 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoNets: Orthogonal Channel Attention Networks
Nov 07, 2023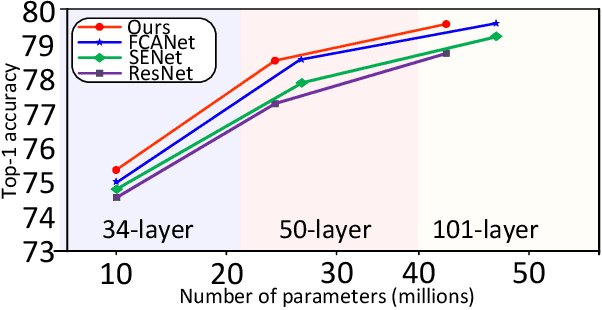
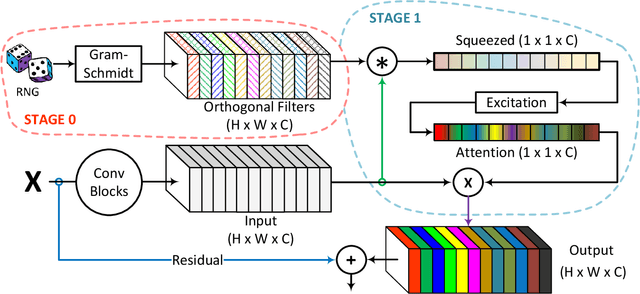
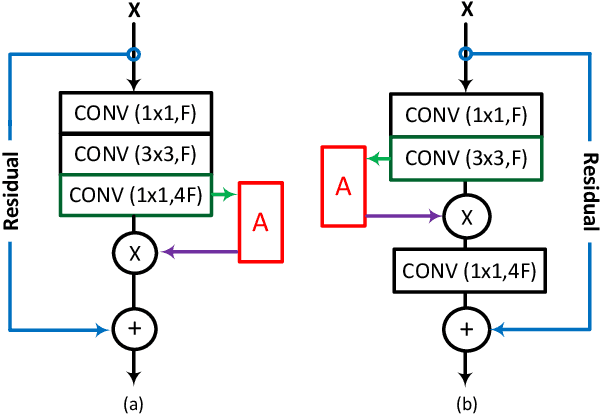
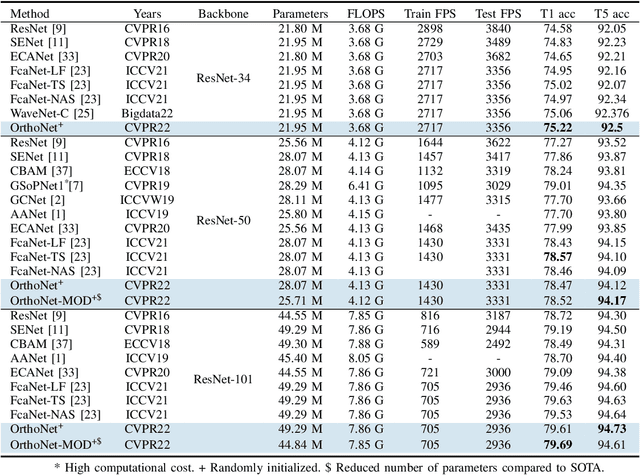
Designing an effective channel attention mechanism implores one to find a lossy-compression method allowing for optimal feature representation. Despite recent progress in the area, it remains an open problem. FcaNet, the current state-of-the-art channel attention mechanism, attempted to find such an information-rich compression using Discrete Cosine Transforms (DCTs). One drawback of FcaNet is that there is no natural choice of the DCT frequencies. To circumvent this issue, FcaNet experimented on ImageNet to find optimal frequencies. We hypothesize that the choice of frequency plays only a supporting role and the primary driving force for the effectiveness of their attention filters is the orthogonality of the DCT kernels. To test this hypothesis, we construct an attention mechanism using randomly initialized orthogonal filters. Integrating this mechanism into ResNet, we create OrthoNet. We compare OrthoNet to FcaNet (and other attention mechanisms) on Birds, MS-COCO, and Places356 and show superior performance. On the ImageNet dataset, our method competes with or surpasses the current state-of-the-art. Our results imply that an optimal choice of filter is elusive and generalization can be achieved with a sufficiently large number of orthogonal filters. We further investigate other general principles for implementing channel attention, such as its position in the network and channel groupings. Our code is publicly available at https://github.com/hady1011/OrthoNets/
* IEEE BigData 2023
UTOPIA: Unconstrained Tracking Objects without Preliminary Examination via Cross-Domain Adaptation
Jun 16, 2023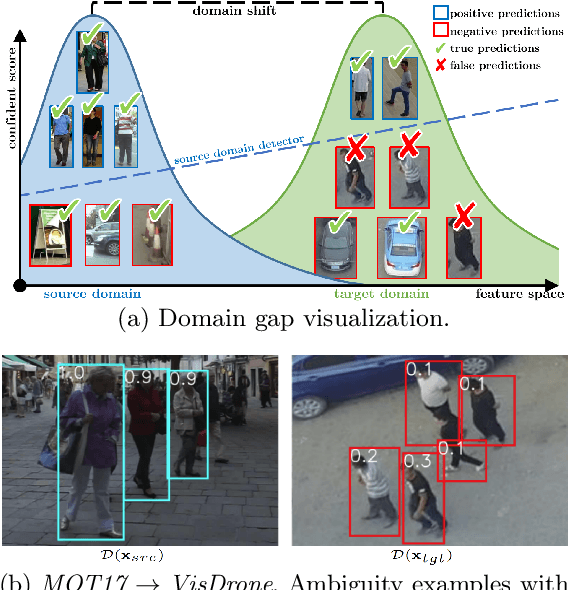

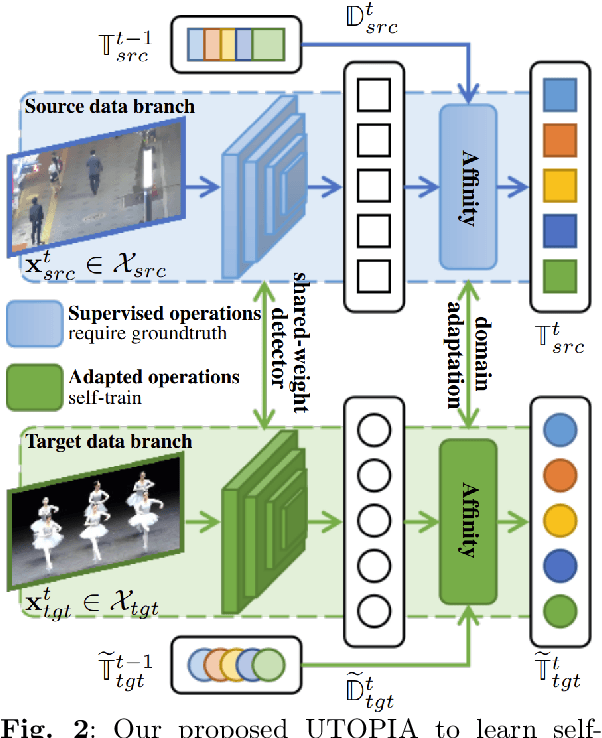
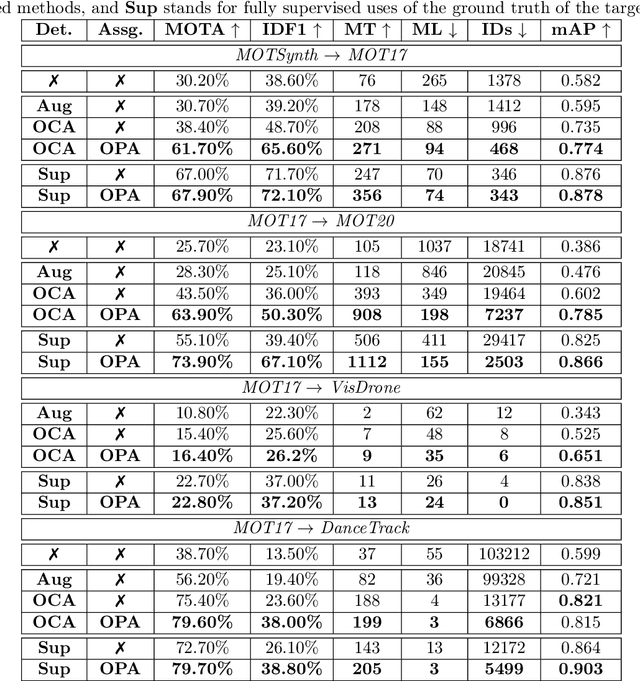
Multiple Object Tracking (MOT) aims to find bounding boxes and identities of targeted objects in consecutive video frames. While fully-supervised MOT methods have achieved high accuracy on existing datasets, they cannot generalize well on a newly obtained dataset or a new unseen domain. In this work, we first address the MOT problem from the cross-domain point of view, imitating the process of new data acquisition in practice. Then, a new cross-domain MOT adaptation from existing datasets is proposed without any pre-defined human knowledge in understanding and modeling objects. It can also learn and update itself from the target data feedback. The intensive experiments are designed on four challenging settings, including MOTSynth to MOT17, MOT17 to MOT20, MOT17 to VisDrone, and MOT17 to DanceTrack. We then prove the adaptability of the proposed self-supervised learning strategy. The experiments also show superior performance on tracking metrics MOTA and IDF1, compared to fully supervised, unsupervised, and self-supervised state-of-the-art methods.