 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectrical Load Forecasting over Multihop Smart Metering Networks with Federated Learning
Feb 24, 2025Electric load forecasting is essential for power management and stability in smart grids. This is mainly achieved via advanced metering infrastructure, where smart meters (SMs) record household energy data. Traditional machine learning (ML) methods are often employed for load forecasting but require data sharing which raises data privacy concerns. Federated learning (FL) can address this issue by running distributed ML models at local SMs without data exchange. However, current FL-based approaches struggle to achieve efficient load forecasting due to imbalanced data distribution across heterogeneous SMs. This paper presents a novel personalized federated learning (PFL) method for high-quality load forecasting in metering networks. A meta-learning-based strategy is developed to address data heterogeneity at local SMs in the collaborative training of local load forecasting models. Moreover, to minimize the load forecasting delays in our PFL model, we study a new latency optimization problem based on optimal resource allocation at SMs. A theoretical convergence analysis is also conducted to provide insights into FL design for federated load forecasting. Extensive simulations from real-world datasets show that our method outperforms existing approaches in terms of better load forecasting and reduced operational latency costs.
Quantum-Brain: Quantum-Inspired Neural Network Approach to Vision-Brain Understanding
Nov 20, 2024



Vision-brain understanding aims to extract semantic information about brain signals from human perceptions. Existing deep learning methods for vision-brain understanding are usually introduced in a traditional learning paradigm missing the ability to learn the connectivities between brain regions. Meanwhile, the quantum computing theory offers a new paradigm for designing deep learning models. Motivated by the connectivities in the brain signals and the entanglement properties in quantum computing, we propose a novel Quantum-Brain approach, a quantum-inspired neural network, to tackle the vision-brain understanding problem. To compute the connectivity between areas in brain signals, we introduce a new Quantum-Inspired Voxel-Controlling module to learn the impact of a brain voxel on others represented in the Hilbert space. To effectively learn connectivity, a novel Phase-Shifting module is presented to calibrate the value of the brain signals. Finally, we introduce a new Measurement-like Projection module to present the connectivity information from the Hilbert space into the feature space. The proposed approach can learn to find the connectivities between fMRI voxels and enhance the semantic information obtained from human perceptions. Our experimental results on the Natural Scene Dataset benchmarks illustrate the effectiveness of the proposed method with Top-1 accuracies of 95.1% and 95.6% on image and brain retrieval tasks and an Inception score of 95.3% on fMRI-to-image reconstruction task. Our proposed quantum-inspired network brings a potential paradigm to solving the vision-brain problems via the quantum computing theory.
Hierarchical Quantum Control Gates for Functional MRI Understanding
Aug 07, 2024



Quantum computing has emerged as a powerful tool for solving complex problems intractable for classical computers, particularly in popular fields such as cryptography, optimization, and neurocomputing. In this paper, we present a new quantum-based approach named the Hierarchical Quantum Control Gates (HQCG) method for efficient understanding of Functional Magnetic Resonance Imaging (fMRI) data. This approach includes two novel modules: the Local Quantum Control Gate (LQCG) and the Global Quantum Control Gate (GQCG), which are designed to extract local and global features of fMRI signals, respectively. Our method operates end-to-end on a quantum machine, leveraging quantum mechanics to learn patterns within extremely high-dimensional fMRI signals, such as 30,000 samples which is a challenge for classical computers. Empirical results demonstrate that our approach significantly outperforms classical methods. Additionally, we found that the proposed quantum model is more stable and less prone to overfitting than the classical methods.
Diffusion-Inspired Quantum Noise Mitigation in Parameterized Quantum Circuits
Jun 02, 2024



Parameterized Quantum Circuits (PQCs) have been acknowledged as a leading strategy to utilize near-term quantum advantages in multiple problems, including machine learning and combinatorial optimization. When applied to specific tasks, the parameters in the quantum circuits are trained to minimize the target function. Although there have been comprehensive studies to improve the performance of the PQCs on practical tasks, the errors caused by the quantum noise downgrade the performance when running on real quantum computers. In particular, when the quantum state is transformed through multiple quantum circuit layers, the effect of the quantum noise happens cumulatively and becomes closer to the maximally mixed state or complete noise. This paper studies the relationship between the quantum noise and the diffusion model. Then, we propose a novel diffusion-inspired learning approach to mitigate the quantum noise in the PQCs and reduce the error for specific tasks. Through our experiments, we illustrate the efficiency of the learning strategy and achieve state-of-the-art performance on classification tasks in the quantum noise scenarios.
QClusformer: A Quantum Transformer-based Framework for Unsupervised Visual Clustering
May 30, 2024



Unsupervised vision clustering, a cornerstone in computer vision, has been studied for decades, yielding significant outcomes across numerous vision tasks. However, these algorithms involve substantial computational demands when confronted with vast amounts of unlabeled data. Conversely, Quantum computing holds promise in expediting unsupervised algorithms when handling large-scale databases. In this study, we introduce QClusformer, a pioneering Transformer-based framework leveraging Quantum machines to tackle unsupervised vision clustering challenges. Specifically, we design the Transformer architecture, including the self-attention module and transformer blocks, from a Quantum perspective to enable execution on Quantum hardware. In addition, we present QClusformer, a variant based on the Transformer architecture, tailored for unsupervised vision clustering tasks. By integrating these elements into an end-to-end framework, QClusformer consistently outperforms previous methods running on classical computers. Empirical evaluations across diverse benchmarks, including MS-Celeb-1M and DeepFashion, underscore the superior performance of QClusformer compared to state-of-the-art methods.
Quantum Visual Feature Encoding Revisited
May 30, 2024



Although quantum machine learning has been introduced for a while, its applications in computer vision are still limited. This paper, therefore, revisits the quantum visual encoding strategies, the initial step in quantum machine learning. Investigating the root cause, we uncover that the existing quantum encoding design fails to ensure information preservation of the visual features after the encoding process, thus complicating the learning process of the quantum machine learning models. In particular, the problem, termed "Quantum Information Gap" (QIG), leads to a gap of information between classical and corresponding quantum features. We provide theoretical proof and practical demonstrations of that found and underscore the significance of QIG, as it directly impacts the performance of quantum machine learning algorithms. To tackle this challenge, we introduce a simple but efficient new loss function named Quantum Information Preserving (QIP) to minimize this gap, resulting in enhanced performance of quantum machine learning algorithms. Extensive experiments validate the effectiveness of our approach, showcasing superior performance compared to current methodologies and consistently achieving state-of-the-art results in quantum modeling.
BRACTIVE: A Brain Activation Approach to Human Visual Brain Learning
May 29, 2024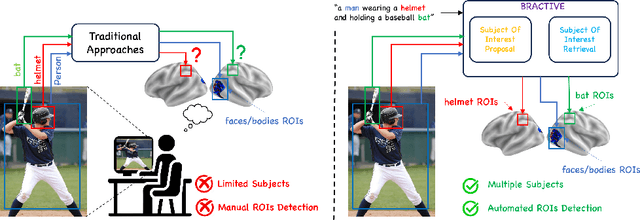
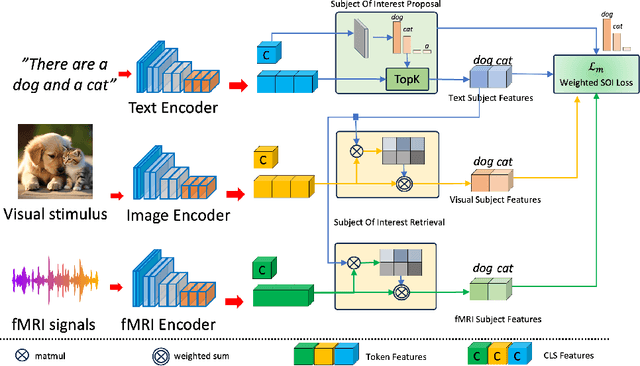

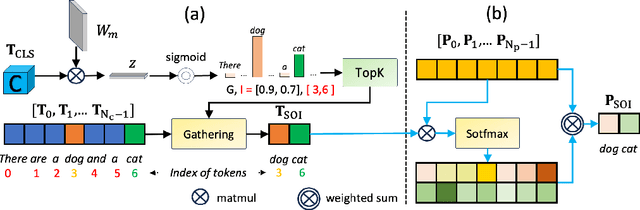
The human brain is a highly efficient processing unit, and understanding how it works can inspire new algorithms and architectures in machine learning. In this work, we introduce a novel framework named Brain Activation Network (BRACTIVE), a transformer-based approach to studying the human visual brain. The main objective of BRACTIVE is to align the visual features of subjects with corresponding brain representations via fMRI signals. It allows us to identify the brain's Regions of Interest (ROI) of the subjects. Unlike previous brain research methods, which can only identify ROIs for one subject at a time and are limited by the number of subjects, BRACTIVE automatically extends this identification to multiple subjects and ROIs. Our experiments demonstrate that BRACTIVE effectively identifies person-specific regions of interest, such as face and body-selective areas, aligning with neuroscience findings and indicating potential applicability to various object categories. More importantly, we found that leveraging human visual brain activity to guide deep neural networks enhances performance across various benchmarks. It encourages the potential of BRACTIVE in both neuroscience and machine intelligence studies.
Brainformer: Modeling MRI Brain Functions to Machine Vision
Nov 30, 2023



"Perception is reality". Human perception plays a vital role in forming beliefs and understanding reality. Exploring how the human brain works in the visual system facilitates bridging the gap between human visual perception and computer vision models. However, neuroscientists study the brain via Neuroimaging, i.e., Functional Magnetic Resonance Imaging (fMRI), to discover the brain's functions. These approaches face interpretation challenges where fMRI data can be complex and require expertise. Therefore, neuroscientists make inferences about cognitive processes based on patterns of brain activities, which can lead to potential misinterpretation or limited functional understanding. In this work, we first present a simple yet effective Brainformer approach, a novel Transformer-based framework, to analyze the patterns of fMRI in the human perception system from the machine learning perspective. Secondly, we introduce a novel mechanism incorporating fMRI, which represents the human brain activities, as the supervision for the machine vision model. This work also introduces a novel perspective on transferring knowledge from human perception to neural networks. Through our experiments, we demonstrated that by leveraging fMRI information, the machine vision model can achieve potential results compared to the current State-of-the-art methods in various image recognition tasks.
Quantum Vision Clustering
Sep 18, 2023Unsupervised visual clustering has recently received considerable attention. It aims to explain distributions of unlabeled visual images by clustering them via a parameterized appearance model. From a different perspective, the clustering algorithms can be treated as assignment problems, often NP-hard. They can be solved precisely for small instances on current hardware. Adiabatic quantum computing (AQC) offers a solution, as it can soon provide a considerable speedup on a range of NP-hard optimization problems. However, current clustering formulations are unsuitable for quantum computing due to their scaling properties. Consequently, in this work, we propose the first clustering formulation designed to be solved with AQC. We employ an Ising model representing the quantum mechanical system implemented on the AQC. Our approach is competitive compared to state-of-the-art optimization-based approaches, even using of-the-shelf integer programming solvers. Finally, we demonstrate that our clustering problem is already solvable on the current generation of real quantum computers for small examples and analyze the properties of the measured solutions.
UTOPIA: Unconstrained Tracking Objects without Preliminary Examination via Cross-Domain Adaptation
Jun 16, 2023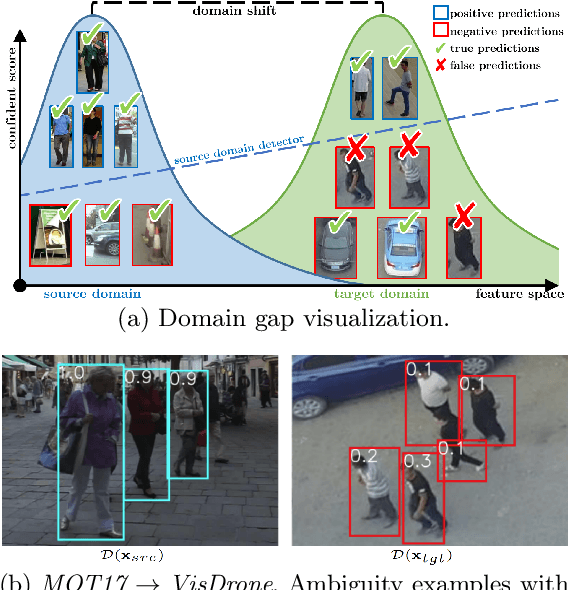

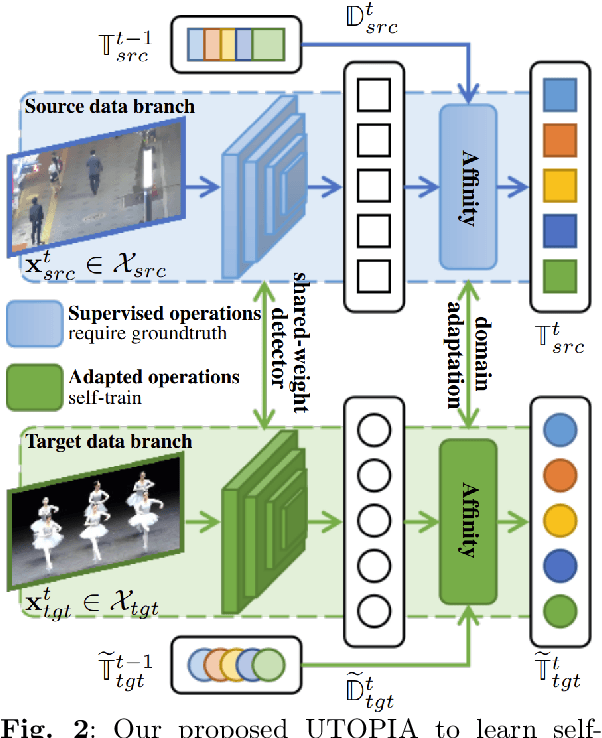
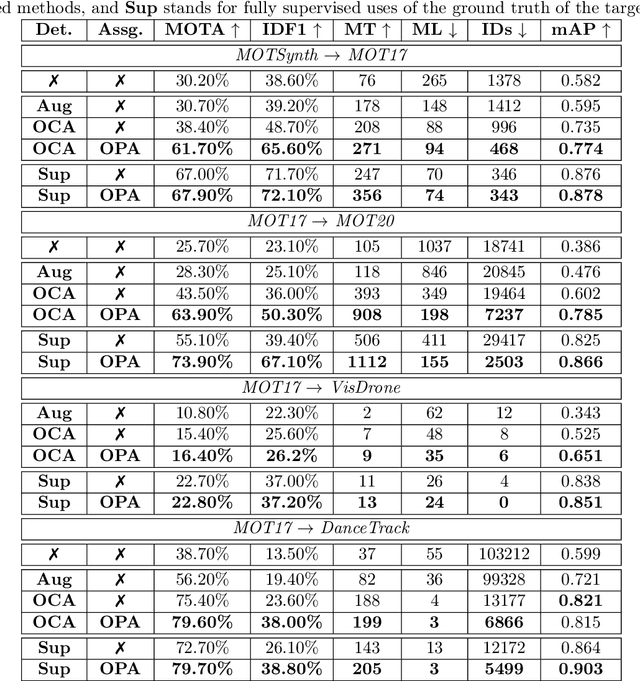
Multiple Object Tracking (MOT) aims to find bounding boxes and identities of targeted objects in consecutive video frames. While fully-supervised MOT methods have achieved high accuracy on existing datasets, they cannot generalize well on a newly obtained dataset or a new unseen domain. In this work, we first address the MOT problem from the cross-domain point of view, imitating the process of new data acquisition in practice. Then, a new cross-domain MOT adaptation from existing datasets is proposed without any pre-defined human knowledge in understanding and modeling objects. It can also learn and update itself from the target data feedback. The intensive experiments are designed on four challenging settings, including MOTSynth to MOT17, MOT17 to MOT20, MOT17 to VisDrone, and MOT17 to DanceTrack. We then prove the adaptability of the proposed self-supervised learning strategy. The experiments also show superior performance on tracking metrics MOTA and IDF1, compared to fully supervised, unsupervised, and self-supervised state-of-the-art methods.