 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVG: Gradient-Guided Aggregation for Enhanced Federated Learning
Feb 24, 2026Federated Learning (FL) enables collaborative model training across multiple clients without sharing their private data. However, data heterogeneity across clients leads to client drift, which degrades the overall generalization performance of the model. This effect is further compounded by overemphasis on poorly performing clients. To address this problem, we propose FedVG, a novel gradient-based federated aggregation framework that leverages a global validation set to guide the optimization process. Such a global validation set can be established using readily available public datasets, ensuring accessibility and consistency across clients without compromising privacy. In contrast to conventional approaches that prioritize client dataset volume, FedVG assesses the generalization ability of client models by measuring the magnitude of validation gradients across layers. Specifically, we compute layerwise gradient norms to derive a client-specific score that reflects how much each client needs to adjust for improved generalization on the global validation set, thereby enabling more informed and adaptive federated aggregation. Extensive experiments on both natural and medical image benchmarking datasets, across diverse model architectures, demonstrate that FedVG consistently improves performance, particularly in highly heterogeneous settings. Moreover, FedVG is modular and can be seamlessly integrated with various state-of-the-art FL algorithms, often further improving their results. Our code is available at https://github.com/alinadevkota/FedVG.
Federated Foundation Model for GI Endoscopy Images
May 30, 2025



Gastrointestinal (GI) endoscopy is essential in identifying GI tract abnormalities in order to detect diseases in their early stages and improve patient outcomes. Although deep learning has shown success in supporting GI diagnostics and decision-making, these models require curated datasets with labels that are expensive to acquire. Foundation models offer a promising solution by learning general-purpose representations, which can be finetuned for specific tasks, overcoming data scarcity. Developing foundation models for medical imaging holds significant potential, but the sensitive and protected nature of medical data presents unique challenges. Foundation model training typically requires extensive datasets, and while hospitals generate large volumes of data, privacy restrictions prevent direct data sharing, making foundation model training infeasible in most scenarios. In this work, we propose a FL framework for training foundation models for gastroendoscopy imaging, enabling data to remain within local hospital environments while contributing to a shared model. We explore several established FL algorithms, assessing their suitability for training foundation models without relying on task-specific labels, conducting experiments in both homogeneous and heterogeneous settings. We evaluate the trained foundation model on three critical downstream tasks--classification, detection, and segmentation--and demonstrate that it achieves improved performance across all tasks, highlighting the effectiveness of our approach in a federated, privacy-preserving setting.
FG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation
Nov 23, 2024



Developing an interpretable system for generating reports in chest X-ray (CXR) analysis is becoming increasingly crucial in Computer-aided Diagnosis (CAD) systems, enabling radiologists to comprehend the decisions made by these systems. Despite the growth of diverse datasets and methods focusing on report generation, there remains a notable gap in how closely these models' generated reports align with the interpretations of real radiologists. In this study, we tackle this challenge by initially introducing Fine-Grained CXR (FG-CXR) dataset, which provides fine-grained paired information between the captions generated by radiologists and the corresponding gaze attention heatmaps for each anatomy. Unlike existing datasets that include a raw sequence of gaze alongside a report, with significant misalignment between gaze location and report content, our FG-CXR dataset offers a more grained alignment between gaze attention and diagnosis transcript. Furthermore, our analysis reveals that simply applying black-box image captioning methods to generate reports cannot adequately explain which information in CXR is utilized and how long needs to attend to accurately generate reports. Consequently, we propose a novel explainable radiologist's attention generator network (Gen-XAI) that mimics the diagnosis process of radiologists, explicitly constraining its output to closely align with both radiologist's gaze attention and transcript. Finally, we perform extensive experiments to illustrate the effectiveness of our method. Our datasets and checkpoint is available at https://github.com/UARK-AICV/FG-CXR.
TSRNet: Simple Framework for Real-time ECG Anomaly Detection with Multimodal Time and Spectrogram Restoration Network
Dec 15, 2023

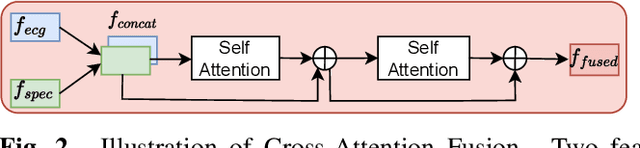
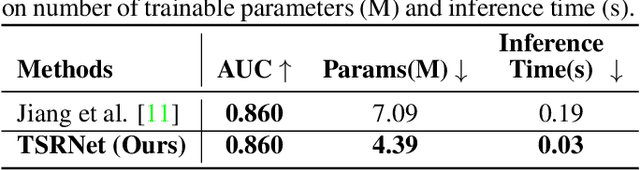
The electrocardiogram (ECG) is a valuable signal used to assess various aspects of heart health, such as heart rate and rhythm. It plays a crucial role in identifying cardiac conditions and detecting anomalies in ECG data. However, distinguishing between normal and abnormal ECG signals can be a challenging task. In this paper, we propose an approach that leverages anomaly detection to identify unhealthy conditions using solely normal ECG data for training. Furthermore, to enhance the information available and build a robust system, we suggest considering both the time series and time-frequency domain aspects of the ECG signal. As a result, we introduce a specialized network called the Multimodal Time and Spectrogram Restoration Network (TSRNet) designed specifically for detecting anomalies in ECG signals. TSRNet falls into the category of restoration-based anomaly detection and draws inspiration from both the time series and spectrogram domains. By extracting representations from both domains, TSRNet effectively captures the comprehensive characteristics of the ECG signal. This approach enables the network to learn robust representations with superior discrimination abilities, allowing it to distinguish between normal and abnormal ECG patterns more effectively. Furthermore, we introduce a novel inference method, termed Peak-based Error, that specifically focuses on ECG peaks, a critical component in detecting abnormalities. The experimental result on the large-scale dataset PTB-XL has demonstrated the effectiveness of our approach in ECG anomaly detection, while also prioritizing efficiency by minimizing the number of trainable parameters. Our code is available at https://github.com/UARK-AICV/TSRNet.
ZEETAD: Adapting Pretrained Vision-Language Model for Zero-Shot End-to-End Temporal Action Detection
Nov 04, 2023



Temporal action detection (TAD) involves the localization and classification of action instances within untrimmed videos. While standard TAD follows fully supervised learning with closed-set setting on large training data, recent zero-shot TAD methods showcase the promising open-set setting by leveraging large-scale contrastive visual-language (ViL) pretrained models. However, existing zero-shot TAD methods have limitations on how to properly construct the strong relationship between two interdependent tasks of localization and classification and adapt ViL model to video understanding. In this work, we present ZEETAD, featuring two modules: dual-localization and zero-shot proposal classification. The former is a Transformer-based module that detects action events while selectively collecting crucial semantic embeddings for later recognition. The latter one, CLIP-based module, generates semantic embeddings from text and frame inputs for each temporal unit. Additionally, we enhance discriminative capability on unseen classes by minimally updating the frozen CLIP encoder with lightweight adapters. Extensive experiments on THUMOS14 and ActivityNet-1.3 datasets demonstrate our approach's superior performance in zero-shot TAD and effective knowledge transfer from ViL models to unseen action categories.
Distributionally Robust Cross Subject EEG Decoding
Aug 19, 2023



Recently, deep learning has shown to be effective for Electroencephalography (EEG) decoding tasks. Yet, its performance can be negatively influenced by two key factors: 1) the high variance and different types of corruption that are inherent in the signal, 2) the EEG datasets are usually relatively small given the acquisition cost, annotation cost and amount of effort needed. Data augmentation approaches for alleviation of this problem have been empirically studied, with augmentation operations on spatial domain, time domain or frequency domain handcrafted based on expertise of domain knowledge. In this work, we propose a principled approach to perform dynamic evolution on the data for improvement of decoding robustness. The approach is based on distributionally robust optimization and achieves robustness by optimizing on a family of evolved data distributions instead of the single training data distribution. We derived a general data evolution framework based on Wasserstein gradient flow (WGF) and provides two different forms of evolution within the framework. Intuitively, the evolution process helps the EEG decoder to learn more robust and diverse features. It is worth mentioning that the proposed approach can be readily integrated with other data augmentation approaches for further improvements. We performed extensive experiments on the proposed approach and tested its performance on different types of corrupted EEG signals. The model significantly outperforms competitive baselines on challenging decoding scenarios.
Z-GMOT: Zero-shot Generic Multiple Object Tracking
May 28, 2023Despite the significant progress made in recent years, Multi-Object Tracking (MOT) approaches still suffer from several limitations, including their reliance on prior knowledge of tracking targets, which necessitates the costly annotation of large labeled datasets. As a result, existing MOT methods are limited to a small set of predefined categories, and they struggle with unseen objects in the real world. To address these issues, Generic Multiple Object Tracking (GMOT) has been proposed, which requires less prior information about the targets. However, all existing GMOT approaches follow a one-shot paradigm, relying mainly on the initial bounding box and thus struggling to handle variants e.g., viewpoint, lighting, occlusion, scale, and etc. In this paper, we introduce a novel approach to address the limitations of existing MOT and GMOT methods. Specifically, we propose a zero-shot GMOT (Z-GMOT) algorithm that can track never-seen object categories with zero training examples, without the need for predefined categories or an initial bounding box. To achieve this, we propose iGLIP, an improved version of Grounded language-image pretraining (GLIP), which can detect unseen objects while minimizing false positives. We evaluate our Z-GMOT thoroughly on the GMOT-40 dataset, AnimalTrack testset, DanceTrack testset. The results of these evaluations demonstrate a significant improvement over existing methods. For instance, on the GMOT-40 dataset, the Z-GMOT outperforms one-shot GMOT with OC-SORT by 27.79 points HOTA and 44.37 points MOTA. On the AnimalTrack dataset, it surpasses fully-supervised methods with DeepSORT by 12.55 points HOTA and 8.97 points MOTA. To facilitate further research, we will make our code and models publicly available upon acceptance of this paper.
Learning Representations for Masked Facial Recovery
Dec 28, 2022The pandemic of these very recent years has led to a dramatic increase in people wearing protective masks in public venues. This poses obvious challenges to the pervasive use of face recognition technology that now is suffering a decline in performance. One way to address the problem is to revert to face recovery methods as a preprocessing step. Current approaches to face reconstruction and manipulation leverage the ability to model the face manifold, but tend to be generic. We introduce a method that is specific for the recovery of the face image from an image of the same individual wearing a mask. We do so by designing a specialized GAN inversion method, based on an appropriate set of losses for learning an unmasking encoder. With extensive experiments, we show that the approach is effective at unmasking face images. In addition, we also show that the identity information is preserved sufficiently well to improve face verification performance based on several face recognition benchmark datasets.
Multimodality Multi-Lead ECG Arrhythmia Classification using Self-Supervised Learning
Sep 30, 2022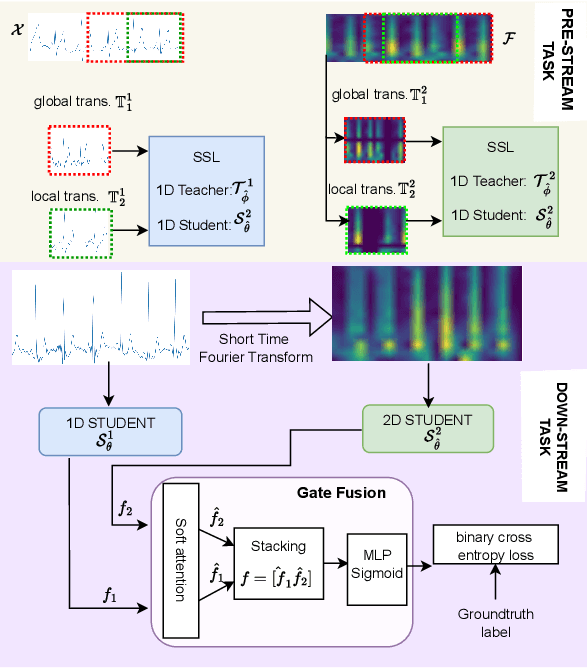
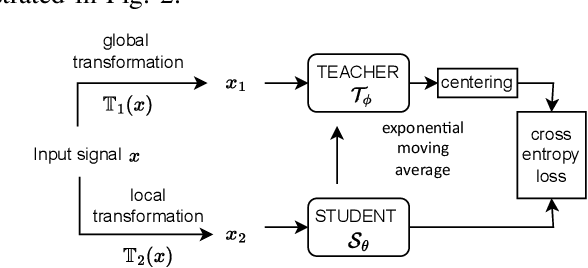
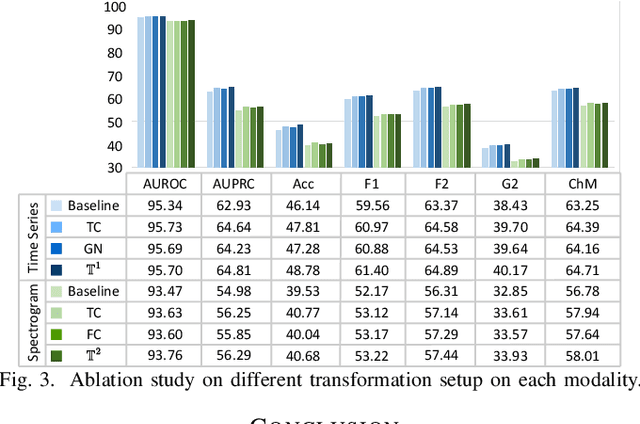
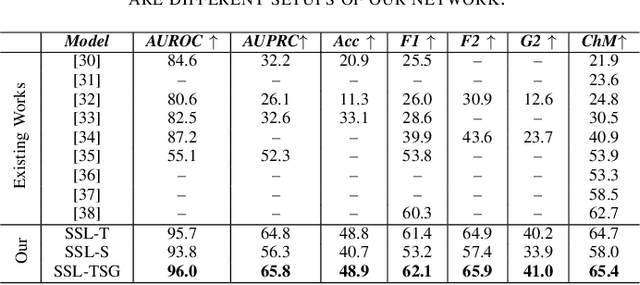
Electrocardiogram (ECG) signal is one of the most effective sources of information mainly employed for the diagnosis and prediction of cardiovascular diseases (CVDs) connected with the abnormalities in heart rhythm. Clearly, single modality ECG (i.e. time series) cannot convey its complete characteristics, thus, exploiting both time and time-frequency modalities in the form of time-series data and spectrogram is needed. Leveraging the cutting-edge self-supervised learning (SSL) technique on unlabeled data, we propose SSL-based multimodality ECG classification. Our proposed network follows SSL learning paradigm and consists of two modules corresponding to pre-stream task, and down-stream task, respectively. In the SSL-pre-stream task, we utilize self-knowledge distillation (KD) techniques with no labeled data, on various transformations and in both time and frequency domains. In the down-stream task, which is trained on labeled data, we propose a gate fusion mechanism to fuse information from multimodality.To evaluate the effectiveness of our approach, ten-fold cross validation on the 12-lead PhysioNet 2020 dataset has been conducted.
An Information-Theoretic Framework for Identifying Age-Related Genes Using Human Dermal Fibroblast Transcriptome Data
Nov 04, 2021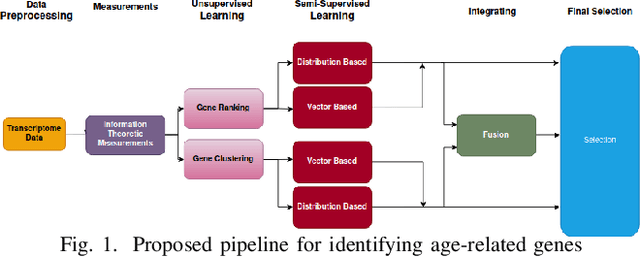
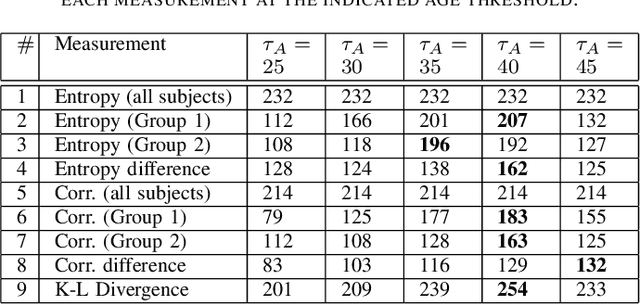
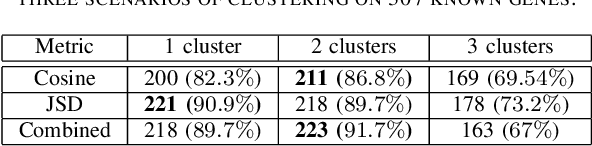

Investigation of age-related genes is of great importance for multiple purposes, for instance, improving our understanding of the mechanism of ageing, increasing life expectancy, age prediction, and other healthcare applications. In his work, starting with a set of 27,142 genes, we develop an information-theoretic framework for identifying genes that are associated with aging by applying unsupervised and semi-supervised learning techniques on human dermal fibroblast gene expression data. First, we use unsupervised learning and apply information-theoretic measures to identify key features for effective representation of gene expression values in the transcriptome data. Using the identified features, we perform clustering on the data. Finally, we apply semi-supervised learning on the clusters using different distance measures to identify novel genes that are potentially associated with aging. Performance assessment for both unsupervised and semi-supervised methods show the effectiveness of the framework.