 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation
Nov 23, 2024



Developing an interpretable system for generating reports in chest X-ray (CXR) analysis is becoming increasingly crucial in Computer-aided Diagnosis (CAD) systems, enabling radiologists to comprehend the decisions made by these systems. Despite the growth of diverse datasets and methods focusing on report generation, there remains a notable gap in how closely these models' generated reports align with the interpretations of real radiologists. In this study, we tackle this challenge by initially introducing Fine-Grained CXR (FG-CXR) dataset, which provides fine-grained paired information between the captions generated by radiologists and the corresponding gaze attention heatmaps for each anatomy. Unlike existing datasets that include a raw sequence of gaze alongside a report, with significant misalignment between gaze location and report content, our FG-CXR dataset offers a more grained alignment between gaze attention and diagnosis transcript. Furthermore, our analysis reveals that simply applying black-box image captioning methods to generate reports cannot adequately explain which information in CXR is utilized and how long needs to attend to accurately generate reports. Consequently, we propose a novel explainable radiologist's attention generator network (Gen-XAI) that mimics the diagnosis process of radiologists, explicitly constraining its output to closely align with both radiologist's gaze attention and transcript. Finally, we perform extensive experiments to illustrate the effectiveness of our method. Our datasets and checkpoint is available at https://github.com/UARK-AICV/FG-CXR.
NeIn: Telling What You Don't Want
Sep 09, 2024



Negation is a fundamental linguistic concept used by humans to convey information that they do not desire. Despite this, there has been minimal research specifically focused on negation within vision-language tasks. This lack of research means that vision-language models (VLMs) may struggle to understand negation, implying that they struggle to provide accurate results. One barrier to achieving human-level intelligence is the lack of a standard collection by which research into negation can be evaluated. This paper presents the first large-scale dataset, Negative Instruction (NeIn), for studying negation within the vision-language domain. Our dataset comprises 530,694 quadruples, i.e., source image, original caption, negative sentence, and target image in total, including 495,694 queries for training and 35,000 queries for benchmarking across multiple vision-language tasks. Specifically, we automatically generate NeIn based on a large, existing vision-language dataset, MS-COCO, via two steps: generation and filtering. During the generation phase, we leverage two VLMs, BLIP and MagicBrush, to generate the target image and a negative clause that expresses the content of the source image. In the subsequent filtering phase, we apply BLIP to remove erroneous samples. Additionally, we introduce an evaluation protocol for negation understanding of image editing models. Extensive experiments using our dataset across multiple VLMs for instruction-based image editing tasks demonstrate that even recent state-of-the-art VLMs struggle to understand negative queries. The project page is: https://tanbuinhat.github.io/NeIn/
CattleFace-RGBT: RGB-T Cattle Facial Landmark Benchmark
Jun 05, 2024
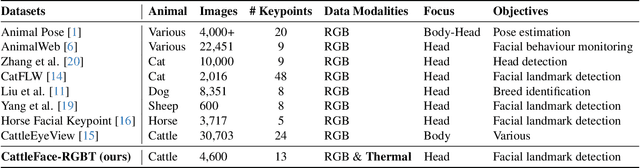

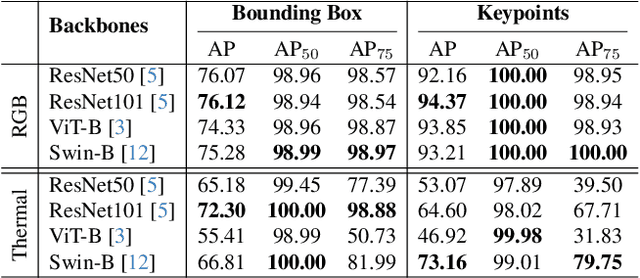
To address this challenge, we introduce CattleFace-RGBT, a RGB-T Cattle Facial Landmark dataset consisting of 2,300 RGB-T image pairs, a total of 4,600 images. Creating a landmark dataset is time-consuming, but AI-assisted annotation can help. However, applying AI to thermal images is challenging due to suboptimal results from direct thermal training and infeasible RGB-thermal alignment due to different camera views. Therefore, we opt to transfer models trained on RGB to thermal images and refine them using our AI-assisted annotation tool following a semi-automatic annotation approach. Accurately localizing facial key points on both RGB and thermal images enables us to not only discern the cattle's respiratory signs but also measure temperatures to assess the animal's thermal state. To the best of our knowledge, this is the first dataset for the cattle facial landmark on RGB-T images. We conduct benchmarking of the CattleFace-RGBT dataset across various backbone architectures, with the objective of establishing baselines for future research, analysis, and comparison. The dataset and models are at https://github.com/UARK-AICV/CattleFace-RGBT-benchmark
TSRNet: Simple Framework for Real-time ECG Anomaly Detection with Multimodal Time and Spectrogram Restoration Network
Dec 15, 2023

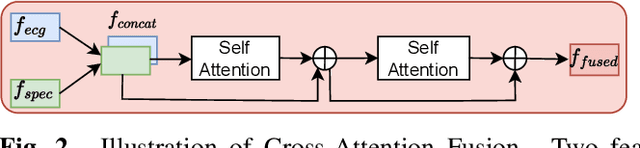
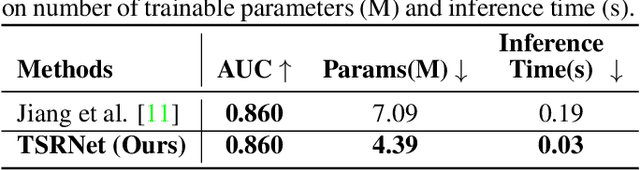
The electrocardiogram (ECG) is a valuable signal used to assess various aspects of heart health, such as heart rate and rhythm. It plays a crucial role in identifying cardiac conditions and detecting anomalies in ECG data. However, distinguishing between normal and abnormal ECG signals can be a challenging task. In this paper, we propose an approach that leverages anomaly detection to identify unhealthy conditions using solely normal ECG data for training. Furthermore, to enhance the information available and build a robust system, we suggest considering both the time series and time-frequency domain aspects of the ECG signal. As a result, we introduce a specialized network called the Multimodal Time and Spectrogram Restoration Network (TSRNet) designed specifically for detecting anomalies in ECG signals. TSRNet falls into the category of restoration-based anomaly detection and draws inspiration from both the time series and spectrogram domains. By extracting representations from both domains, TSRNet effectively captures the comprehensive characteristics of the ECG signal. This approach enables the network to learn robust representations with superior discrimination abilities, allowing it to distinguish between normal and abnormal ECG patterns more effectively. Furthermore, we introduce a novel inference method, termed Peak-based Error, that specifically focuses on ECG peaks, a critical component in detecting abnormalities. The experimental result on the large-scale dataset PTB-XL has demonstrated the effectiveness of our approach in ECG anomaly detection, while also prioritizing efficiency by minimizing the number of trainable parameters. Our code is available at https://github.com/UARK-AICV/TSRNet.
Pose Guidance by Supervision: A Framework for Clothes-Changing Person Re-Identification
Dec 09, 2023Person Re-Identification (ReID) task seeks to enhance the tracking of multiple individuals by surveillance cameras. It provides additional support for multimodal tasks, including text-based person retrieval and human matching. One of the primary challenges in ReID is clothes-changing, which means the same person wears different clothes. While previous methods have achieved competitive results in maintaining clothing data consistency and handling clothing change data, they still tend to rely excessively on clothing information, thus limiting performance due to the dynamic nature of human appearances. To mitigate this challenge, we propose the Pose Guidance by Supervision (PGS) framework, an effective framework for learning pose guidance within the ReID task. This approach leverages pose knowledge and human part information from the pre-trained features to guide the network focus on clothes-irrelevant information, thus alleviating the clothes' influence on the deep learning model. Extensive experiments on five benchmark datasets demonstrate that our framework achieves competitive results compared with other state-of-the-art methods, which holds promise for developing robust models in the ReID task. Our code is available at https://github.com/huyquoctrinh/PGS.
SAM3D: Segment Anything Model in Volumetric Medical Images
Sep 07, 2023



Image segmentation is a critical task in medical image analysis, providing valuable information that helps to make an accurate diagnosis. In recent years, deep learning-based automatic image segmentation methods have achieved outstanding results in medical images. In this paper, inspired by the Segment Anything Model (SAM), a foundation model that has received much attention for its impressive accuracy and powerful generalization ability in 2D still image segmentation, we propose a SAM3D that targets at 3D volumetric medical images and utilizes the pre-trained features from the SAM encoder to capture meaningful representations of input images. Different from other existing SAM-based volumetric segmentation methods that perform the segmentation by dividing the volume into a set of 2D slices, our model takes the whole 3D volume image as input and processes it simply and effectively that avoids training a significant number of parameters. Extensive experiments are conducted on multiple medical image datasets to demonstrate that our network attains competitive results compared with other state-of-the-art methods in 3D medical segmentation tasks while being significantly efficient in terms of parameters.
MEGANet: Multi-Scale Edge-Guided Attention Network for Weak Boundary Polyp Segmentation
Sep 06, 2023



Efficient polyp segmentation in healthcare plays a critical role in enabling early diagnosis of colorectal cancer. However, the segmentation of polyps presents numerous challenges, including the intricate distribution of backgrounds, variations in polyp sizes and shapes, and indistinct boundaries. Defining the boundary between the foreground (i.e. polyp itself) and the background (surrounding tissue) is difficult. To mitigate these challenges, we propose Multi-Scale Edge-Guided Attention Network (MEGANet) tailored specifically for polyp segmentation within colonoscopy images. This network draws inspiration from the fusion of a classical edge detection technique with an attention mechanism. By combining these techniques, MEGANet effectively preserves high-frequency information, notably edges and boundaries, which tend to erode as neural networks deepen. MEGANet is designed as an end-to-end framework, encompassing three key modules: an encoder, which is responsible for capturing and abstracting the features from the input image, a decoder, which focuses on salient features, and the Edge-Guided Attention module (EGA) that employs the Laplacian Operator to accentuate polyp boundaries. Extensive experiments, both qualitative and quantitative, on five benchmark datasets, demonstrate that our EGANet outperforms other existing SOTA methods under six evaluation metrics. Our code is available at \url{https://github.com/DinhHieuHoang/MEGANet}
M^2UNet: MetaFormer Multi-scale Upsampling Network for Polyp Segmentation
Jun 14, 2023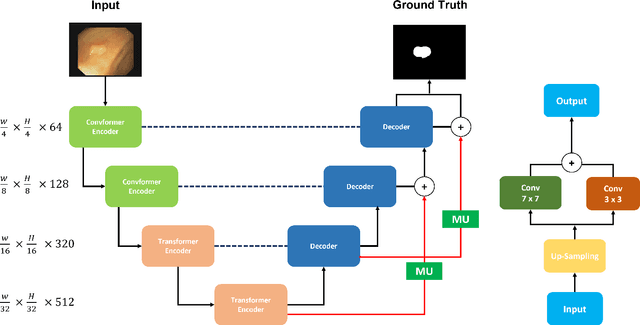
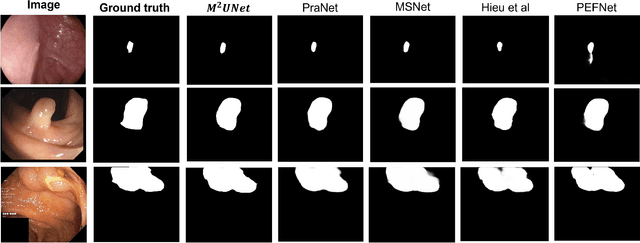
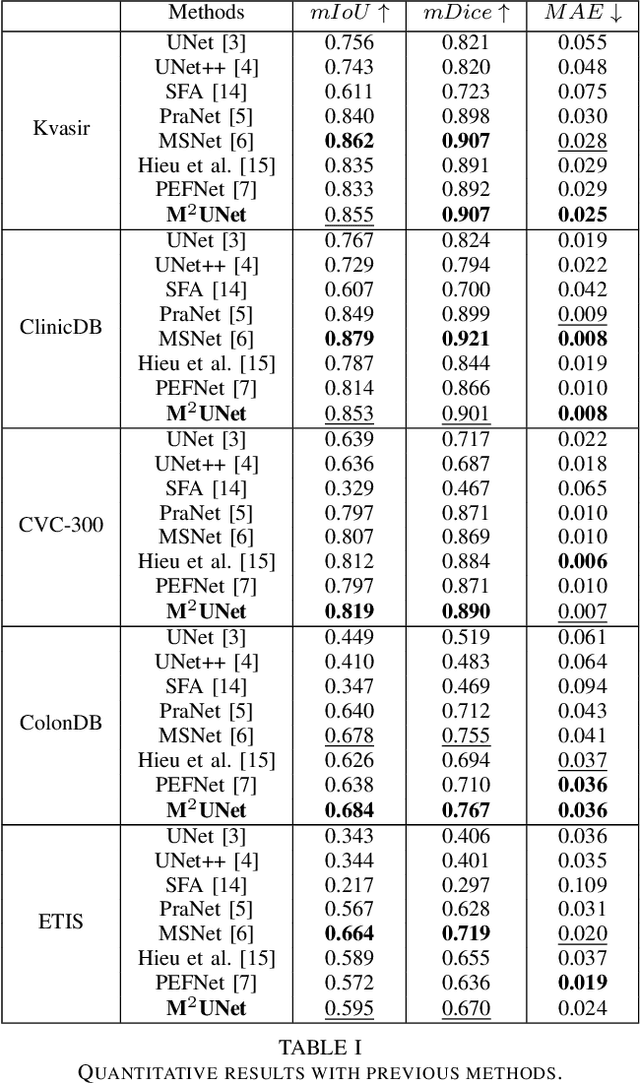
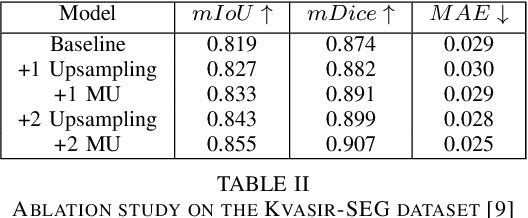
Polyp segmentation has recently garnered significant attention, and multiple methods have been formulated to achieve commendable outcomes. However, these techniques often confront difficulty when working with the complex polyp foreground and their surrounding regions because of the nature of convolution operation. Besides, most existing methods forget to exploit the potential information from multiple decoder stages. To address this challenge, we suggest combining MetaFormer, introduced as a baseline for integrating CNN and Transformer, with UNet framework and incorporating our Multi-scale Upsampling block (MU). This simple module makes it possible to combine multi-level information by exploring multiple receptive field paths of the shallow decoder stage and then adding with the higher stage to aggregate better feature representation, which is essential in medical image segmentation. Taken all together, we propose MetaFormer Multi-scale Upsampling Network (M$^2$UNet) for the polyp segmentation task. Extensive experiments on five benchmark datasets demonstrate that our method achieved competitive performance compared with several previous methods.
Multi Kernel Positional Embedding ConvNeXt for Polyp Segmentation
Jan 17, 2023



Medical image segmentation is the technique that helps doctor view and has a precise diagnosis, particularly in Colorectal Cancer. Specifically, with the increase in cases, the diagnosis and identification need to be faster and more accurate for many patients; in endoscopic images, the segmentation task has been vital to helping the doctor identify the position of the polyps or the ache in the system correctly. As a result, many efforts have been made to apply deep learning to automate polyp segmentation, mostly to ameliorate the U-shape structure. However, the simple skip connection scheme in UNet leads to deficient context information and the semantic gap between feature maps from the encoder and decoder. To deal with this problem, we propose a novel framework composed of ConvNeXt backbone and Multi Kernel Positional Embedding block. Thanks to the suggested module, our method can attain better accuracy and generalization in the polyps segmentation task. Extensive experiments show that our model achieves the Dice coefficient of 0.8818 and the IOU score of 0.8163 on the Kvasir-SEG dataset. Furthermore, on various datasets, we make competitive achievement results with other previous state-of-the-art methods.