 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTOPIA: Unconstrained Tracking Objects without Preliminary Examination via Cross-Domain Adaptation
Jun 16, 2023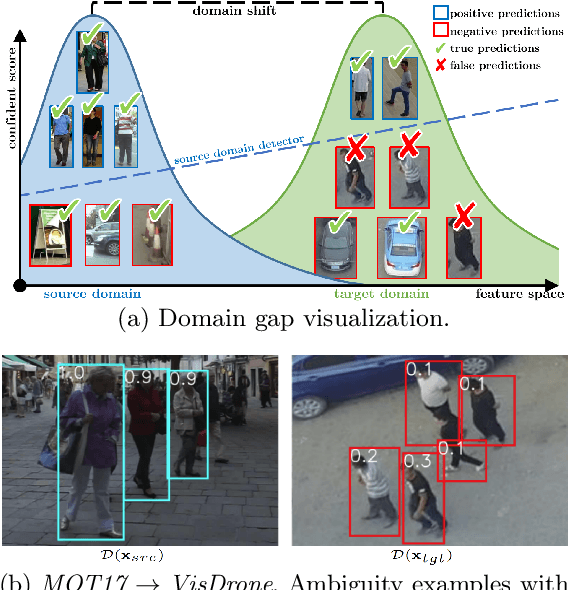

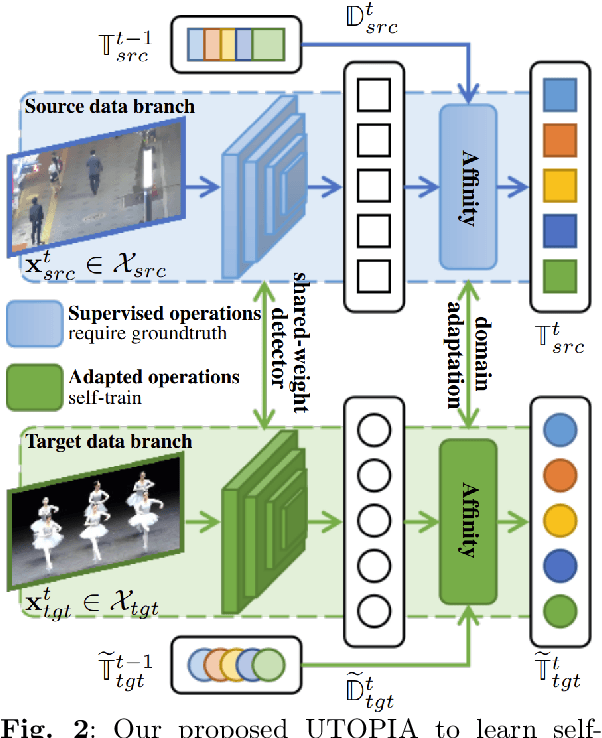
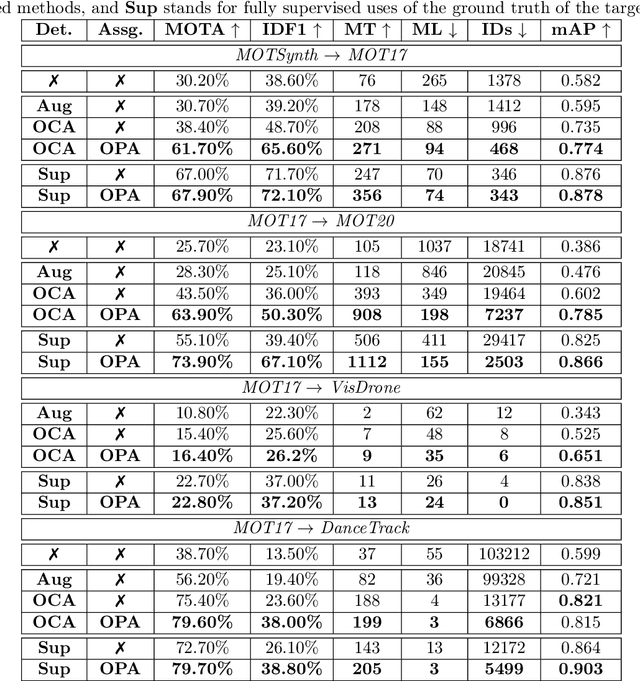
Multiple Object Tracking (MOT) aims to find bounding boxes and identities of targeted objects in consecutive video frames. While fully-supervised MOT methods have achieved high accuracy on existing datasets, they cannot generalize well on a newly obtained dataset or a new unseen domain. In this work, we first address the MOT problem from the cross-domain point of view, imitating the process of new data acquisition in practice. Then, a new cross-domain MOT adaptation from existing datasets is proposed without any pre-defined human knowledge in understanding and modeling objects. It can also learn and update itself from the target data feedback. The intensive experiments are designed on four challenging settings, including MOTSynth to MOT17, MOT17 to MOT20, MOT17 to VisDrone, and MOT17 to DanceTrack. We then prove the adaptability of the proposed self-supervised learning strategy. The experiments also show superior performance on tracking metrics MOTA and IDF1, compared to fully supervised, unsupervised, and self-supervised state-of-the-art methods.
Type-to-Track: Retrieve Any Object via Prompt-based Tracking
May 22, 2023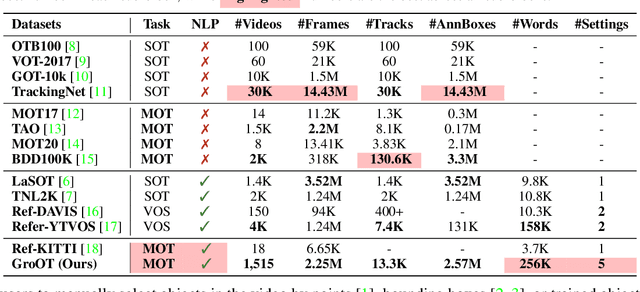
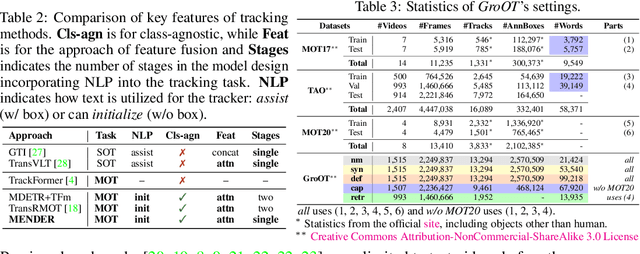

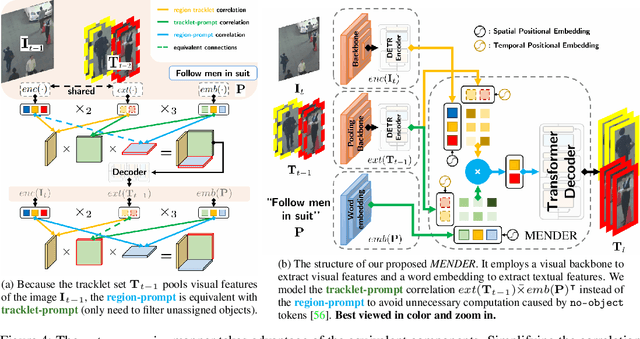
One of the recent trends in vision problems is to use natural language captions to describe the objects of interest. This approach can overcome some limitations of traditional methods that rely on bounding boxes or category annotations. This paper introduces a novel paradigm for Multiple Object Tracking called Type-to-Track, which allows users to track objects in videos by typing natural language descriptions. We present a new dataset for that Grounded Multiple Object Tracking task, called GroOT, that contains videos with various types of objects and their corresponding textual captions describing their appearance and action in detail. Additionally, we introduce two new evaluation protocols and formulate evaluation metrics specifically for this task. We develop a new efficient method that models a transformer-based eMbed-ENcoDE-extRact framework (MENDER) using the third-order tensor decomposition. The experiments in five scenarios show that our MENDER approach outperforms another two-stage design in terms of accuracy and efficiency, up to 14.7% accuracy and 4$\times$ speed faster.
Multi-Camera Multi-Object Tracking on the Move via Single-Stage Global Association Approach
Nov 17, 2022



The development of autonomous vehicles generates a tremendous demand for a low-cost solution with a complete set of camera sensors capturing the environment around the car. It is essential for object detection and tracking to address these new challenges in multi-camera settings. In order to address these challenges, this work introduces novel Single-Stage Global Association Tracking approaches to associate one or more detection from multi-cameras with tracked objects. These approaches aim to solve fragment-tracking issues caused by inconsistent 3D object detection. Moreover, our models also improve the detection accuracy of the standard vision-based 3D object detectors in the nuScenes detection challenge. The experimental results on the nuScenes dataset demonstrate the benefits of the proposed method by outperforming prior vision-based tracking methods in multi-camera settings.
Depth Perspective-aware Multiple Object Tracking
Jul 10, 2022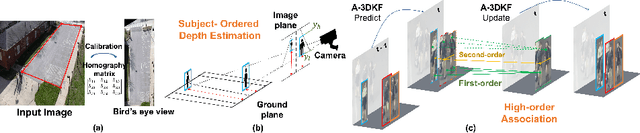
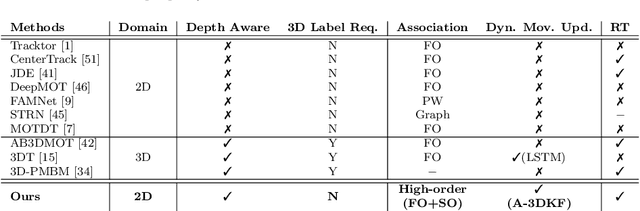
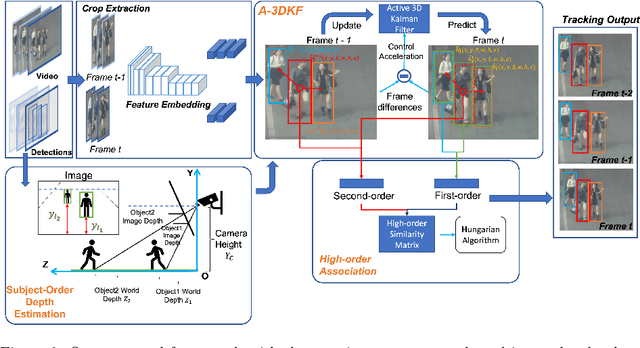
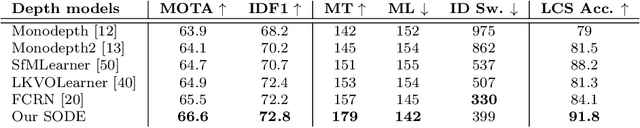
This paper aims to tackle Multiple Object Tracking (MOT), an important problem in computer vision but remains challenging due to many practical issues, especially occlusions. Indeed, we propose a new real-time Depth Perspective-aware Multiple Object Tracking (DP-MOT) approach to tackle the occlusion problem in MOT. A simple yet efficient Subject-Ordered Depth Estimation (SODE) is first proposed to automatically order the depth positions of detected subjects in a 2D scene in an unsupervised manner. Using the output from SODE, a new Active pseudo-3D Kalman filter, a simple but effective extension of Kalman filter with dynamic control variables, is then proposed to dynamically update the movement of objects. In addition, a new high-order association approach is presented in the data association step to incorporate first-order and second-order relationships between the detected objects. The proposed approach consistently achieves state-of-the-art performance compared to recent MOT methods on standard MOT benchmarks.
Multi-Camera Multiple 3D Object Tracking on the Move for Autonomous Vehicles
Apr 19, 2022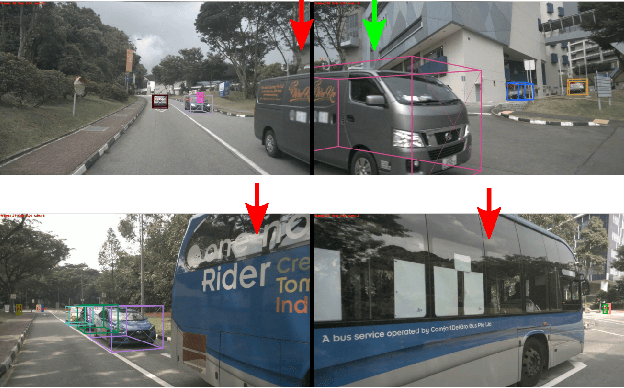
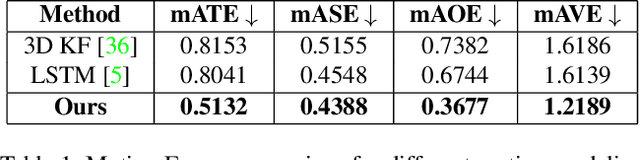
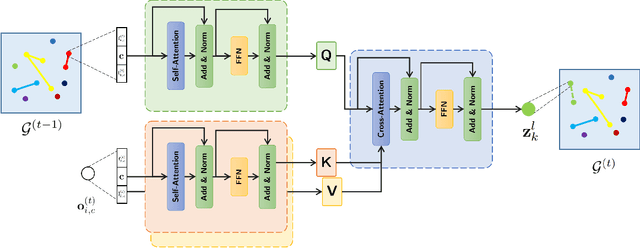
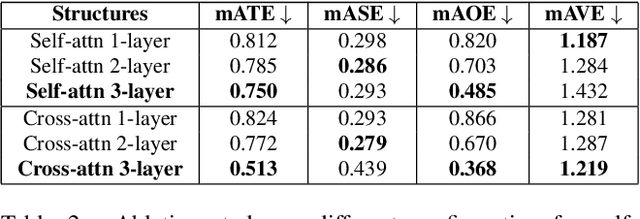
The development of autonomous vehicles provides an opportunity to have a complete set of camera sensors capturing the environment around the car. Thus, it is important for object detection and tracking to address new challenges, such as achieving consistent results across views of cameras. To address these challenges, this work presents a new Global Association Graph Model with Link Prediction approach to predict existing tracklets location and link detections with tracklets via cross-attention motion modeling and appearance re-identification. This approach aims at solving issues caused by inconsistent 3D object detection. Moreover, our model exploits to improve the detection accuracy of a standard 3D object detector in the nuScenes detection challenge. The experimental results on the nuScenes dataset demonstrate the benefits of the proposed method to produce SOTA performance on the existing vision-based tracking dataset.
DyGLIP: A Dynamic Graph Model with Link Prediction for Accurate Multi-Camera Multiple Object Tracking
Jun 12, 2021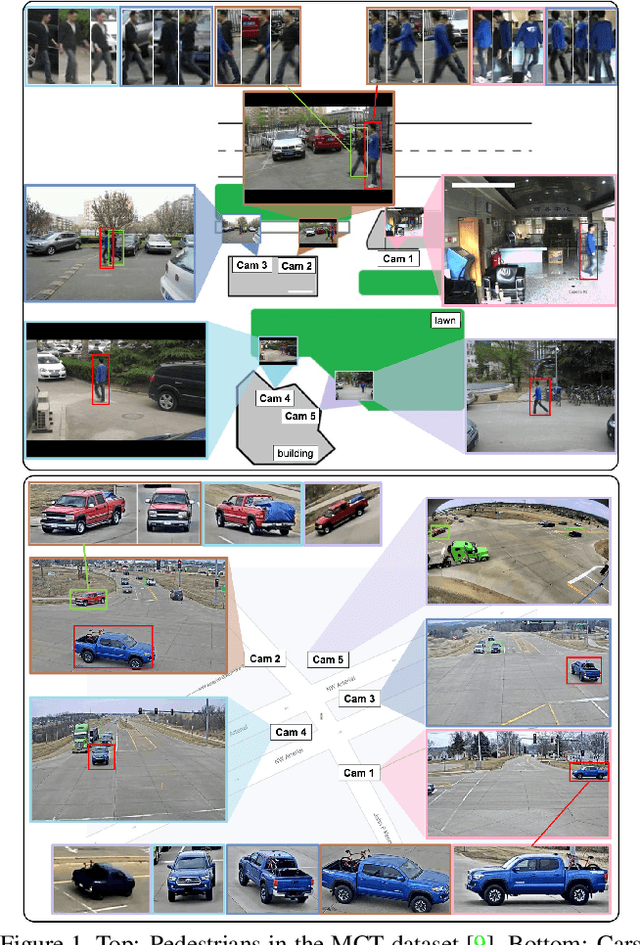
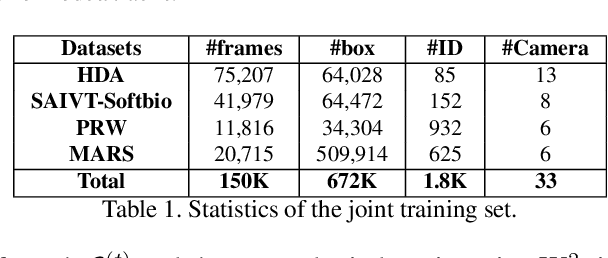
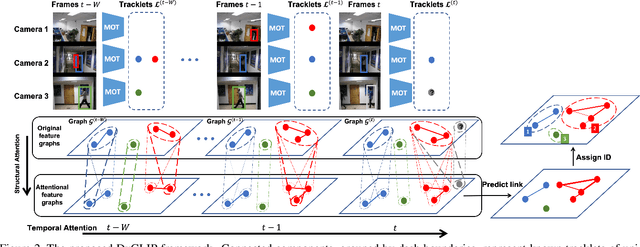
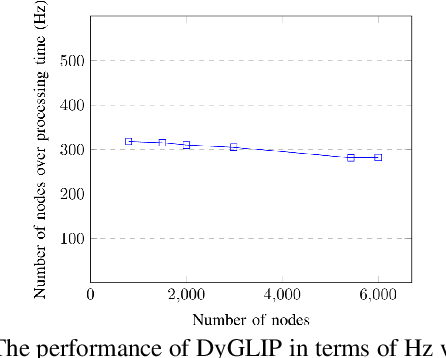
Multi-Camera Multiple Object Tracking (MC-MOT) is a significant computer vision problem due to its emerging applicability in several real-world applications. Despite a large number of existing works, solving the data association problem in any MC-MOT pipeline is arguably one of the most challenging tasks. Developing a robust MC-MOT system, however, is still highly challenging due to many practical issues such as inconsistent lighting conditions, varying object movement patterns, or the trajectory occlusions of the objects between the cameras. To address these problems, this work, therefore, proposes a new Dynamic Graph Model with Link Prediction (DyGLIP) approach to solve the data association task. Compared to existing methods, our new model offers several advantages, including better feature representations and the ability to recover from lost tracks during camera transitions. Moreover, our model works gracefully regardless of the overlapping ratios between the cameras. Experimental results show that we outperform existing MC-MOT algorithms by a large margin on several practical datasets. Notably, our model works favorably on online settings but can be extended to an incremental approach for large-scale datasets.
A Multi-task Contextual Atrous Residual Network for Brain Tumor Detection & Segmentation
Dec 03, 2020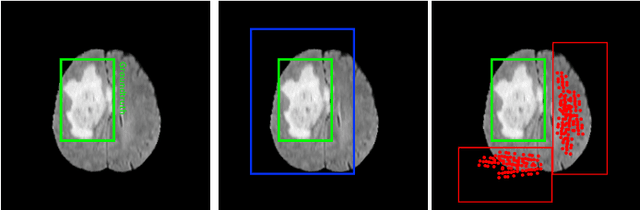
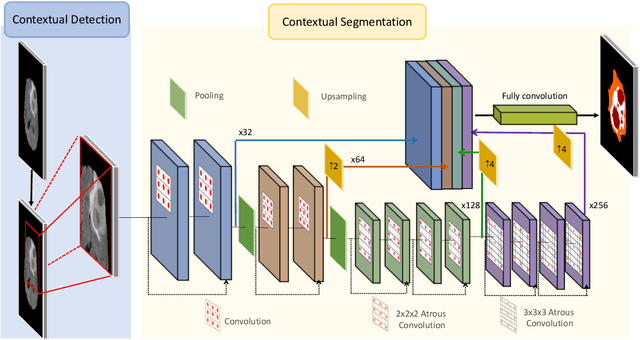
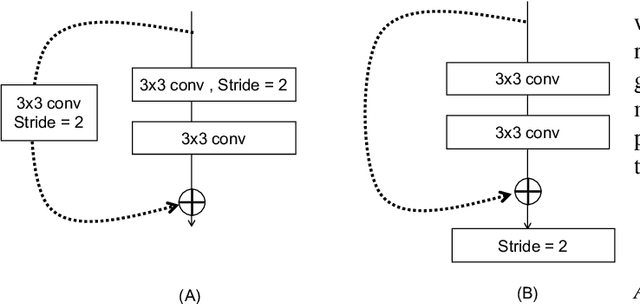
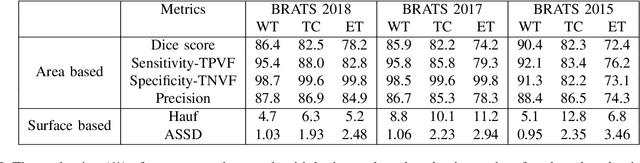
In recent years, deep neural networks have achieved state-of-the-art performance in a variety of recognition and segmentation tasks in medical imaging including brain tumor segmentation. We investigate that segmenting a brain tumor is facing to the imbalanced data problem where the number of pixels belonging to the background class (non tumor pixel) is much larger than the number of pixels belonging to the foreground class (tumor pixel). To address this problem, we propose a multi-task network which is formed as a cascaded structure. Our model consists of two targets, i.e., (i) effectively differentiate the brain tumor regions and (ii) estimate the brain tumor mask. The first objective is performed by our proposed contextual brain tumor detection network, which plays a role of an attention gate and focuses on the region around brain tumor only while ignoring the far neighbor background which is less correlated to the tumor. The second objective is built upon a 3D atrous residual network and under an encode-decode network in order to effectively segment both large and small objects (brain tumor). Our 3D atrous residual network is designed with a skip connection to enables the gradient from the deep layers to be directly propagated to shallow layers, thus, features of different depths are preserved and used for refining each other. In order to incorporate larger contextual information from volume MRI data, our network utilizes the 3D atrous convolution with various kernel sizes, which enlarges the receptive field of filters. Our proposed network has been evaluated on various datasets including BRATS2015, BRATS2017 and BRATS2018 datasets with both validation set and testing set. Our performance has been benchmarked by both region-based metrics and surface-based metrics. We also have conducted comparisons against state-of-the-art approaches.
Beyond Disentangled Representations: An Attentive Angular Distillation Approach to Large-scale Lightweight Age-Invariant Face Recognition
Apr 09, 2020
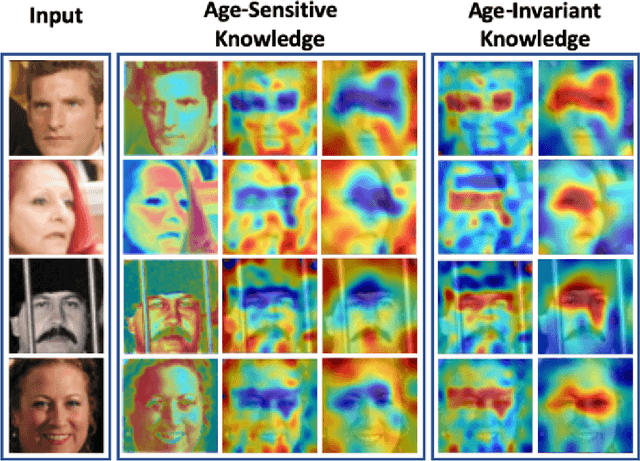
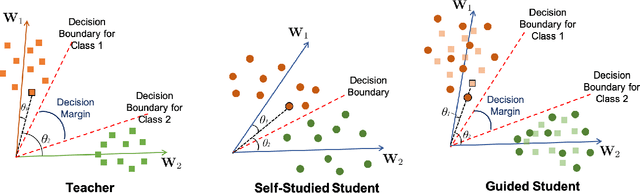
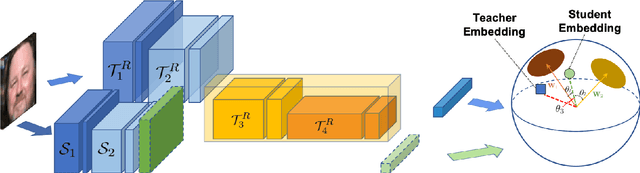
Disentangled representations have been commonly adopted to Age-invariant Face Recognition (AiFR) tasks. However, these methods have reached some limitations with (1) the requirement of large-scale face recognition (FR) training data with age labels, which is limited in practice; (2) heavy deep network architecture for high performance; and (3) their evaluations are usually taken place on age-related face databases while neglecting the standard large-scale FR databases to guarantee its robustness. This work presents a novel Attentive Angular Distillation (AAD) approach to Large-scale Lightweight AiFR that overcomes these limitations. Given two high-performance heavy networks as teachers with different specialized knowledge, AAD introduces a learning paradigm to efficiently distill the age-invariant attentive and angular knowledge from those teachers to a lightweight student network making it more powerful with higher FR accuracy and robust against age factor. Consequently, AAD approach is able to take the advantages of both FR datasets with and without age labels to train an AiFR model. Far apart from prior distillation methods mainly focusing on accuracy and compression ratios in closed-set problems, our AAD aims to solve the open-set problem, i.e. large-scale face recognition. Evaluations on LFW, IJB-B and IJB-C Janus, AgeDB and MegaFace-FGNet with one million distractors have demonstrated the efficiency of the proposed approach. This work also presents a new longitudinal face aging (LogiFace) database for further studies in age-related facial problems in future.
Vec2Face: Unveil Human Faces from their Blackbox Features in Face Recognition
Mar 16, 2020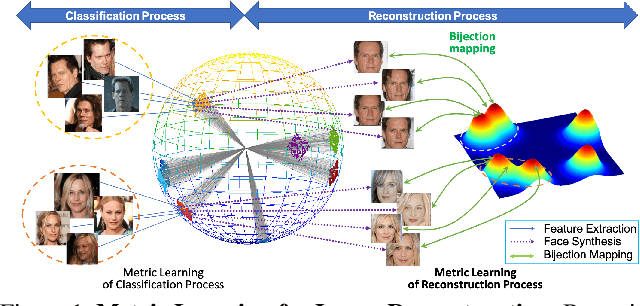

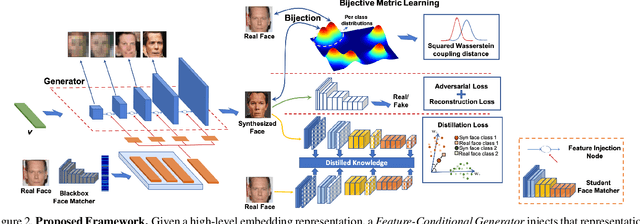
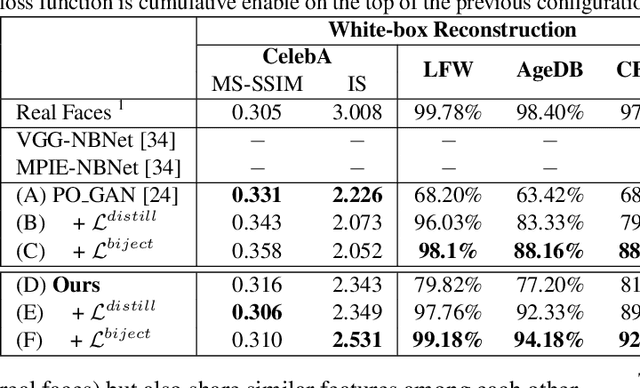
Unveiling face images of a subject given his/her high-level representations extracted from a blackbox Face Recognition engine is extremely challenging. It is because the limitations of accessible information from that engine including its structure and uninterpretable extracted features. This paper presents a novel generative structure with Bijective Metric Learning, namely Bijective Generative Adversarial Networks in a Distillation framework (DiBiGAN), for synthesizing faces of an identity given that person's features. In order to effectively address this problem, this work firstly introduces a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. Secondly, a distillation process is introduced to maximize the information exploited from the blackbox face recognition engine. Then a Feature-Conditional Generator Structure with Exponential Weighting Strategy is presented for a more robust generator that can synthesize realistic faces with ID preservation. Results on several benchmarking datasets including CelebA, LFW, AgeDB, CFP-FP against matching engines have demonstrated the effectiveness of DiBiGAN on both image realism and ID preservation properties.
ShrinkTeaNet: Million-scale Lightweight Face Recognition via Shrinking Teacher-Student Networks
May 25, 2019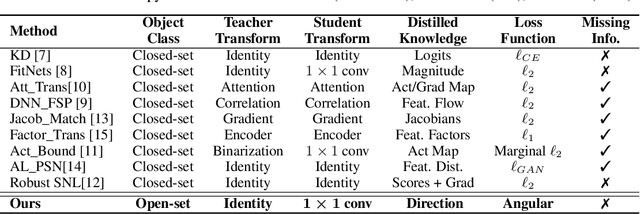
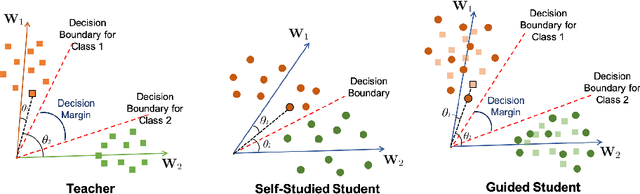
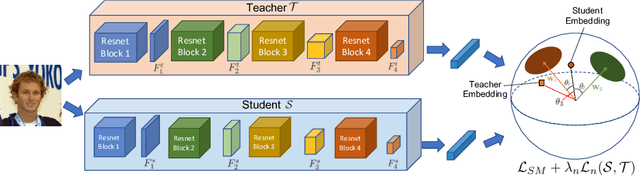
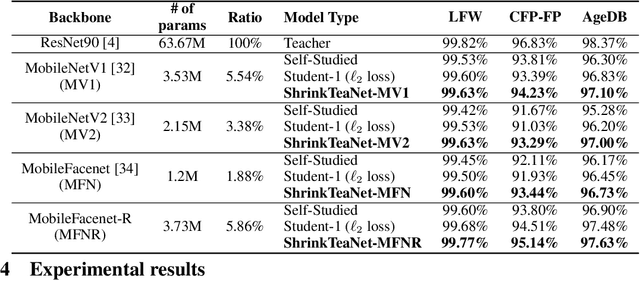
Large-scale face recognition in-the-wild has been recently achieved matured performance in many real work applications. However, such systems are built on GPU platforms and mostly deploy heavy deep network architectures. Given a high-performance heavy network as a teacher, this work presents a simple and elegant teacher-student learning paradigm, namely ShrinkTeaNet, to train a portable student network that has significantly fewer parameters and competitive accuracy against the teacher network. Far apart from prior teacher-student frameworks mainly focusing on accuracy and compression ratios in closed-set problems, our proposed teacher-student network is proved to be more robust against open-set problem, i.e. large-scale face recognition. In addition, this work introduces a novel Angular Distillation Loss for distilling the feature direction and the sample distributions of the teacher's hypersphere to its student. Then ShrinkTeaNet framework can efficiently guide the student's learning process with the teacher's knowledge presented in both intermediate and last stages of the feature embedding. Evaluations on LFW, CFP-FP, AgeDB, IJB-B and IJB-C Janus, and MegaFace with one million distractors have demonstrated the efficiency of the proposed approach to learn robust student networks which have satisfying accuracy and compact sizes. Our ShrinkTeaNet is able to support the light-weight architecture achieving high performance with 99.77% on LFW and 95.64% on large-scale Megaface protocols.