 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsTALL: Context-aware Instructional Task Assistance with Multi-modal Large Language Models
Jan 21, 2025



The improved competence of generative models can help building multi-modal virtual assistants that leverage modalities beyond language. By observing humans performing multi-step tasks, one can build assistants that have situational awareness of actions and tasks being performed, enabling them to cater assistance based on this understanding. In this paper, we develop a Context-aware Instructional Task Assistant with Multi-modal Large Language Models (InsTALL) that leverages an online visual stream (e.g. a user's screen share or video recording) and responds in real-time to user queries related to the task at hand. To enable useful assistance, InsTALL 1) trains a multi-modal model on task videos and paired textual data, and 2) automatically extracts task graph from video data and leverages it at training and inference time. We show InsTALL achieves state-of-the-art performance across proposed sub-tasks considered for multimodal activity understanding -- task recognition (TR), action recognition (AR), next action prediction (AP), and plan prediction (PP) -- and outperforms existing baselines on two novel sub-tasks related to automatic error identification.
HyperGLM: HyperGraph for Video Scene Graph Generation and Anticipation
Nov 27, 2024Multimodal LLMs have advanced vision-language tasks but still struggle with understanding video scenes. To bridge this gap, Video Scene Graph Generation (VidSGG) has emerged to capture multi-object relationships across video frames. However, prior methods rely on pairwise connections, limiting their ability to handle complex multi-object interactions and reasoning. To this end, we propose Multimodal LLMs on a Scene HyperGraph (HyperGLM), promoting reasoning about multi-way interactions and higher-order relationships. Our approach uniquely integrates entity scene graphs, which capture spatial relationships between objects, with a procedural graph that models their causal transitions, forming a unified HyperGraph. Significantly, HyperGLM enables reasoning by injecting this unified HyperGraph into LLMs. Additionally, we introduce a new Video Scene Graph Reasoning (VSGR) dataset featuring 1.9M frames from third-person, egocentric, and drone views and supports five tasks: Scene Graph Generation, Scene Graph Anticipation, Video Question Answering, Video Captioning, and Relation Reasoning. Empirically, HyperGLM consistently outperforms state-of-the-art methods across five tasks, effectively modeling and reasoning complex relationships in diverse video scenes.
DINTR: Tracking via Diffusion-based Interpolation
Oct 14, 2024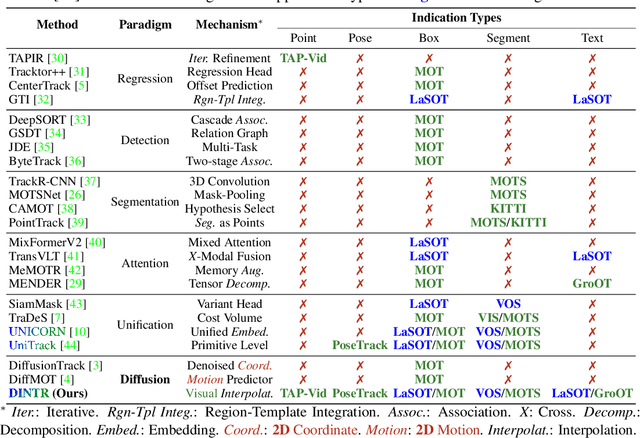
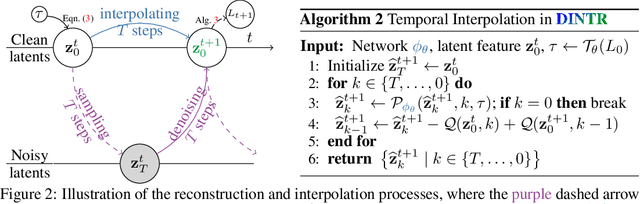


Object tracking is a fundamental task in computer vision, requiring the localization of objects of interest across video frames. Diffusion models have shown remarkable capabilities in visual generation, making them well-suited for addressing several requirements of the tracking problem. This work proposes a novel diffusion-based methodology to formulate the tracking task. Firstly, their conditional process allows for injecting indications of the target object into the generation process. Secondly, diffusion mechanics can be developed to inherently model temporal correspondences, enabling the reconstruction of actual frames in video. However, existing diffusion models rely on extensive and unnecessary mapping to a Gaussian noise domain, which can be replaced by a more efficient and stable interpolation process. Our proposed interpolation mechanism draws inspiration from classic image-processing techniques, offering a more interpretable, stable, and faster approach tailored specifically for the object tracking task. By leveraging the strengths of diffusion models while circumventing their limitations, our Diffusion-based INterpolation TrackeR (DINTR) presents a promising new paradigm and achieves a superior multiplicity on seven benchmarks across five indicator representations.
CYCLO: Cyclic Graph Transformer Approach to Multi-Object Relationship Modeling in Aerial Videos
Jun 03, 2024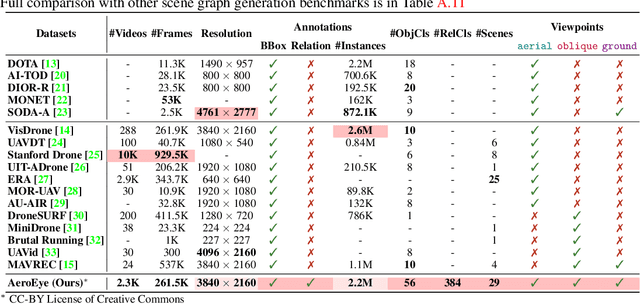
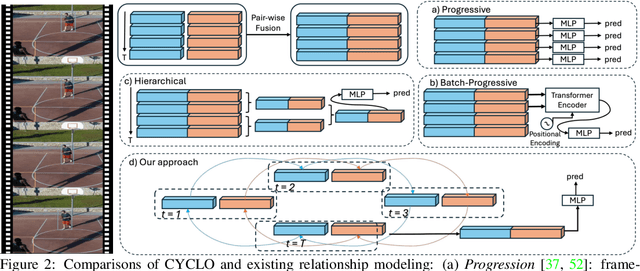
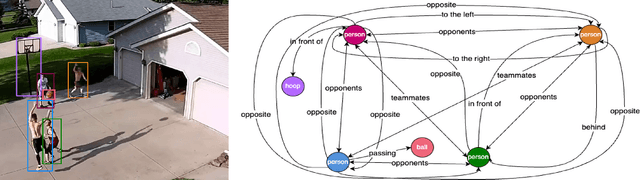

Video scene graph generation (VidSGG) has emerged as a transformative approach to capturing and interpreting the intricate relationships among objects and their temporal dynamics in video sequences. In this paper, we introduce the new AeroEye dataset that focuses on multi-object relationship modeling in aerial videos. Our AeroEye dataset features various drone scenes and includes a visually comprehensive and precise collection of predicates that capture the intricate relationships and spatial arrangements among objects. To this end, we propose the novel Cyclic Graph Transformer (CYCLO) approach that allows the model to capture both direct and long-range temporal dependencies by continuously updating the history of interactions in a circular manner. The proposed approach also allows one to handle sequences with inherent cyclical patterns and process object relationships in the correct sequential order. Therefore, it can effectively capture periodic and overlapping relationships while minimizing information loss. The extensive experiments on the AeroEye dataset demonstrate the effectiveness of the proposed CYCLO model, demonstrating its potential to perform scene understanding on drone videos. Finally, the CYCLO method consistently achieves State-of-the-Art (SOTA) results on two in-the-wild scene graph generation benchmarks, i.e., PVSG and ASPIRe.
HIG: Hierarchical Interlacement Graph Approach to Scene Graph Generation in Video Understanding
Dec 05, 2023Visual interactivity understanding within visual scenes presents a significant challenge in computer vision. Existing methods focus on complex interactivities while leveraging a simple relationship model. These methods, however, struggle with a diversity of appearance, situation, position, interaction, and relation in videos. This limitation hinders the ability to fully comprehend the interplay within the complex visual dynamics of subjects. In this paper, we delve into interactivities understanding within visual content by deriving scene graph representations from dense interactivities among humans and objects. To achieve this goal, we first present a new dataset containing Appearance-Situation-Position-Interaction-Relation predicates, named ASPIRe, offering an extensive collection of videos marked by a wide range of interactivities. Then, we propose a new approach named Hierarchical Interlacement Graph (HIG), which leverages a unified layer and graph within a hierarchical structure to provide deep insights into scene changes across five distinct tasks. Our approach demonstrates superior performance to other methods through extensive experiments conducted in various scenarios.
REACT: Recognize Every Action Everywhere All At Once
Nov 27, 2023Group Activity Recognition (GAR) is a fundamental problem in computer vision, with diverse applications in sports video analysis, video surveillance, and social scene understanding. Unlike conventional action recognition, GAR aims to classify the actions of a group of individuals as a whole, requiring a deep understanding of their interactions and spatiotemporal relationships. To address the challenges in GAR, we present REACT (\textbf{R}ecognize \textbf{E}very \textbf{Act}ion Everywhere All At Once), a novel architecture inspired by the transformer encoder-decoder model explicitly designed to model complex contextual relationships within videos, including multi-modality and spatio-temporal features. Our architecture features a cutting-edge Vision-Language Encoder block for integrated temporal, spatial, and multi-modal interaction modeling. This component efficiently encodes spatiotemporal interactions, even with sparsely sampled frames, and recovers essential local information. Our Action Decoder Block refines the joint understanding of text and video data, allowing us to precisely retrieve bounding boxes, enhancing the link between semantics and visual reality. At the core, our Actor Fusion Block orchestrates a fusion of actor-specific data and textual features, striking a balance between specificity and context. Our method outperforms state-of-the-art GAR approaches in extensive experiments, demonstrating superior accuracy in recognizing and understanding group activities. Our architecture's potential extends to diverse real-world applications, offering empirical evidence of its performance gains. This work significantly advances the field of group activity recognition, providing a robust framework for nuanced scene comprehension.
UTOPIA: Unconstrained Tracking Objects without Preliminary Examination via Cross-Domain Adaptation
Jun 16, 2023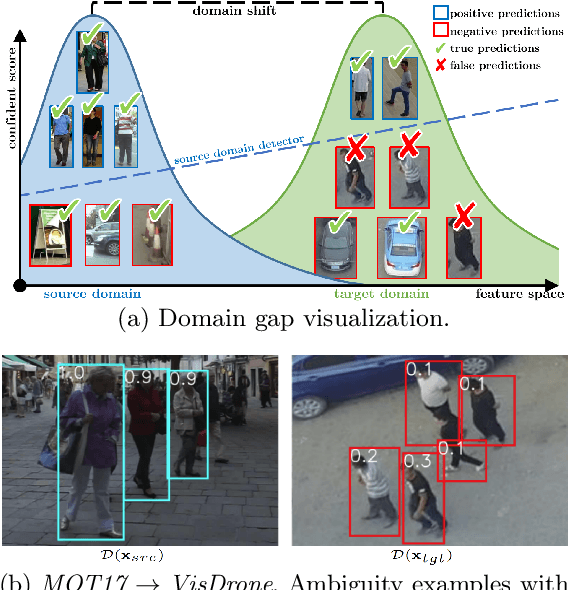

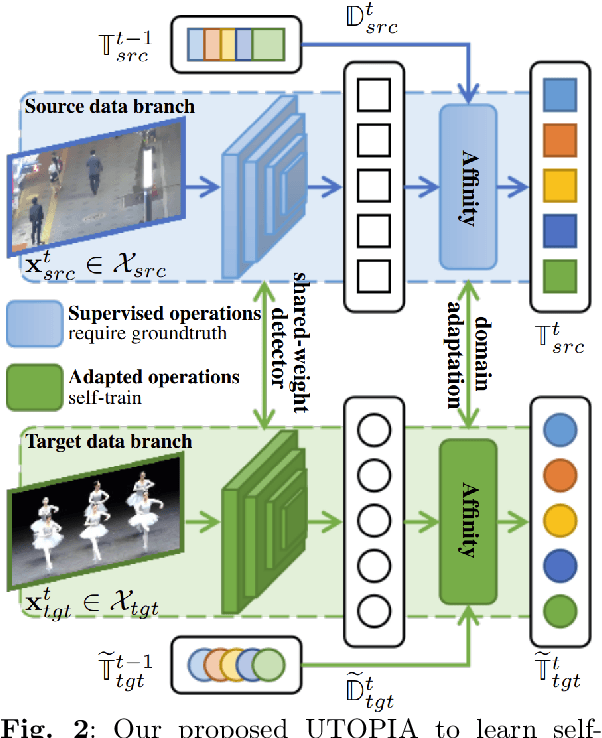
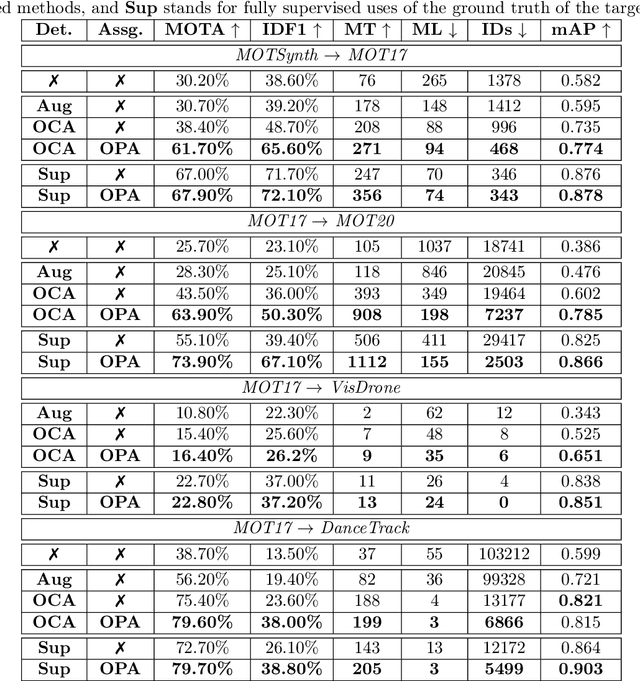
Multiple Object Tracking (MOT) aims to find bounding boxes and identities of targeted objects in consecutive video frames. While fully-supervised MOT methods have achieved high accuracy on existing datasets, they cannot generalize well on a newly obtained dataset or a new unseen domain. In this work, we first address the MOT problem from the cross-domain point of view, imitating the process of new data acquisition in practice. Then, a new cross-domain MOT adaptation from existing datasets is proposed without any pre-defined human knowledge in understanding and modeling objects. It can also learn and update itself from the target data feedback. The intensive experiments are designed on four challenging settings, including MOTSynth to MOT17, MOT17 to MOT20, MOT17 to VisDrone, and MOT17 to DanceTrack. We then prove the adaptability of the proposed self-supervised learning strategy. The experiments also show superior performance on tracking metrics MOTA and IDF1, compared to fully supervised, unsupervised, and self-supervised state-of-the-art methods.
Z-GMOT: Zero-shot Generic Multiple Object Tracking
May 28, 2023Despite the significant progress made in recent years, Multi-Object Tracking (MOT) approaches still suffer from several limitations, including their reliance on prior knowledge of tracking targets, which necessitates the costly annotation of large labeled datasets. As a result, existing MOT methods are limited to a small set of predefined categories, and they struggle with unseen objects in the real world. To address these issues, Generic Multiple Object Tracking (GMOT) has been proposed, which requires less prior information about the targets. However, all existing GMOT approaches follow a one-shot paradigm, relying mainly on the initial bounding box and thus struggling to handle variants e.g., viewpoint, lighting, occlusion, scale, and etc. In this paper, we introduce a novel approach to address the limitations of existing MOT and GMOT methods. Specifically, we propose a zero-shot GMOT (Z-GMOT) algorithm that can track never-seen object categories with zero training examples, without the need for predefined categories or an initial bounding box. To achieve this, we propose iGLIP, an improved version of Grounded language-image pretraining (GLIP), which can detect unseen objects while minimizing false positives. We evaluate our Z-GMOT thoroughly on the GMOT-40 dataset, AnimalTrack testset, DanceTrack testset. The results of these evaluations demonstrate a significant improvement over existing methods. For instance, on the GMOT-40 dataset, the Z-GMOT outperforms one-shot GMOT with OC-SORT by 27.79 points HOTA and 44.37 points MOTA. On the AnimalTrack dataset, it surpasses fully-supervised methods with DeepSORT by 12.55 points HOTA and 8.97 points MOTA. To facilitate further research, we will make our code and models publicly available upon acceptance of this paper.
Type-to-Track: Retrieve Any Object via Prompt-based Tracking
May 22, 2023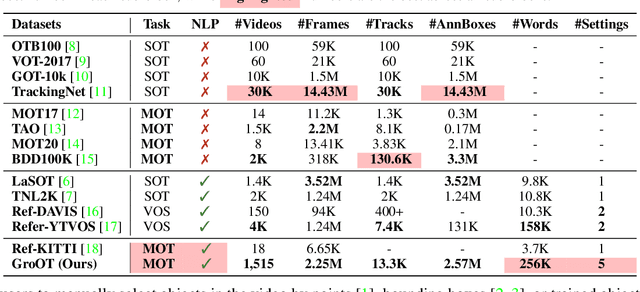
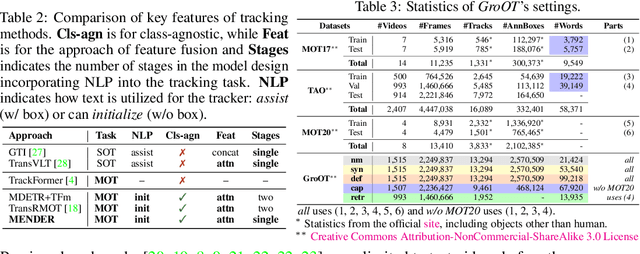

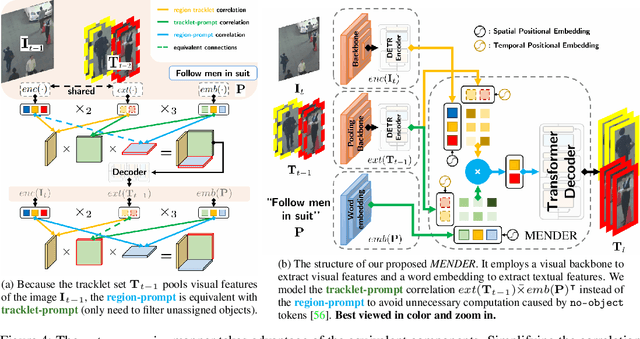
One of the recent trends in vision problems is to use natural language captions to describe the objects of interest. This approach can overcome some limitations of traditional methods that rely on bounding boxes or category annotations. This paper introduces a novel paradigm for Multiple Object Tracking called Type-to-Track, which allows users to track objects in videos by typing natural language descriptions. We present a new dataset for that Grounded Multiple Object Tracking task, called GroOT, that contains videos with various types of objects and their corresponding textual captions describing their appearance and action in detail. Additionally, we introduce two new evaluation protocols and formulate evaluation metrics specifically for this task. We develop a new efficient method that models a transformer-based eMbed-ENcoDE-extRact framework (MENDER) using the third-order tensor decomposition. The experiments in five scenarios show that our MENDER approach outperforms another two-stage design in terms of accuracy and efficiency, up to 14.7% accuracy and 4$\times$ speed faster.
SoGAR: Self-supervised Spatiotemporal Attention-based Social Group Activity Recognition
Apr 27, 2023



This paper introduces a novel approach to Social Group Activity Recognition (SoGAR) using Self-supervised Transformers network that can effectively utilize unlabeled video data. To extract spatio-temporal information, we create local and global views with varying frame rates. Our self-supervised objective ensures that features extracted from contrasting views of the same video are consistent across spatio-temporal domains. Our proposed approach is efficient in using transformer-based encoders for alleviating the weakly supervised setting of group activity recognition. By leveraging the benefits of transformer models, our approach can model long-term relationships along spatio-temporal dimensions. Our proposed SoGAR method achieves state-of-the-art results on three group activity recognition benchmarks, namely JRDB-PAR, NBA, and Volleyball datasets, surpassing the current state-of-the-art in terms of F1-score, MCA, and MPCA metrics.