examples from the OOD classes during training. Evaluated with macro-averaged mean Average Precision (mAP), our method achieves strong performance on both tasks, ranking first on the public leaderboard of the development phase. Code and pre-trained models are available at https://github.com/hieuphamha19/CXR_LT.
FUGC: Benchmarking Semi-Supervised Learning Methods for Cervical Segmentation
Jan 22, 2026Accurate segmentation of cervical structures in transvaginal ultrasound (TVS) is critical for assessing the risk of spontaneous preterm birth (PTB), yet the scarcity of labeled data limits the performance of supervised learning approaches. This paper introduces the Fetal Ultrasound Grand Challenge (FUGC), the first benchmark for semi-supervised learning in cervical segmentation, hosted at ISBI 2025. FUGC provides a dataset of 890 TVS images, including 500 training images, 90 validation images, and 300 test images. Methods were evaluated using the Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), and runtime (RT), with a weighted combination of 0.4/0.4/0.2. The challenge attracted 10 teams with 82 participants submitting innovative solutions. The best-performing methods for each individual metric achieved 90.26\% mDSC, 38.88 mHD, and 32.85 ms RT, respectively. FUGC establishes a standardized benchmark for cervical segmentation, demonstrates the efficacy of semi-supervised methods with limited labeled data, and provides a foundation for AI-assisted clinical PTB risk assessment.
VietMEAgent: Culturally-Aware Few-Shot Multimodal Explanation for Vietnamese Visual Question Answering
Nov 12, 2025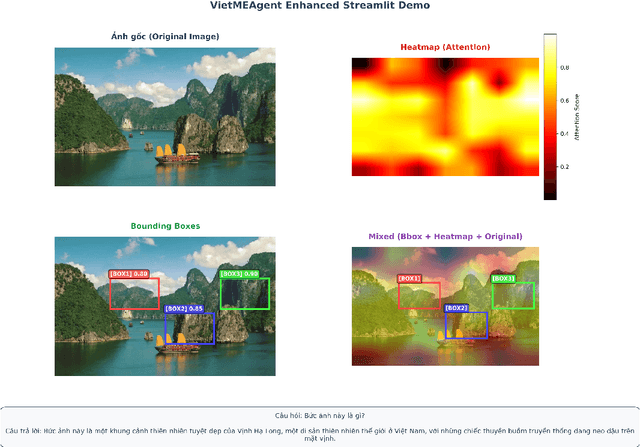
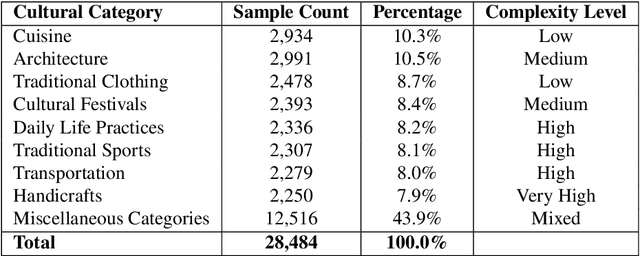
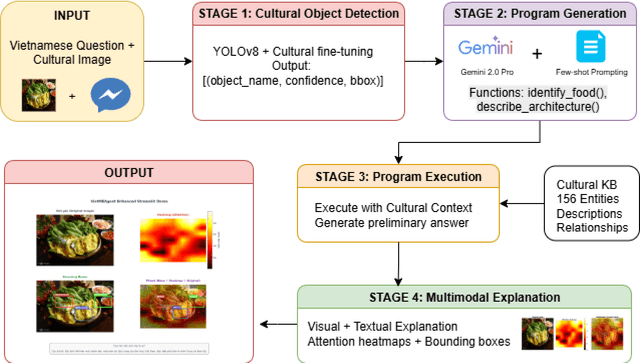
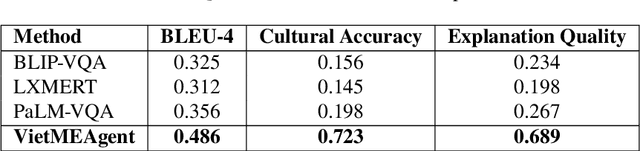
Contemporary Visual Question Answering (VQA) systems remain constrained when confronted with culturally specific content, largely because cultural knowledge is under-represented in training corpora and the reasoning process is not rendered interpretable to end users. This paper introduces VietMEAgent, a multimodal explainable framework engineered for Vietnamese cultural understanding. The method integrates a cultural object detection backbone with a structured program generation layer, yielding a pipeline in which answer prediction and explanation are tightly coupled. A curated knowledge base of Vietnamese cultural entities serves as an explicit source of background information, while a dual-modality explanation module combines attention-based visual evidence with structured, human-readable textual rationales. We further construct a Vietnamese Cultural VQA dataset sourced from public repositories and use it to demonstrate the practicality of programming-based methodologies for cultural AI. The resulting system provides transparent explanations that disclose both the computational rationale and the underlying cultural context, supporting education and cultural preservation with an emphasis on interpretability and cultural sensitivity.
MedXplain-VQA: Multi-Component Explainable Medical Visual Question Answering
Oct 26, 2025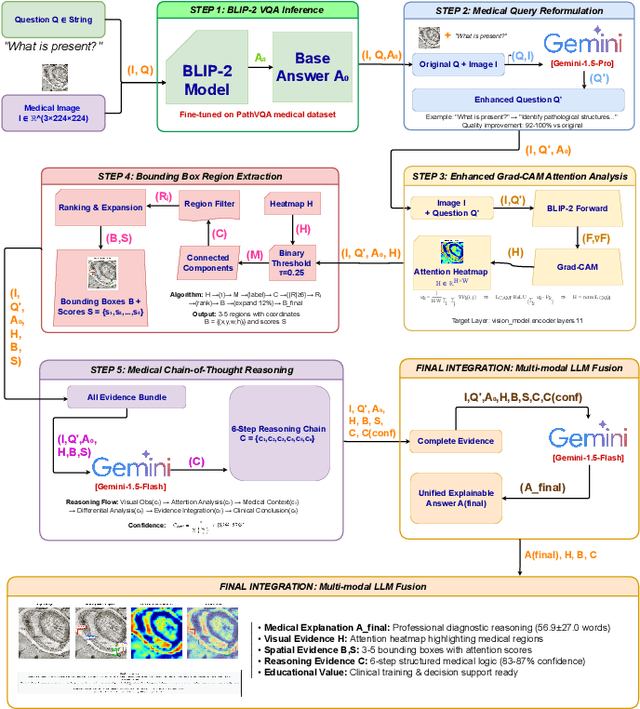
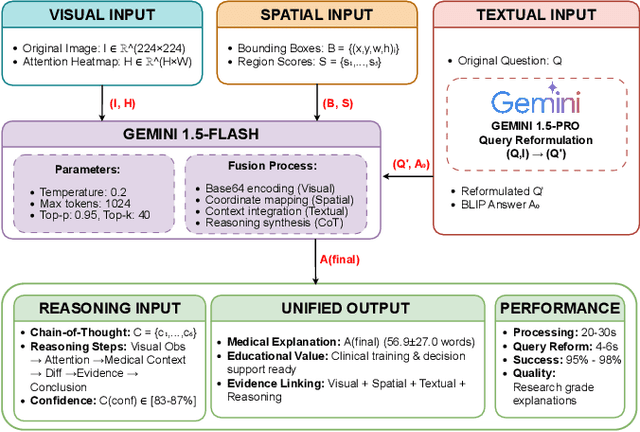
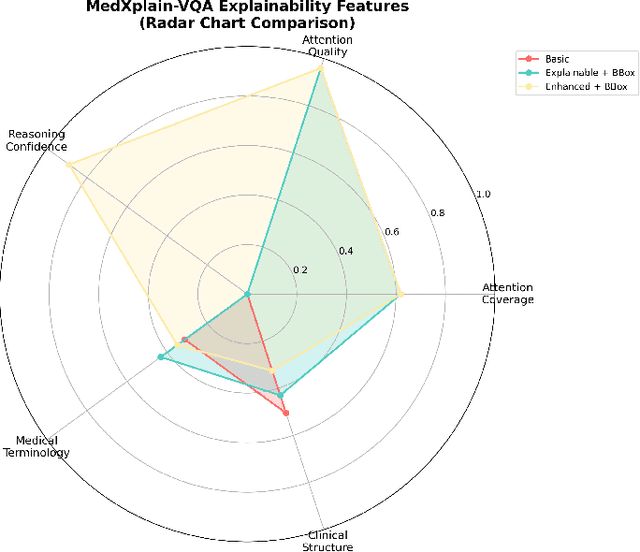
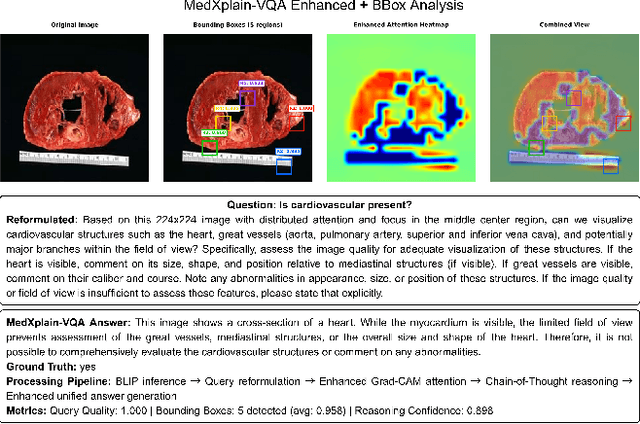
Explainability is critical for the clinical adoption of medical visual question answering (VQA) systems, as physicians require transparent reasoning to trust AI-generated diagnoses. We present MedXplain-VQA, a comprehensive framework integrating five explainable AI components to deliver interpretable medical image analysis. The framework leverages a fine-tuned BLIP-2 backbone, medical query reformulation, enhanced Grad-CAM attention, precise region extraction, and structured chain-of-thought reasoning via multi-modal language models. To evaluate the system, we introduce a medical-domain-specific framework replacing traditional NLP metrics with clinically relevant assessments, including terminology coverage, clinical structure quality, and attention region relevance. Experiments on 500 PathVQA histopathology samples demonstrate substantial improvements, with the enhanced system achieving a composite score of 0.683 compared to 0.378 for baseline methods, while maintaining high reasoning confidence (0.890). Our system identifies 3-5 diagnostically relevant regions per sample and generates structured explanations averaging 57 words with appropriate clinical terminology. Ablation studies reveal that query reformulation provides the most significant initial improvement, while chain-of-thought reasoning enables systematic diagnostic processes. These findings underscore the potential of MedXplain-VQA as a robust, explainable medical VQA system. Future work will focus on validation with medical experts and large-scale clinical datasets to ensure clinical readiness.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
SAM-EG: Segment Anything Model with Egde Guidance framework for efficient Polyp Segmentation
Jun 21, 2024



Polyp segmentation, a critical concern in medical imaging, has prompted numerous proposed methods aimed at enhancing the quality of segmented masks. While current state-of-the-art techniques produce impressive results, the size and computational cost of these models pose challenges for practical industry applications. Recently, the Segment Anything Model (SAM) has been proposed as a robust foundation model, showing promise for adaptation to medical image segmentation. Inspired by this concept, we propose SAM-EG, a framework that guides small segmentation models for polyp segmentation to address the computation cost challenge. Additionally, in this study, we introduce the Edge Guiding module, which integrates edge information into image features to assist the segmentation model in addressing boundary issues from current segmentation model in this task. Through extensive experiments, our small models showcase their efficacy by achieving competitive results with state-of-the-art methods, offering a promising approach to developing compact models with high accuracy for polyp segmentation and in the broader field of medical imaging.
Pose Guidance by Supervision: A Framework for Clothes-Changing Person Re-Identification
Dec 09, 2023Person Re-Identification (ReID) task seeks to enhance the tracking of multiple individuals by surveillance cameras. It provides additional support for multimodal tasks, including text-based person retrieval and human matching. One of the primary challenges in ReID is clothes-changing, which means the same person wears different clothes. While previous methods have achieved competitive results in maintaining clothing data consistency and handling clothing change data, they still tend to rely excessively on clothing information, thus limiting performance due to the dynamic nature of human appearances. To mitigate this challenge, we propose the Pose Guidance by Supervision (PGS) framework, an effective framework for learning pose guidance within the ReID task. This approach leverages pose knowledge and human part information from the pre-trained features to guide the network focus on clothes-irrelevant information, thus alleviating the clothes' influence on the deep learning model. Extensive experiments on five benchmark datasets demonstrate that our framework achieves competitive results compared with other state-of-the-art methods, which holds promise for developing robust models in the ReID task. Our code is available at https://github.com/huyquoctrinh/PGS.
M^2UNet: MetaFormer Multi-scale Upsampling Network for Polyp Segmentation
Jun 14, 2023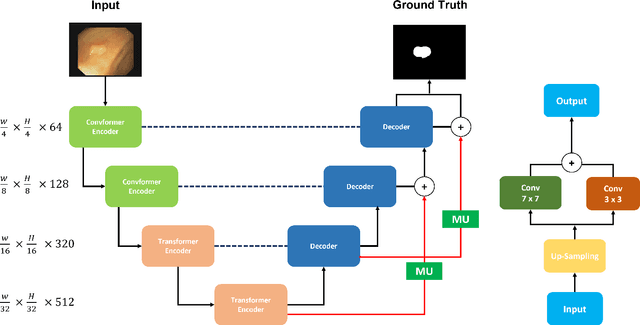
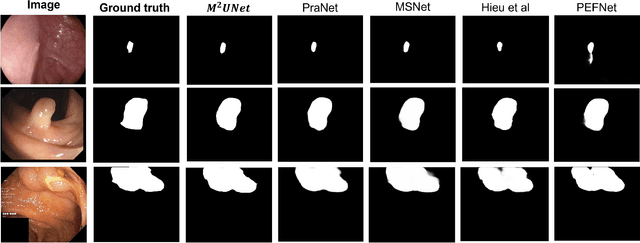
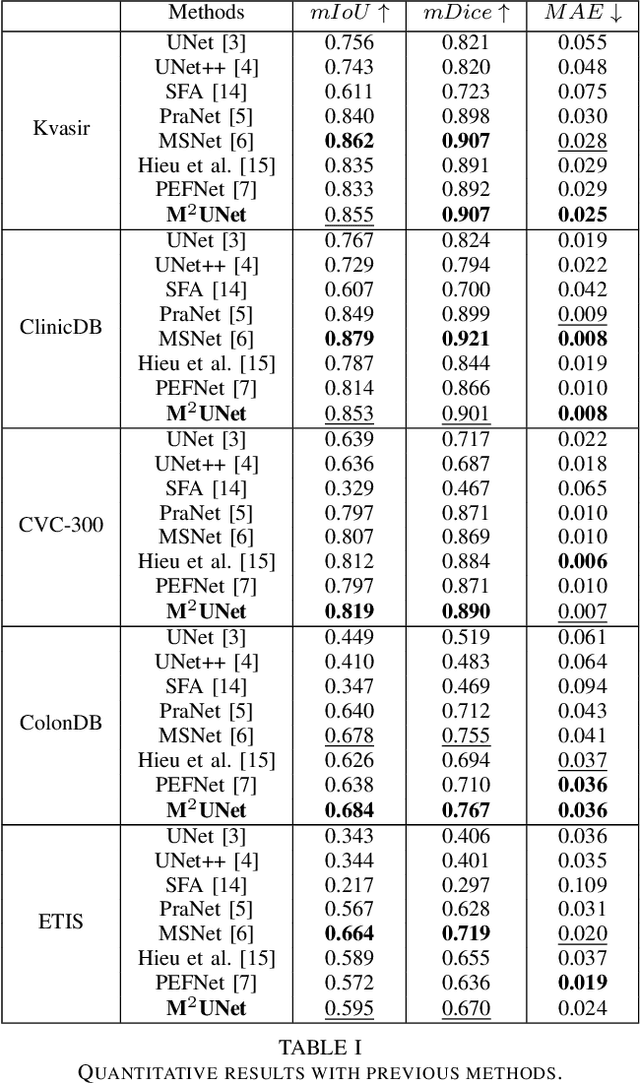
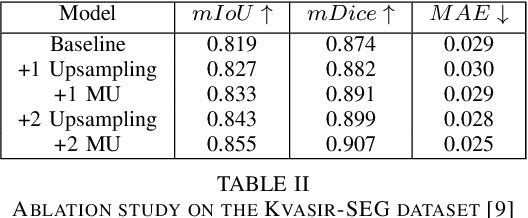
Polyp segmentation has recently garnered significant attention, and multiple methods have been formulated to achieve commendable outcomes. However, these techniques often confront difficulty when working with the complex polyp foreground and their surrounding regions because of the nature of convolution operation. Besides, most existing methods forget to exploit the potential information from multiple decoder stages. To address this challenge, we suggest combining MetaFormer, introduced as a baseline for integrating CNN and Transformer, with UNet framework and incorporating our Multi-scale Upsampling block (MU). This simple module makes it possible to combine multi-level information by exploring multiple receptive field paths of the shallow decoder stage and then adding with the higher stage to aggregate better feature representation, which is essential in medical image segmentation. Taken all together, we propose MetaFormer Multi-scale Upsampling Network (M$^2$UNet) for the polyp segmentation task. Extensive experiments on five benchmark datasets demonstrate that our method achieved competitive performance compared with several previous methods.
TextANIMAR: Text-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023



3D object retrieval is an important yet challenging task, which has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe that this task has the potential to drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from being fully solved. As such, we provide insights into potential areas for future research and improvements. We believe that we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.
SketchANIMAR: Sketch-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023The retrieval of 3D objects has gained significant importance in recent years due to its broad range of applications in computer vision, computer graphics, virtual reality, and augmented reality. However, the retrieval of 3D objects presents significant challenges due to the intricate nature of 3D models, which can vary in shape, size, and texture, and have numerous polygons and vertices. To this end, we introduce a novel SHREC challenge track that focuses on retrieving relevant 3D animal models from a dataset using sketch queries and expedites accessing 3D models through available sketches. Furthermore, a new dataset named ANIMAR was constructed in this study, comprising a collection of 711 unique 3D animal models and 140 corresponding sketch queries. Our contest requires participants to retrieve 3D models based on complex and detailed sketches. We receive satisfactory results from eight teams and 204 runs. Although further improvement is necessary, the proposed task has the potential to incentivize additional research in the domain of 3D object retrieval, potentially yielding benefits for a wide range of applications. We also provide insights into potential areas of future research, such as improving techniques for feature extraction and matching, and creating more diverse datasets to evaluate retrieval performance.