 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIDES: Virtual Interior Design via Natural Language and Visual Guidance
Aug 26, 2023



Interior design is crucial in creating aesthetically pleasing and functional indoor spaces. However, developing and editing interior design concepts requires significant time and expertise. We propose Virtual Interior DESign (VIDES) system in response to this challenge. Leveraging cutting-edge technology in generative AI, our system can assist users in generating and editing indoor scene concepts quickly, given user text description and visual guidance. Using both visual guidance and language as the conditional inputs significantly enhances the accuracy and coherence of the generated scenes, resulting in visually appealing designs. Through extensive experimentation, we demonstrate the effectiveness of VIDES in developing new indoor concepts, changing indoor styles, and replacing and removing interior objects. The system successfully captures the essence of users' descriptions while providing flexibility for customization. Consequently, this system can potentially reduce the entry barrier for indoor design, making it more accessible to users with limited technical skills and reducing the time required to create high-quality images. Individuals who have a background in design can now easily communicate their ideas visually and effectively present their design concepts. https://sites.google.com/view/ltnghia/research/VIDES
Multilingual Communication System with Deaf Individuals Utilizing Natural and Visual Languages
Dec 01, 2022According to the World Federation of the Deaf, more than two hundred sign languages exist. Therefore, it is challenging to understand deaf individuals, even proficient sign language users, resulting in a barrier between the deaf community and the rest of society. To bridge this language barrier, we propose a novel multilingual communication system, namely MUGCAT, to improve the communication efficiency of sign language users. By converting recognized specific hand gestures into expressive pictures, which is universal usage and language independence, our MUGCAT system significantly helps deaf people convey their thoughts. To overcome the limitation of sign language usage, which is mostly impossible to translate into complete sentences for ordinary people, we propose to reconstruct meaningful sentences from the incomplete translation of sign language. We also measure the semantic similarity of generated sentences with fragmented recognized hand gestures to keep the original meaning. Experimental results show that the proposed system can work in a real-time manner and synthesize exquisite stunning illustrations and meaningful sentences from a few hand gestures of sign language. This proves that our MUGCAT has promising potential in assisting deaf communication.
SHREC'22 Track: Sketch-Based 3D Shape Retrieval in the Wild
Jul 11, 2022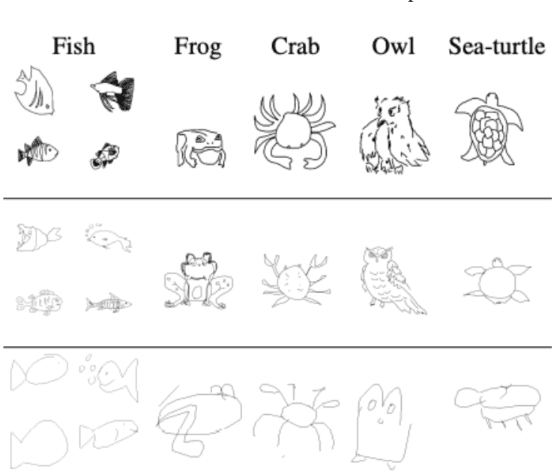
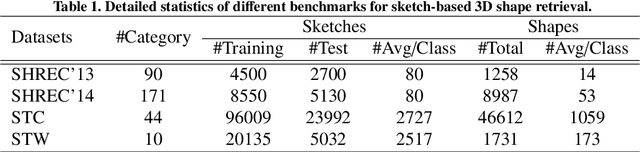
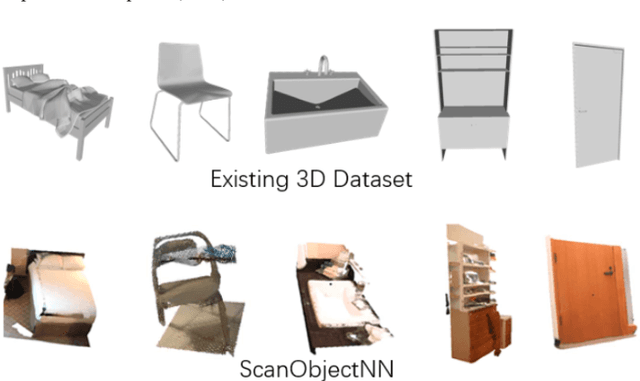
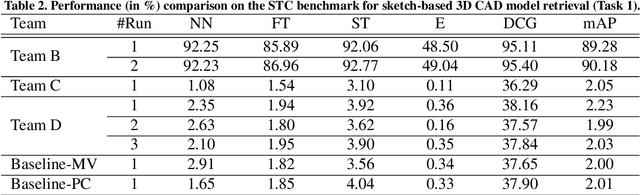
Sketch-based 3D shape retrieval (SBSR) is an important yet challenging task, which has drawn more and more attention in recent years. Existing approaches address the problem in a restricted setting, without appropriately simulating real application scenarios. To mimic the realistic setting, in this track, we adopt large-scale sketches drawn by amateurs of different levels of drawing skills, as well as a variety of 3D shapes including not only CAD models but also models scanned from real objects. We define two SBSR tasks and construct two benchmarks consisting of more than 46,000 CAD models, 1,700 realistic models, and 145,000 sketches in total. Four teams participated in this track and submitted 15 runs for the two tasks, evaluated by 7 commonly-adopted metrics. We hope that, the benchmarks, the comparative results, and the open-sourced evaluation code will foster future research in this direction among the 3D object retrieval community.